






5种文本分类的方法(即使没有训练数据)

介绍
本文重点讨论来自Flipkart客户评论数据集的产品评论情感分析。
情感分析是自然语言处理(NLP)中的一项关键任务,旨在将文本分类为积极、消极或中性情感。它使企业能够从客户反馈中获得洞察。
我们的目标是探索和比较多种二元情感分类方法,评估它们的性能和计算效率。
这些方法从传统方法到利用嵌入和生成模型的先进技术不等。
一些方法需要标记数据,而有些方法则完全不需要。
目标
1. 数据集分析与预处理:
- • 探索 Flipkart 客户评价数据集并对其进行预处理,以创建二元分类任务。
- • 关注明确的情感极性(积极和消极),排除中性评价。
2. 方法探索:
- • 尝试多种文本分类方法,包括: a) 使用 TF-IDF 的逻辑回归 b) 使用 预训练嵌入 的逻辑回归
- • 使用嵌入和余弦相似度的 零样本分类。
- • 生成语言模型(例如,Flan-T5\)。
- • 针对评论分类微调的 特定任务情感模型。
3. 性能评估:
- • 使用标准分类指标评估模型,如 precision、recall、F1-score 和 accuracy。
- • 分析性能与计算效率之间的权衡。
为什么情感分析?
情感分析使企业能够:
- • 理解客户的意见和偏好。
- • 识别产品反馈中的趋势和问题。
- • 增强产品改进和客户满意度的决策能力。
该项目利用广泛的自然语言处理技术,展示如何将各种方法应用于情感分析,每种方法都针对特定的用例和资源限制进行调整。
方法概述
1. 使用 TF-IDF 的逻辑回归:
- • 一种简单而有效的基线,使用基于词频的特征进行分类。
2. 带有预训练嵌入的逻辑回归:
- • 利用高级嵌入模型,如
all-MiniLM-L6-v2,生成用于训练分类器的语义表示。
3. 零样本分类:
- • 通过利用文档和标签嵌入之间的余弦相似度,执行无需标记数据的分类。
4. 生成模型:
- • 探索生成语言模型,如
Flan-T5,它通过根据提示生成响应来对文本进行分类。
5. 任务特定情感模型:
- • 利用微调的情感模型,如
juliensimon/reviews-sentiment-analysis,以实现领域特定的性能。
结果概述
下表总结了本项目中每种方法所达到的准确性:

本项目突出了每种方法的优缺点,为将情感分析技术应用于实际数据集提供了全面的指南。
在我们开始之前
要获取完整代码,请访问我的 GitHub 作品集。
如果您在 Google Colab(或任何其他云平台)上运行此代码,请确保已安装所有必要的依赖项。
运行以下代码块以安装所需的包:
%%capture
!pip install datasets transformers sentence-transformers
导入:
import pandas as pd
import numpy as np
from tqdm import tqdm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
数据集概述
Flipkart 客户评论数据集由两个主要列组成:
- •
review: 客户关于产品提供的文本评论。 - •
rating: 客户给出的数字评分(星级),范围从 1 到 5\。
rating 列表示客户为产品分配的星级数量。较高的值表示更有利的评论。
标签创建
为了简化我们的分析,我们将根据 rating 创建一个新列 label:
- • 积极:如果
rating > 4(例如,5 星) - • 消极:如果
rating < 4(例如,1 或 2 星) - • 中立评分(3 星) 将被排除在此分析之外。
这个预处理步骤将帮助我们专注于评论中的明确情感极性(积极和消极)。
data = pd.read_csv('data.csv')
data = data[data["rating"]!=4]
data["label"] = data["rating"].apply(lambda x: 1 if x >= 4 else 0)
data["label"].value_counts()
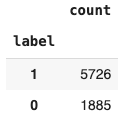
平衡数据集
为了这个例子的目的,我们将对正类进行下采样,以匹配负类的大小。
这确保了数据集的平衡,避免了由于类别不平衡导致的模型训练偏差。
这也确保了更快的计算时间,因为我们处理的数据量更少。
### Down-sample the positive class and combine with the negative class
data = pd.concat([
data[data["label"] == 1].sample(n=len(data[data["label"] == 0]),
random_state=1),
data[data["label"] == 0]
])
### Shuffle the resulting dataset
data = data.sample(frac=1, random_state=1).reset_index(drop=True)
数据划分
我们将数据分为80%的训练集和20%的测试集。
train = data[:int(0.8*len(data))]
test = data[int(0.8*len(data)):].reset_index(drop=True)
文本分类
1 . 使用 tf-idf 的逻辑回归
首先,在尝试任何复杂的方法之前,我们将为我们的二分类任务采用简单的逻辑回归。
为了将文本数据以数字形式表示,我们将使用 TF-IDF (词频-逆文档频率),这是一种流行的文本数据特征提取技术。
TF-IDF 衡量一个术语在文档中的重要性,相对于整个语料库,提供加权表示,增强独特和信息丰富的单词的影响,同时减少常见单词的权重。
为什么要从逻辑回归和 TF-IDF 开始?
- \1. 简单性和可解释性:
- • 逻辑回归简单易懂,易于解释,并提供了特征与标签之间关系的清晰洞察。
- • TF-IDF 提供了一种简单而强大的方式,通过强调重要术语并降低常见术语的权重,将文本以数字形式表示。
2. 基准性能:
- • 这种组合有助于建立一个稳固的基准,以评估未来改进的有效性,例如嵌入或 LLM。
3. 效率:
- • 逻辑回归和 TF-IDF 都是计算上轻量级的,非常适合较小的数据集和快速实验。
4. 经过验证的有效性:
- • 逻辑回归与 TF-IDF 配对在文本分类任务中表现良好,尤其是对于具有线性可分特征的数据集。
5. 迭代工作流程:
- • 从简单开始使我们能够高效地调试和优化管道,然后再引入嵌入或 LLM 等复杂性。
### Features and labels
X_train = train['review']
y_train = train['label']
X_test = test['review']
y_test = test['label']
### Convert text data into numerical features using TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer()
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
### Logistic Regression Model
model = LogisticRegression(random_state=1)
model.fit(X_train_tfidf, y_train)
### Predictions
y_pred = model.predict(X_test_tfidf)
### Classification Report
print("Classification Report:")
print(classification_report(y_test, y_pred))
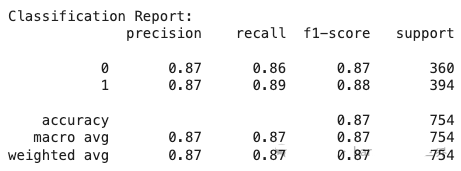
2. 使用嵌入作为特征的逻辑回归
在本实验中,我们将利用预训练的嵌入模型进行特征提取,并使用这些嵌入来训练一个轻量级分类器进行二分类。
这种两步法使我们能够利用先进嵌入模型的强大功能,而无需进行微调,从而提高计算效率并使其更易于访问。
步骤:
- \1. 特征提取:
- • 使用预训练的嵌入模型(例如,
sentence-transformers/all-MiniLM-L6-v2)将文本输入转换为数值嵌入。 - • 嵌入模型保持冻结状态,以确保训练过程中计算成本最小。
2. 训练分类器:
- • 利用生成的嵌入作为输入特征。
- • 在这些特征和标签上训练逻辑回归模型以进行分类。
3. 评估:
- • 在未见过的数据上测试训练好的分类器。
- • 使用精确度、召回率、F1分数和准确率等指标评估性能。
这种方法的好处:
- • 计算效率:嵌入生成可以通过GPU加速或外包给API,而分类器可以在CPU上进行训练。
- • 简单性:将特征提取和分类分开使得流程简单明了且模块化。
- • 多样性:分类器可以轻松替换为其他算法以进行实验。
可用的预训练嵌入模型来自 sentence-transformers: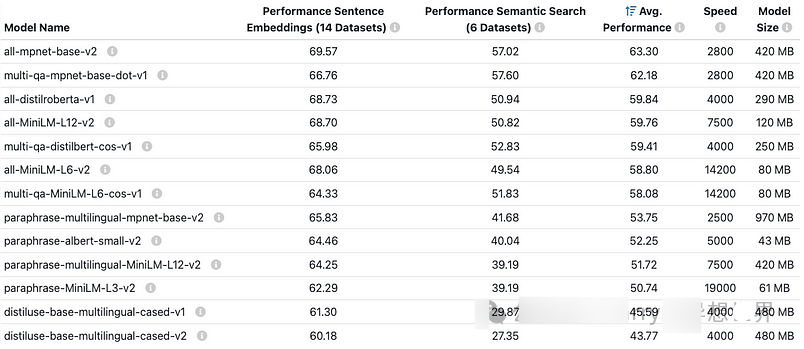
为什么使用 all-MiniLM-L6-v2?
sentence-transformers/all-MiniLM-L6-v2 模型是一个高效且多功能的嵌入模型,平衡了性能和计算要求,使其成为许多文本处理任务的理想选择。以下是值得考虑的原因:
- \1. 轻量级架构:MiniLM(迷你语言模型)是基于变换器模型的精简版本,显著减小了模型的体积,同时保持良好的性能。只有 6 层,相比于 all-mpnet-base-v2 等更大模型,它更小更快。
- \2. 高效性:使用 all-MiniLM-L6-v2 生成嵌入非常高效,即使在 CPU 上也能快速处理文本,适合需要实时或大规模嵌入计算的任务。
- \3. 竞争性性能:尽管体积小,但它提供的句子嵌入质量高,适用于许多自然语言处理任务,如分类、聚类和语义搜索。该模型在准确性和速度之间取得了良好的平衡,相比于更大模型,性能略有折衷。
- \4. 紧凑的嵌入:all-MiniLM-L6-v2 生成的嵌入具有 384 维,比 all-mpnet-base-v2 等模型的 768 维更紧凑。这些较小的嵌入减少了内存需求,并提高了下游任务(如训练分类器)的速度。
- \5. 通用性:在广泛的数据集上进行预训练,该模型捕获了通用的语义信息,并且在不同领域中表现良好,无需微调。
- \6. 可扩展性:其高效性和较小的嵌入使其理想用于:大数据集。计算资源有限的应用场景。需要在网络上存储或传输嵌入的场景。
我们将首先使用 all-mpnet-base-v2 来比较其与 all-MiniLM-L6-v2 的性能和速度。
from sentence_transformers import SentenceTransformer
### Load model
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
### Convert text to embeddings
train_embeddings = model.encode(train['review'], show_progress_bar=True)
test_embeddings = model.encode(test['review'], show_progress_bar=True)
### Logistic Regression Model
model = LogisticRegression(random_state=1)
model.fit(train_embeddings, y_train)
### Predictions
y_pred = model.predict(test_embeddings)
### Classification Report
print("Classification Report:")
print(classification_report(y_test, y_pred))
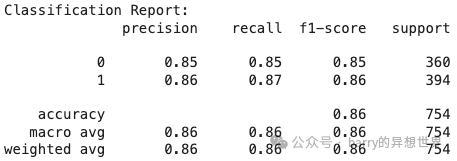
我们在大约 7 分钟内获得了 0.86 的准确率。现在我们将使用 all-MiniLM-L6-v2。
### Load model
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
### Convert text to embeddings
train_embeddings = model.encode(train['review'], show_progress_bar=True)
test_embeddings = model.encode(test['review'], show_progress_bar=True)
### Logistic Regression Model
model = LogisticRegression(random_state=1)
model.fit(train_embeddings, y_train)
### Predictions
y_pred = model.predict(test_embeddings)
### Classification Report
print("Classification Report:")
print(classification_report(y_test, y_pred))
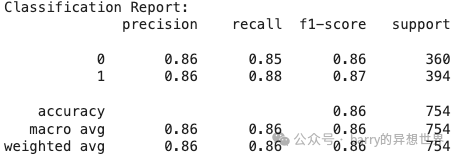
我们在大约 1 分钟内获得了 0.86 的 F1 分数。速度更快,且没有损失性能。
3. 零样本分类与嵌入
在本实验中,我们将探讨零样本分类,这是一种允许我们在没有任何标记训练数据的情况下执行分类任务的技术。
该方法利用嵌入和余弦相似度将输入文本与预定义的标签描述进行匹配,从而实现无需资源密集型标记工作的分类。
关键步骤:
- \1. 定义标签:为标签创建描述,例如:
- • “负面评价”
- • “正面评价”
这些描述充当我们的“伪标签”,并使用预训练的嵌入模型进行嵌入。
2. 嵌入文档和标签:使用预训练模型(例如,sentence-transformers)生成以下内容的嵌入:
- • 输入文档(例如,测试数据)。
- • 标签描述。
3. 余弦相似度:
- • 使用余弦相似度计算文档嵌入和标签嵌入之间的相似性。
- • 将相似度最高的标签分配给每个文档。
4. 评估:
- • 将预测标签与真实标签进行评估,以评估这种零样本方法的性能。
零样本分类的优势:
- \1. 无需标记数据:消除了昂贵且耗时的手动标记的需求。
2. 灵活的标签描述:标签描述可以根据任务或领域进行定制,提高嵌入的相关性。
3. 嵌入的多功能性:展示了嵌入在超越监督分类的广泛语言任务中的强大能力。
### Step 1: Create embeddings for the label and test data
### Load model
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
label_descriptions = ["A negative review", "A positive review"]
label_embeddings = model.encode(label_descriptions)
test_embeddings = model.encode(test['review'], show_progress_bar=True)
### Step 2: Calculate cosine similarity between document and label embeddings
from sklearn.metrics.pairwise import cosine_similarity
similarity_matrix = cosine_similarity(test_embeddings, label_embeddings)
### Assign the label with the highest similarity score to each document
y_pred = np.argmax(similarity_matrix, axis=1)
### Step 3: Evaluate the model's performance
print("Classification Report:")
print(classification_report(y_test, y_pred))
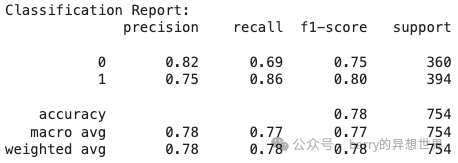
我们在没有训练数据的情况下获得了令人印象深刻的 0.78 准确率!
我们使用了 all-mpnet-base-v2,而 all-MiniLM-L6-v2 仅获得了 0.66 的准确率,在处理负面评论时遇到了困难。
4. 使用生成模型进行分类
在本实验中,我们将探索如何使用生成语言模型进行文本分类。
与传统的预测数值的分类模型不同,生成模型如Flan-T5生成文本响应,我们将其映射到数值以进行评估。
关键步骤:
- \1. 模型选择:
- • 使用 Flan-T5 模型,这是一个序列到序列(编码器-解码器)生成模型,通过
text2text-generation任务加载。 - • 从最小的模型
flan-t5-small开始,以便更快地进行实验,并根据需要扩展到更大的版本(例如,base、large、xl、xxl)。
2. 提示工程:
- • 使用 提示 指导模型以为任务提供上下文,例如:
"Is the following review positive or negative?"
- • 每个输入文档前都加上这个提示,以确保模型理解分类任务。
3. 数据准备:更新数据集以包括前缀文本:
- • 将提示和文本映射到一个新特征,例如
"t5"。 - • 这为生成分类管道准备了数据集。
4. 推断:
- • 在测试数据集上使用管道运行 Flan-T5 模型。
- • 收集生成的输出(例如,
"positive"或"negative"),并将其转换为数值标签(例如,正面为 1,负面为 0)。
5. 评估:
- • 使用标准指标(如 F1-score、精确度和召回率)评估模型性能。
- • 将文本输出映射到数值,以便与真实值进行比较。
为什么使用 Flan-T5?
- \1. 指令调优的生成能力:
- • Flan-T5 系列模型经过超过一千个任务的微调,擅长遵循指令并生成准确的任务特定输出。
2. 灵活性:
- • 该模型不受预定义类别的限制,可以通过提示工程适应各种任务。
3. 预训练的多样性:
- • 其生成特性使其能够处理未明确训练过的任务,非常适合任务特定数据较少的场景。
from datasets import Dataset
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
### Add a prompt column
prompt = "Is the following review positive or negative? "
test['t5'] = prompt + test['review']
### Convert pandas DataFrame to datasets.Dataset for compatibility with Hugging Face pipeline
dataset = Dataset.from_pandas(test)
我们将使用 Hugging Face 的 pipeline 抽象。
参数:
- • task (str) — 定义将返回哪个管道的任务。一些接受的任务包括:
text2text-generation、text-classification和text-generation。 - • model (str 或 PreTrainedModel 或 TFPreTrainedModel,可选) — 将由管道用于进行预测的模型。
任务 text2text-generation 可以在 这里 找到,可用于此任务的模型可以在 这里 找到。
让我们使用 google/flan-t5-small 模型。
### Load model
pipe = pipeline(
task="text2text-generation",
model="google/flan-t5-small",
device=0 # Set to -1 for CPU, 0 for GPU
)
让我们查看第一条评论的输出格式。
KeyDataset 返回定义为 key 的特定列的内容。
for output in pipe(KeyDataset(dataset, key="review")):
print(output)
break
[{‘generated_text’: ‘superREAD MORE’}]
y_pred = []
### Run inference on the test set
for output in tqdm(pipe(KeyDataset(dataset, key="t5"))):
generated_text = output[0]["generated_text"]
# Map textual output to numerical labels
y_pred.append(0 if generated_text == "negative" else 1)
print("Classification Report:")
print(classification_report(y_test, y_pred))
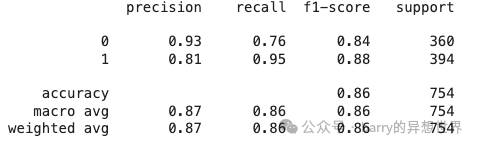
5. 使用任务特定模型进行情感分析
在这个实验中,我们将使用一个任务特定表示模型进行情感分类。
具体来说,我们将利用预训练的 juliensimon/reviews-sentiment-analysis 模型,该模型经过微调,专门用于对产品评论进行情感分析,以将产品评论分类为正面或负面。
关键步骤:
- \1. 模型加载:
- • 使用
transformers.pipeline加载预训练模型及其分词器。 - • 分词器将输入文本拆分为模型可以处理的标记。
2. 推理:
- • 将测试数据传递给管道,并检索情感分数(例如,负面和正面)。
3. 评估:
- • 将预测标签(y_pred)与真实标签(y_true)进行比较。使用分类报告评估精确度、召回率、F1 分数和准确率。
model_path = "juliensimon/reviews-sentiment-analysis"
### Load model into pipeline
pipe = pipeline(
model=model_path,
tokenizer=model_path,
device=0
)
for output in pipe(KeyDataset(dataset, key="review")):
print(output)
break
{‘label’: ‘LABEL_0’, ‘score’: 0.6483076214790344}
### Convert pandas DataFrame to datasets.Dataset for compatibility with Hugging Face
dataset = Dataset.from_pandas(test)
y_pred = []
### Run inference on the test set
for output in tqdm(pipe(KeyDataset(dataset, key="review"))):
label = output["label"]
# Map textual output to numerical labels
y_pred.append(0if"0"in label else1)
print("Classification Report:")
print(classification_report(y_test, y_pred))
本文探讨了多种情感分类方法,从传统技术如使用 TF-IDF 的逻辑回归到先进的生成模型如 Flan-T5\。
每种方法都有其优缺点,适用于基于准确性、计算资源和数据可用性的不同用例。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









