









 本文探讨了使用Python机器学习库中的线性模型对不同数据集进行可视化的实践,包括两类和三类分类数据集的可视化,解释了mglearn库在绘制分类数据时的特殊处理方式,以及如何通过代码实现这一过程。
本文探讨了使用Python机器学习库中的线性模型对不同数据集进行可视化的实践,包括两类和三类分类数据集的可视化,解释了mglearn库在绘制分类数据时的特殊处理方式,以及如何通过代码实现这一过程。
一、疑问
第一个数据集的可视化:
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
import mglearn
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
X, y = mglearn.datasets.make_forge()
print(y)
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
for model, ax in zip([LinearSVC(), LogisticRegression()], axes):
clf = model.fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=False, eps=0.5,
ax=ax, alpha=.7)#画线的命令
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)#画点的命令
ax.set_title(clf.__class__.__name__)
ax.set_xlabel("Feature 0")
ax.set_ylabel("Feature 1")
axes[0].legend()
plt.show()
其实就是45页的图2-15的Logistic回归
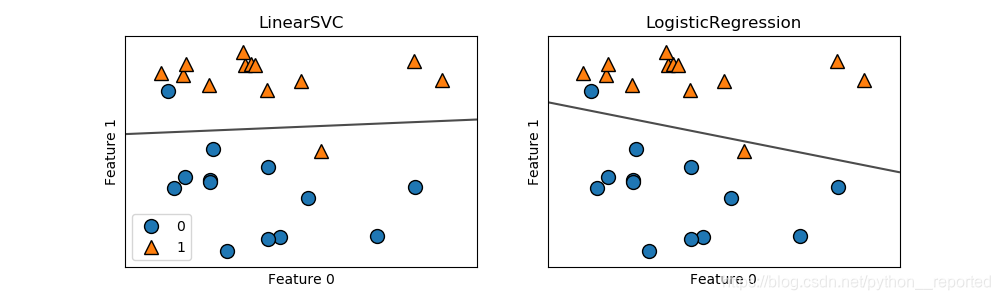
第二个数据集的可视化:
from sklearn.datasets import make_blobs
import mglearn
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVC
X, y = make_blobs(random_state=42)#random_state=42报持随机一致
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
#plt.scatter(X[:, 0], X[:, 1], y)#这也是两个数据集
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.legend(["Class 0", "Class 1", "Class 2"])
plt.show()
就是50页图2-19:
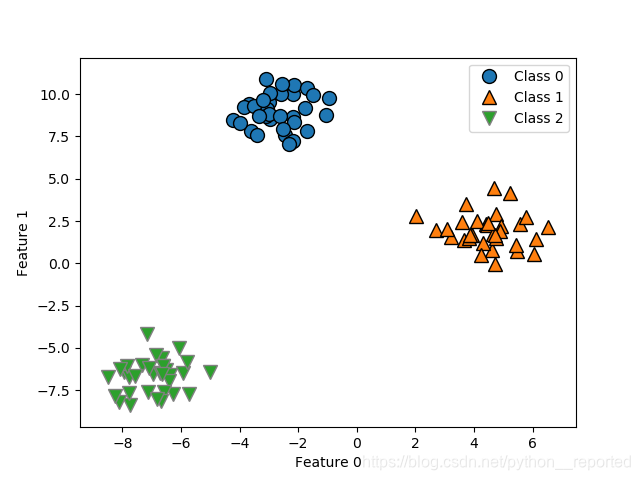
问题:
都是:mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
问什么一个是两类一个是三类
为此还专门对第二个数据集利用matplotlib进行可视化,发现确实是两个数据,
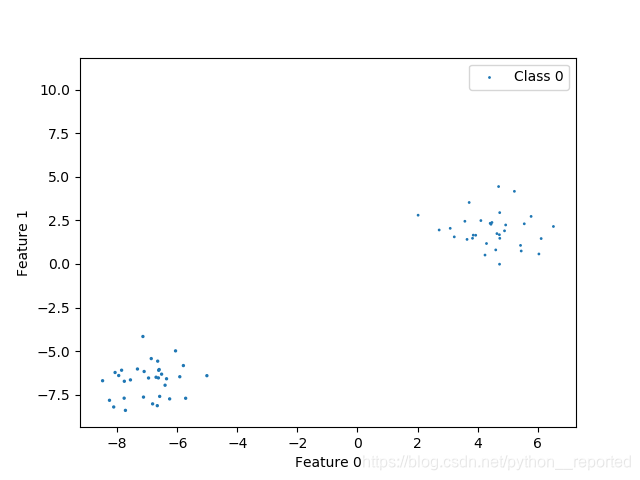
应该一样啊!为什么第二个数据集会有三类
二、理解
命令行中X为二维数据集因而[:, 0]第一列# 输入X第0列和第1列作为x轴,将y作为y轴,纯数据上来说是应该与matplotlib进行可视化一样只有两类,
但是mglearn绘图并不是xy绘图,即y不是x的值,y就是类别本身
第一个数据集只有两类是因为y值只有0、1
例如第一个数据集的y
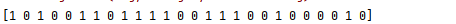
第二个数据集的y

这个0、1、2就像鸢尾花数据集中的[‘target’]一样只是一个类别代数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









