









RNN、self-attention、transform的浅显或许错误的理解
所有的理解都是基于我匮乏的数学知识,当成y = kx+b来理解
一、RNN的理解
刚开始学的时候看了很多文章,但是感觉都是云里雾里,要么是数学要么是各种没有说明白的图,但是看的多了以后看到《难以置信!LSTM和GRU的解析从未如此清晰(动图+视频)》 《难以置信!LSTM和GRU的解析从未如此清晰(动图+视频)》.之后,有了自己简单但可能错误的理解
rnn:遗忘门-前文信息相加,由其值的大小作为k
输入门:将前文作为k,然后乘上当前输入
输出门:输入门的结果与前文信息共同作为k,
然后乘以当前输入作为输出
因而梯度爆炸、梯度消失就很好理解了,因为连续乘以k,若k大就会互相爆炸式增长,若k小就会爆炸式的小,导致梯度爆炸、梯度消失
二、self-attention的理解
我是看了这篇《浅谈Attention机制的理解》《浅谈Attention机制的理解》.才感觉理解的,
正如这篇文章结语所说“Attention机制说大了就一句话,分配权重系数。当然里面还有很深的数学道理和理论知识,我还是没搞懂滴。所以这点浅显的理解就当茶语饭后的笑谈吧。”
我的理解就是将原有的词向量作为x,重新训练了一个k的矩阵,
在decode的时候,将词向量与权重向量同时decode的作为输出
由
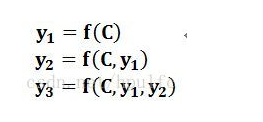
变为
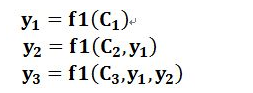
与全连接层比较后的思考:
全连接层,将x作为自变量,y为因变量,求出xy直接的关系k
而预训练模型中的attention需要理解的是词语即x之间的关系,就要让x变成k,那就需要原来的k变为自变量也就是当前y=kx的x,那么在不断的训练中,词向量就出来了。让原来的k变为x,就可以kx=y(k),来完成。
三、Transform的理解
关于Transform我最不能理解的就是q、k、v这三个矩阵,在刚刚写理解的时候突然发现q、k竟然是self-attention中存在的,我之前一直以为是transform特有的
参考文章:
《transformer问题整理(参考知乎大佬内容)》《transformer问题整理(参考知乎大佬内容)》.
《transformer中为什么使用不同的K 和 Q, 为什么不能使用同一个值?》《transformer中为什么使用不同的K 和 Q, 为什么不能使用同一个值?》.
赤乐君认为:“我们知道K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。”
我的理解就是kq就是计算k,只是这样kq计算可能更加具有泛化性,因为kq的矩阵方向不同。q即查询向量等于全文向量,k是q与当前字向量的相似度,kq即为输入字向量的k加权值,kv相乘就完成了当前输入字向量的加权。如下图
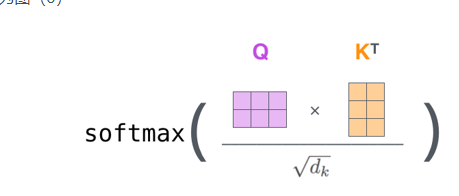
kq的矩阵并不一样,一个横向,一个纵向,代表的含义不一样,横向即自身,纵向即上文,相乘后得到全文相似度即k的值,更加具有泛化性。
四、结语
自我感觉能够解释,但是或许不那么对。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









