









 本文介绍了如何使用Python爬虫获取CSDN上用户的文章数量,通过分析网址参数,利用API接口,解析JSON数据,实现对CSDN博主文章数的抓取。同时,展示了如何获取排行榜前200名的大佬文章数。
本文介绍了如何使用Python爬虫获取CSDN上用户的文章数量,通过分析网址参数,利用API接口,解析JSON数据,实现对CSDN博主文章数的抓取。同时,展示了如何获取排行榜前200名的大佬文章数。
前言
最近刚学会Python爬虫(不会的看这边,这篇优秀的文章是我自己写的),爬虫使用了BeautifulSoup,那能不能不用BeautifulSoup来爬虫呢?我们来看一下。
开发者工具
我在以前的文章里讲过开发者工具的用法,不过它还有其它的功能,我这里以谷歌浏览器举例。
在浏览器内Ctrl+Shift+I或右键点击网页任意位置并选择“检查”(其它浏览器可能会不同),打开开发者工具:


接下来Network --> All --> 刷新界面:

下面的一堆东西会不一样,不要管。
它的作用是不停跟踪网站在做什么,我们可以通过它来找到网页用的API。
比如百度翻译会使用API来完成翻译部分,我们看到的翻译网页会向百度翻译API发送参数,如翻译语言,翻译内容等,然后API会返回翻译之后的内容,百度翻译再把内容显示出来。
网址参数
同理,我们可以利用API获取CSDN上用户的信息,如参与问答数、文章数等。
但在这之前,我们需要知道一样东西,叫做网址参数。
什么是网址参数呢?我来举一个例子:
比如百度搜索,它是怎么利用我们每次搜索的内容来改变网址的呢?难道是把每一个搜索内容都写一个单独的网址?这是不可能的。那么这时候,网址参数就起到作用了。
来看一下下面的两个使用百度搜索不同内容的网址:
https://www.baidu.com/s?tn=02003390_43_hao_pg&isource=infinity&iname=baidu&itype=web&ie=utf-8&wd=csdn
https://www.baidu.com/s?tn=02003390_43_hao_pg&isource=infinity&iname=baidu&itype=web&ie=utf-8&wd=python
它们有什么共同点,又有什么不同呢?
可以看到,两个网址的前面都是“https://www.baidu.com/s”,然后是一个问号?,问号后面用&分隔着一堆东西。
这堆东西就是网址参数。
我们以上面iname=baidu这个参数为例,iname就是参数的名字,baidu就是参数的内容。
在上面的两个网址中,唯一不同的参数就是wd,很显然,它就是搜索的内容。
动手实践
那么我们来干一点正事:用Python获取C站大佬们的文章数量!
刚刚我也讲到了,我们可以利用API获取CSDN上用户的信息,那么我们就先要得到API的网址。
懒得说了,看图:
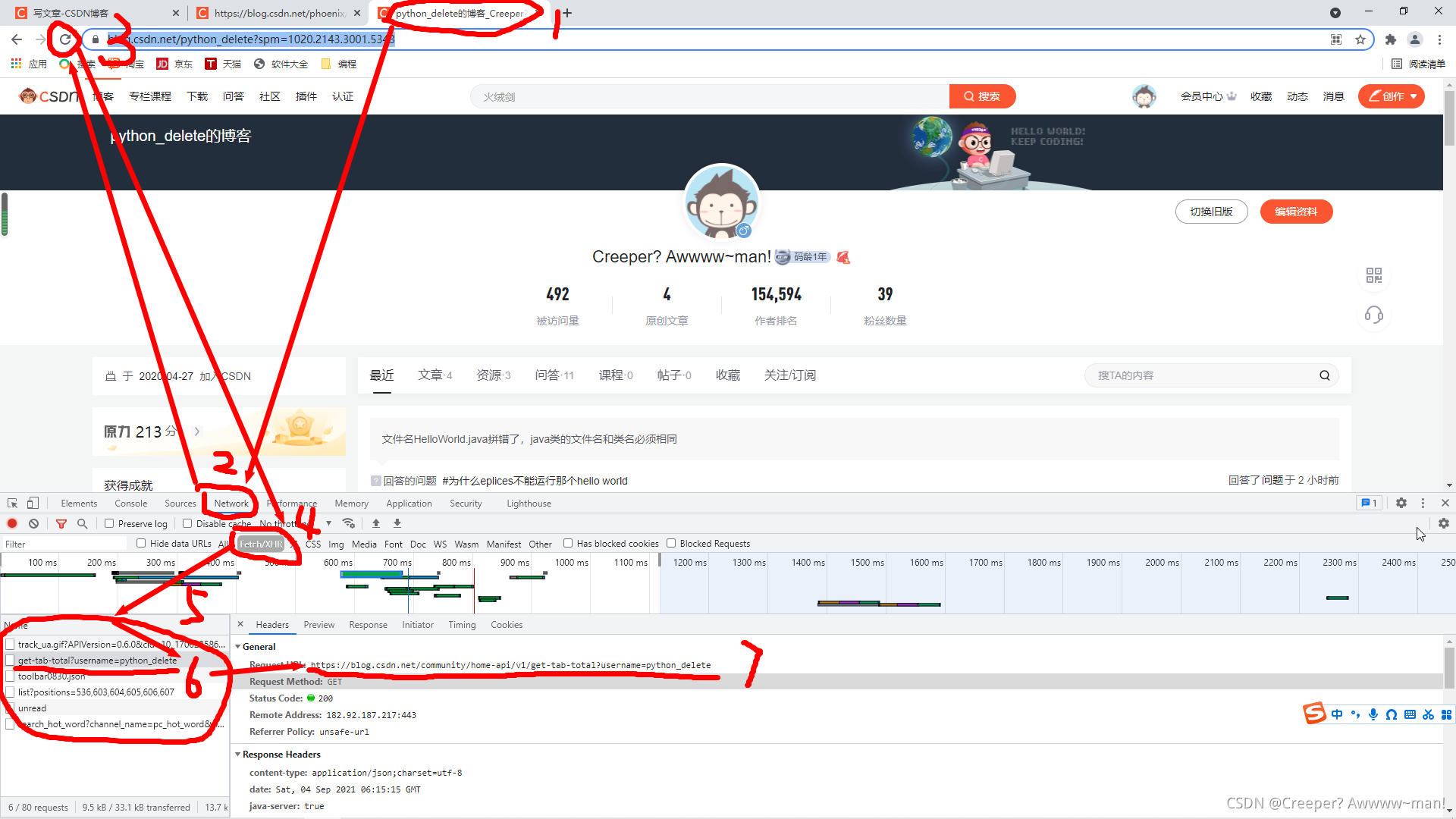
这样就可以得到API的网址,请注意:第五步中,要把每一个可疑的网址都看一遍。
网址有一个username参数,很明显,是我们的用户名。
我们把网址测试一下:https://blog.csdn.net/community/home-api/v1/get-tab-total?username=python_delete
好!API返回json格式,我们的文章数在data键的blog键中,用Python处理即可:
import requests
import json
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"
} # 请求头
informations_html = requests.get("https://blog.csdn.net/community/home-api/v1/get-tab-total?username=python_delete", headers=headers)
informations = json.loads(informations_html.text) # 将字符串转换为Python字典
informations = informations["data"]["blog"]
print(informations)

很好,这样我们就能获得我写的文章数量了,如果要得到其他人的,请自行修改username参数。
升级程序
光爬取自己的文章数有什么意思?我们要看看大佬们的文章数啊!
那么问题来了,怎么获取大佬们的用户名呢?交给开发者工具吧!
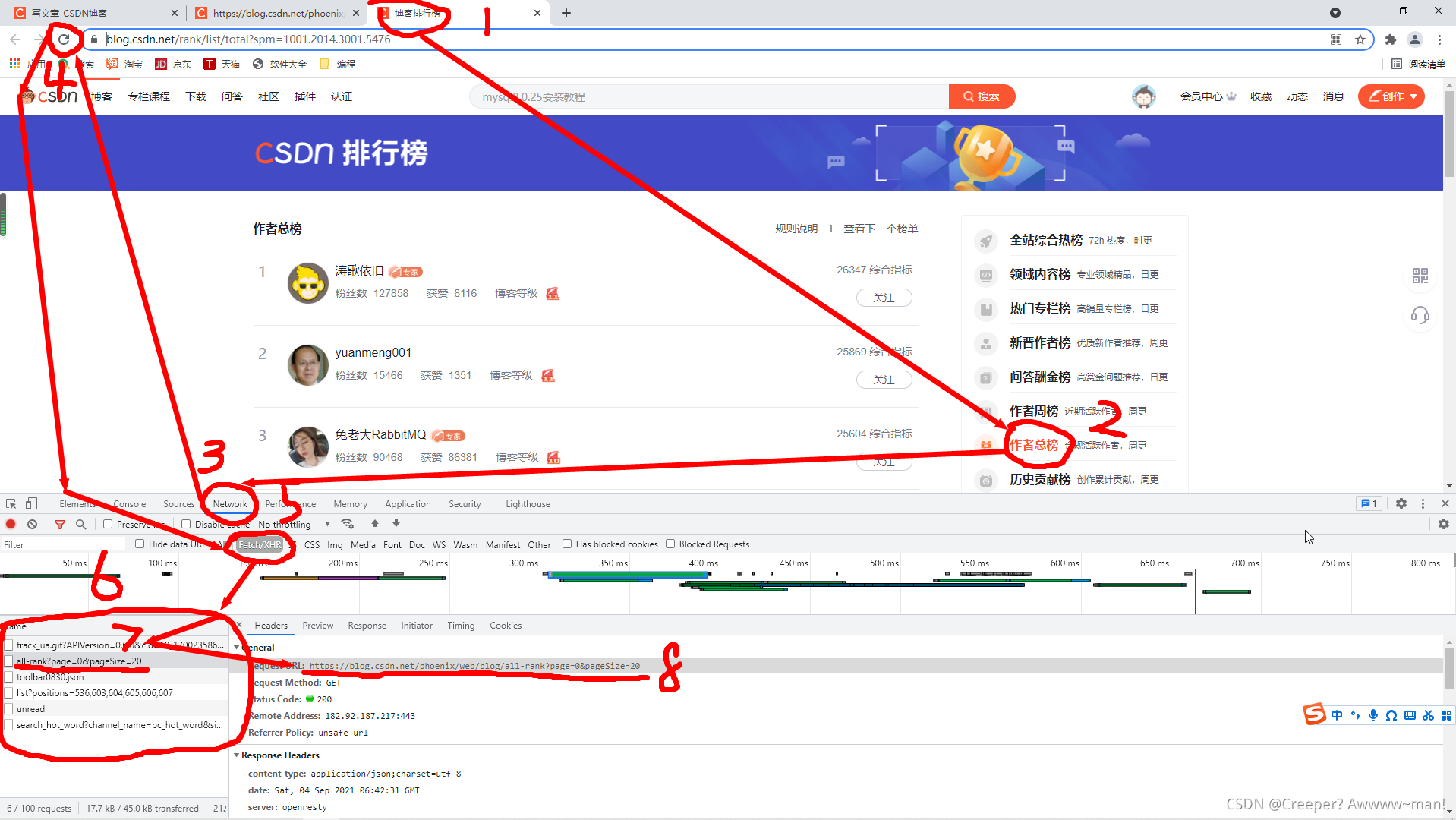
爬取作者总榜上的大佬文章数,好让自己立志写文章嘛!

https://blog.csdn.net/phoenix/web/blog/all-rank?page=0&pageSize=20
这是我们得到的API网址,有两个参数:page和pageSize。
page是榜单的第几页,pageSize是一页显示几个人。
经过不断的调整,我发现榜单一共只有200个人,所以我们就只获取榜单的前200名大佬的文章数。
代码如下:
import requests
import time
import json
import random
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"
} # 请求头
authors_html = requests.get("https://blog.csdn.net/phoenix/web/blog/all-rank?page=0&pageSize=200", headers=headers)
authors = json.loads(authors_html.text) # 将字符串转换为Python字典
authors_name = [i["nickName"] for i in authors["data"]["allRankListItem"]] # 作者名
authors = [i["userName"] for i in authors["data"]["allRankListItem"]] # 作者用户名
time.sleep(3) # 休眠,避免被限流或封号
for i, j in zip(authors, authors_name):
informations_html = requests.get(f"https://blog.csdn.net/community/home-api/v1/get-tab-total?username={i}", headers=headers)
informations = json.loads(informations_html.text)
informations = informations["data"]["blog"]
time.sleep(3 + random.random()) # 休眠,避免被限流或封号
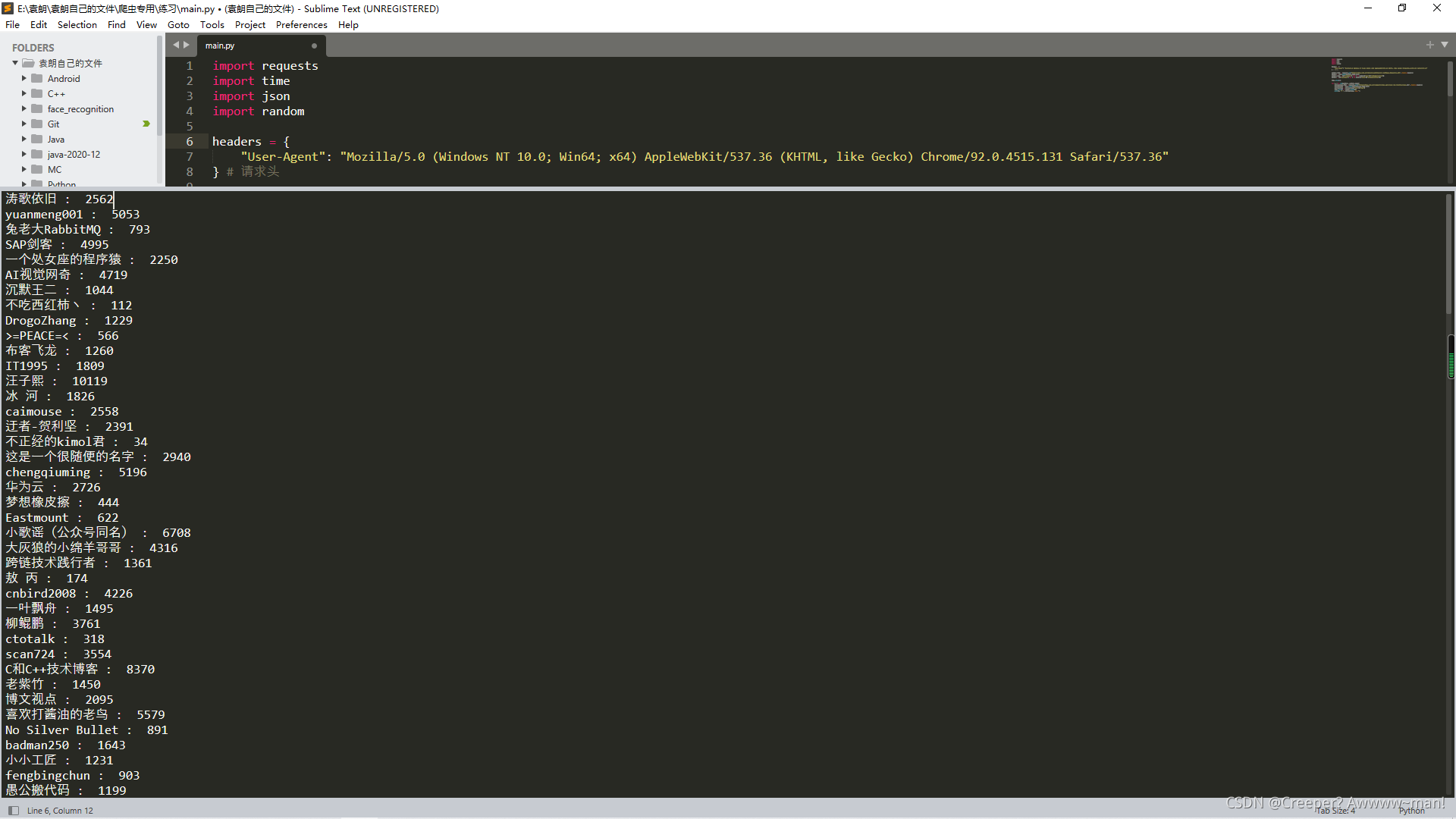
print(j, ": ", informations, sep="") # 打印结果
Python爬虫系列:
Python爬虫教程1
最后请大家给个三连支持一下吧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









