







链表在数据结构中相当的重要,在以后的实际工作中使用率也很高,所以今天分享一些关于链表的基本操作:
1.链表的概念以及定义:
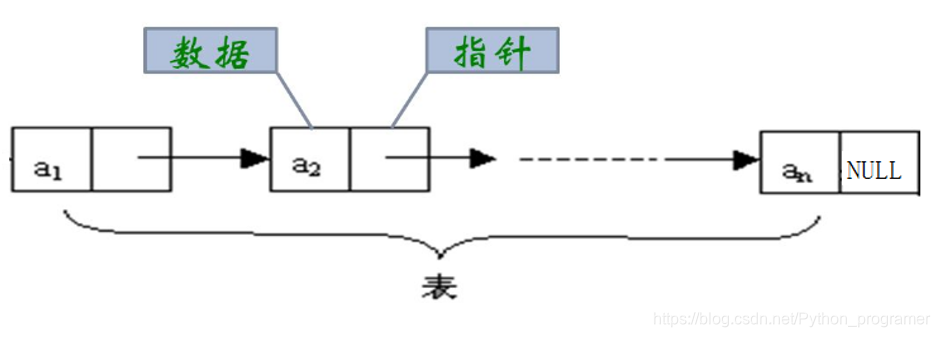
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的,形式如下图所示:
typedef struct Node //链表的定义
{
int value; //结点的数据域
struct Node* next; //结点的指针域
}Node;
2.无头单向非循环链表的一些基本操作:
1.链表的初始化
这里说一下为什么要使用二级指针,首先是定义一个指针指向首结点,因为链表的操作全程靠指针完成,凡是牵扯到首结点指针指向的改变都得用二级指针。
void SListInit(Node **ppFirst)
{
*ppFirst = NULL;
}
2.销毁链表
void SListDestroy(Node *first)
{
Node* ptr; //定义ptr指针记录当前结点的下一个结点位置,然后再free当前结点
for (Node* cur = first; cur != NULL; cur = ptr) //定义cur指针来操作链表,而不是直接使用头指针。
{
ptr = cur->next;
free(cur);
}
}
3.链表的头插
//头插不需要担心头指针为空的问题,因为这个方法一样适用
void SListPushFront(Node **ppFirst, int v)
{
Node* node = (Node*)malloc(sizeof(Node)); //先为要插入的新结点申请空间
node->next = *ppFirst;
*ppFirst = node;
node->value = v;
}
4.链表的尾插
void SListPushBack(Node **ppFirst, int v)
{
if (*ppFirst == NULL) //头指针为空的话就相当于头插
{
Node* node = (Node*)malloc(sizeof(Node));
node->next = *ppFirst;
*ppFirst = node;
node->value = v;
return;
}
//找到尾结点
Node* cur = *ppFirst;
while (cur->next != NULL){
cur = cur->next;
}
Node* node = (Node*)malloc(sizeof(Node));
node->next = NULL; //这行和下面这行的代码顺序不能改变,否则会出错
cur->next = node;
node->value = v;
}
5.链表的头删
void SListPopFront(Node **ppFirst)
{
assert(*ppFirst != NULL); //首先判断是否为空
Node* ptr = (*ppFirst)->next; //首先定义指针ptr记录首结点的下一个结点的位置,然后再释放首结点,否则会导致后面的数据全部丢失
free(*ppFirst);
*ppFirst = ptr;
}
6.链表的尾删
void SListPopBack(Node **ppFirst)
{
assert(*ppFirst != NULL);
if ((*ppFirst)->next == NULL) //这是链表中只有一个结点的情况
{
free(*ppFirst);
*ppFirst = NULL;
return;
}
Node* ptr = *ppFirst;
while (ptr->next->next!= NULL) //找到倒数第二个结点
{
ptr = ptr->next;
}
free(ptr->next); //先释放尾结点所占内存,否则会导致内存泄漏
ptr->next = NULL; //再让倒数第二个结点的next=NULL
}
7.查找数据为指定值的结点
Node * SListFind(Node* first, int v)
{
for (Node* cur = first; cur != NULL; cur = cur->next)
{
if (cur->value == v)
return cur;
}
}
8.在pos后插入一个结点
void SListInsertAfter(Node *pos, int v)
{
Node* node = (Node*)malloc(sizeof(Node));
node->value = v;
node->next = pos->next;
pos->next = node;
}
9.删除pos后的一个结点
void SListEraseAfter(Node *pos)
{
Node* ptr = pos->next; //定义一个指针ptr记录pos的下一个结点地址
pos->next = pos->next->next; //改变pos指针域,让pos和他后面的第二个结点相连
free(ptr); //此时释放ptr
}
10.修改指定值的结点的值
void SListModify(Node *ppFirst,int u,int v)
{
if (ppFirst == NULL)
{
return;
}
Node* ret = SListFind(ppFirst,u);
if (ret != NULL)
{
if (u != v)
{
ret->value = v;
}
else
return;
}
else
return;
}
11.打印链表
void SLprint(Node* first)
{
if (first == NULL)
{
return;
}
for (Node* cur = first; cur != NULL; cur = cur->next)
{
printf("%d ",cur->value);
}
}
3.总结
将顺序表和链表做一个对比:
顺序表:
空间连续,支持随机访问且方便;但是中间或前面插入的时间复杂度为O(n),容量的代价比较大。
链表:
是以结点为单位存储,不支持随机访问,在任意位置插入删除时间复杂度O(1),没有增容问题,插入一个开辟一个空间,但是查找的时间复杂度就为O(n),对于不清楚总量的数据,空间利用率高。
链表和顺序表的使用场景还得因情况而定。














 1561
1561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









