






APP 也有文字转换为语音的功能,虽然听起来很别扭,但是基本能解决长辈们看不清文字或者眼睛疲劳,通过文字转换为语音来获取信息。
我们用 Python 能否实现文字转语音呢,可以的,百度有个语音接口,可以在 Python 中直接调用,甚至提供了多种声音选择,当然可以选择萌妹子的声音。
通过 pip 命令直接安装( -i 后面是豆瓣的镜像,这样下载安装速度更快)
百度语音合成地址如下:
点击立即使用,没有登录的会要求先登录,用自己的百度的账号登录就可以,没有百度账号的新注册一个。
登录后进入应用页面,语音识别包括:输入法、搜索、英语、粤语、四川话、远扬,还有语音合成等库。我们可以看到,大部分 API 的调用次数免费且无限制的。
我们创建一个应用,勾选需要的接口权限,我的要求比较简单,只是简单的文字转语音,所以勾选的接口也比较少。当然,这个接口还可以做人脸识别、图像识别、自然语言处理等,大家按需选择。

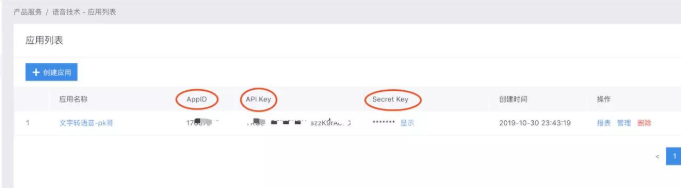
创建完成后,我们在应用列表可以看到应用的三个重要的值:AppID、API Key、Secret Key,这三个值等下调用接口时会用到。
在文档中心,我们来看看基本的上传参数。

根据接口文档,我们写个简单的代码,能够调通接口就行。
我们需要填入你创建应用的 APPID、APIKEY 和 SECRET_KEY 的值。
其中,per 的值表示男女声的,0 和 1 是普通的女声和男声,听起来有点别扭,3 和 4 是带有感情的,明显比 0 和 1 有感情,大家可以试试。
执行代码后,同级目录下就会生成一个 audio.mp3 的文件。
我们加入金山词霸的接口,每天返回优美的英文和中文翻译语句,我们让度丫丫把她读出来,让声音秒变撒娇萌妹。
金山词霸的接口很简单,直接 requests 调用,返回的 json 格式语句,我们返回英语语句和中文语句。
给出 APPID、APIKEY 和 SECRET_KEY 的值。
下面的步骤和上面一样,只是把上面固定的文本换成接口返回的金山词霸的语句而已。

我们打开文件,还能听出一些撒娇声,不信?你打开听听!
我发文章的时候,金山词霸返回的中文语录是:事情很少是不可能的;人们之所以不成功,与其说是条件不够,不如说是决心不够。
接下来,就可以把这个撒娇萌妹的音频 发微信给朋友 或者免费发短信给朋友 都可以,之前讲过,这里就不再啰嗦了。
作者:Python知识圈链接:https://juejin.im/post/5dca056e5188256e0638e65c














 1085
1085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









