






DBeaver自带的默认格式化和紧凑格式化对我来说太简陋了,于是折腾一下外部格式化程序。网上一搜有python版的,那就直接搞起。
先来看下效果
UPDATE TABLE1
SET A=2
WHERE A=1 SELECT TABLE1.ID,
TABLE2.NUMBER,
SUM(TABLE1.AMOUNT)
FROM TABLE1
INNER JOIN TABLE2
ON TABLE1.ID = TABLE2.TABLE1_ID
WHERE TABLE1.ID IN (
SELECT TABLE1_ID
FROM TABLE3
WHERE TABLE3.NAME = 'Foo Bar'
AND TABLE3.TYPE = 'unknown_type'
)
GROUP BY TABLE1.ID,
TABLE2.NUMBER
ORDER BY TABLE1.ID;
准备
首先需要安装python和模块sqlparse
pip install sqlparse
新建一个py文件
拷贝以下内容
import sys
import sqlparse
import io
def sql_formatter(sql):
res = sqlparse.format(
sql,
keyword_case="upper",
identifier_case="upper",
truncate_strings=100,
reindent_aligned=True,
comma_first=False,
wrap_after=60,
)
return res
if __name__ == "__main__":
filepath = sys.argv[1]
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding="utf-8")
with open(filepath, "r", encoding="utf-8") as f:
read_sql = f.read()
for sql in read_sql.split(";"):
s = sql.replace("\n", " ").strip()
if len(s) != 0:
s = sql_formatter(s) + ";\n"
print(s)
自定义格式
sqlparse.format函数的参数说明:
| 参数 | 含义 |
|---|---|
| keyword_case | 改变关键字的格式化方式。允许的值有 “upper”、“lower” 和 “capitalize” |
| identifier_case | 改变标识符的格式化方式。允许的值有 “upper”、“lower” 和 “capitalize”。 |
| strip_comments | 若为 True,则从语句中删除注释。 |
| truncate_strings | 若 truncate_strings 为正整数,则会将超过给定值长度的字符串截断。 |
| truncate_char | (默认值: “[…]”)若字符串被截断(参见上述 truncate_strings),则此值将追加到被截断的字符串上。 |
| reindent | 若为 True,则会更改语句的缩进。 |
| reindent_aligned | 若为 True,则会更改语句的缩进,并通过关键字对齐语句。 |
| use_space_around_operators | 若为 True,则在所有操作符周围使用空格。 |
| indent_tabs | 若为 True,则使用制表符代替空格进行缩进。 |
| indent_width | 缩进的宽度,默认为 2。 |
| wrap_after | 用于换行逗号分隔列表的列限制(以字符计)。如果未指定,则每个项目都放在单独的行上。 |
| output_format | 若指定了此值,则输出还将格式化为在编程语言中使用的变量。允许的值有 “python” 和 “php”。 |
| comma_first | 若为 True,则使用逗号优先的方式表示列名。 |
参考原文链接:https://blog.csdn.net/szial/article/details/131964131
DBever设置
打开DBever,导航至 窗口-首选项-编辑器-SQL编辑器-SQL格式化,格式选外部格式化程序,命令行按照自己py文件的路径填写为python D:/PythonCode/sqlformat.py ${file},勾选使用临时文件,点应用就可以看到下面输出的效果了。
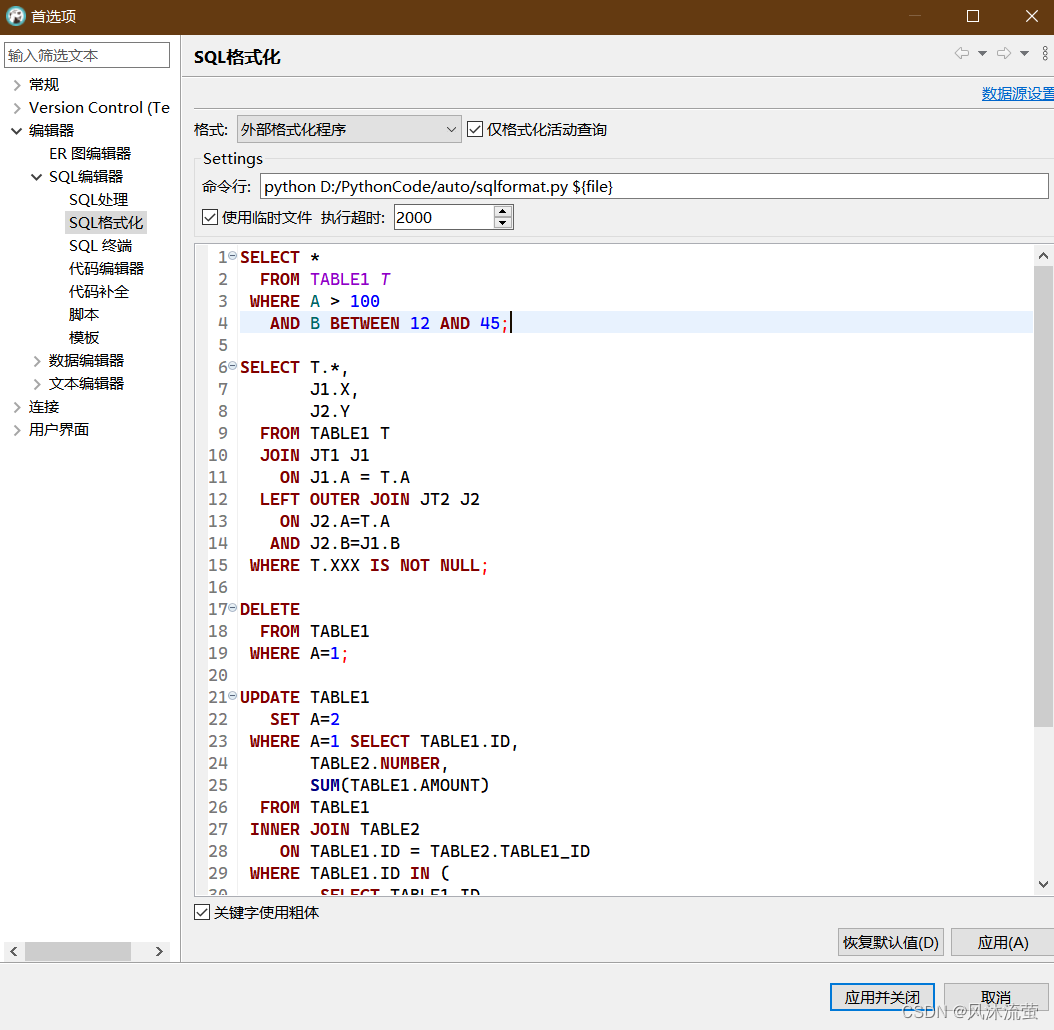
使用
在sql编辑器中右键-格式-格式化SQL,或者直接Ctrl-Shft-F即可格式化SQL。

















 4007
4007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









