






本文首先介绍了如何从头开始实现一个自定义tokenizer,用于将原始文本数据转化为模型能够理解的格式。通过这个例子,来直观理解什么是tokenizer;接着,分析这种tokenizer的优缺点,引出更常用的BPE;最后,基于BPE构建的tokenizer,构建用于GPT预训练时的数据加载器。
在阅读完本文后,你将学会如何构建用于GPT自回归预训练阶段的数据加载器,这将是你向着LLM训练迈出的第一步!
一、先动手,编写自定义tokenizer
step1. 读取语料
读取the-verdict.txt:
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character:", len(raw_text))
print(raw_text[:99])
输出:
Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no
step2. 分词
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(preprocessed[:30])
re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)将raw_text按照,.:;?_!"()\'中的任意一个('表示的是',\是转义,避免python语法错误),或者--,或者空格\s进行分割,接着item.strip() for item in preprocessed if item.strip()]去除空格。
输出:
['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in']
将这20479个字符组成的文本进行分词处理后,得到的字符数量为print(len(preprocessed))=4690
step3. 制作词表
首先,对上一步分词得到的结果进行去重:
all_words = sorted(set(preprocessed))
vocab_size = len(all_words)
print(vocab_size)#1130
去重后,还剩下1130个单词。
现在开始创建词表:
vocab = {token:integer for integer,token in enumerate(all_words)}
这样,每一个不同的单词都对应一个数字索引。
打印词表中前50个单词进行查看:
for i, item in enumerate(vocab.items()):
print(item)
if i >= 50:
break
输出:
('!', 0)
('"', 1)
("'", 2)
('(', 3)
(')', 4)
(',', 5)
('--', 6)
('.', 7)
(':', 8)
(';', 9)
('?', 10)
('A', 11)
('Ah', 12)
('Among', 13)
('And', 14)
('Are', 15)
('Arrt', 16)
('As', 17)
('At', 18)
('Be', 19)
('Begin', 20)
('Burlington', 21)
('But', 22)
('By', 23)
('Carlo', 24)
('Chicago', 25)
('Claude', 26)
('Come', 27)
('Croft', 28)
('Destroyed', 29)
('Devonshire', 30)
('Don', 31)
('Dubarry', 32)
('Emperors', 33)
('Florence', 34)
('For', 35)
('Gallery', 36)
('Gideon', 37)
('Gisburn', 38)
('Gisburns', 39)
('Grafton', 40)
('Greek', 41)
('Grindle', 42)
('Grindles', 43)
('HAD', 44)
('Had', 45)
('Hang', 46)
('Has', 47)
('He', 48)
('Her', 49)
('Hermia', 50)
以上是将单词映射到数字,可以称之为编码。既然有编码,那就需要对应的解码,这里就是将数字再映射回单词。
因此可以构建一个类,专门用于编码和解码:
class SimpleTokenizerV1:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [
item.strip() for item in preprocessed if item.strip()
]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
# Replace spaces before the specified punctuations
text = re.sub(r'\s+([,.?!"()\'])', r'\1', text)# 将,.?!"()\'等标点符号前面的空格去掉,因为join方法会在每个字符(不管是单词还是标点)前面都加一个空格
return text
举个例子:
tokenizer = SimpleTokenizerV1(vocab)
text = """"It's the last he painted, you know,"
Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text)
print(ids)#
[1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7]
反向解码:
tokenizer.decode(ids)
'" It\' s the last he painted, you know," Mrs. Gisburn said with pardonable pride.'
step4. 完善词表
在进行编码解码时,如果像被编解码的对象在词表中不存在,那就会引发报错。
text = "Hello, do you like tea?"
print(tokenizer.encode(text))
由于在词表中没有Hello整个词,因此上述代码将引发报错:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[28], line 2
1 text = "Hello, do you like tea?"
----> 2 print(tokenizer.encode(text))
Cell In[25], line 12, in SimpleTokenizerV1.encode(self, text)
7 preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
9 preprocessed = [
10 item.strip() for item in preprocessed if item.strip()
11 ]
---> 12 ids = [self.str_to_int[s] for s in preprocessed]
13 return ids
Cell In[25], line 12, in <listcomp>(.0)
7 preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
9 preprocessed = [
10 item.strip() for item in preprocessed if item.strip()
11 ]
---> 12 ids = [self.str_to_int[s] for s in preprocessed]
13 return ids
KeyError: 'Hello'
因此需要完善词表,增加对于这种特殊情况的处理。
all_tokens = sorted(list(set(preprocessed)))
all_tokens.extend(["<|endoftext|>", "<|unk|>"])
vocab = {token:integer for integer,token in enumerate(all_tokens)}
增加了两个特殊标记符,因此词表长度由1130变成了1132.
据此构建新的词表类:
class SimpleTokenizerV2:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = { i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
preprocessed = [
item if item in self.str_to_int
else"<|unk|>"for item in preprocessed
]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
# Replace spaces before the specified punctuations
text = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)
return text
使用新版的词表类再次编码以下内容,将不再报错:
tokenizer = SimpleTokenizerV2(vocab)
text = "Hello, do you like tea?"
print(tokenizer.encode(text))
输出:
[1131, 5, 355, 1126, 628, 975, 10]
二、常见的tokenizer
Word-level Tokenization 和 Character-level Tokenization
在上面,我们已经快速完成了手动编写tokenizer,上述实际上构建了一种词级(Word level)的tokenizer,它以单词为最小单位进行分词。
此外,还有许多其他的分词方式,比如字符级(Character level),也就是将分词的粒度扩展到单个字符,举个例子(为了简便,这里不考虑空格和标点符号):
分词前:"I love AI."
Word level分词后:"I" "love" "AI"
Char level分词后:"I" "l" "o" "v" "e" "A" "I"
以上两种方式各有优缺点,现在来详细介绍一下。
1. Word-level Tokenization
优点:
-
语义清晰:每个 Token 是一个完整的单词,易于理解和处理。
-
句子较短:不需要将一个单词拆分成多个 Token,计算成本相对低。
缺点:
-
OOV(未登录词,即没有出现在词表中的词)问题严重:例如,"Internationalization" 可能不在词表中,模型无法处理。直接填充一个特定token会导致语义缺失。
-
需要构建 超大词汇表(100K+),导致内存占用高,计算开销大。
-
对新词、拼写错误敏感:例如,"Covid19" 可能不在词汇表里,导致模型无法解析。
2. Character-level Tokenization
优点:
-
无 OOV 问题:任何新词都能被拆解。
-
词汇表极小(几十个字符),训练更高效。
缺点:
-
Token 序列太长:单词被拆得过细,导致计算成本上升。
-
语义信息丢失:无法直接理解 "Neural" 和 "networks" 的关联性。
Sub-word Tokenization
Sub-word Tokenization可以平衡上面两种tokenizer,成为主流的tokonization方式。
Sub-word Tokenization 是一种介于 词级(Word-level) 和 字符级(Character-level) 之间的分词方法,能够在减少未登录词(OOV)问题的同时保持一定的语义信息。
所谓sub-word,指的是可以将一个单词拆分成若干部分,比如'NeuralNetwork'可以被拆分为['Neural','Network'].
举例子:
常见词保持整体,如 "computer" -> ["computer"]
罕见词拆分为子词,如 "computational" -> ["comput", "ational"]
适应新词,如 "unhappiness" -> ["un", "happiness"]
基于Sub-word的分词算法不会将常用词拆分为更小的子词。而是将稀有单词拆分为更小、有意义的子单词。例如,“boy” 没有被拆分,但 “boys” 被拆分为 “boy” 和 “s”。这有助于模型了解单词 “boys” 是使用单词 “boy” 构成的,其含义略有不同,但词根相同。
Sub-word Tokenization也包含多种具体的实现算法,在GPT中,广泛使用的是BPE(Byte Pair Encoding).
三、BPE(Byte Pair Encoding)
Byte Pair Encoding(BPE) 是一种 子词(Sub-word)分词算法,广泛用于 NLP 任务,尤其是像 GPT 和 Transformer 这样的深度学习模型。 它通过合并最常见的字符对(bigram),构建灵活的词汇表,以减少未登录词(OOV)问题,并兼顾计算效率。
BPE的执行步骤如下:
1.初始化词汇表:将文本拆分为字符级别的词汇表。
2.统计频率:统计所有相邻字符对的出现频率。
3.合并最频繁的字符对:将出现频率最高的字符对合并为一个新的符号,并更新词汇表。
4.重复迭代:重复步骤2和3,直到达到预定的词汇表大小或迭代次数。
举个经典的例子。
假设对语料库统计词频如下:
{“old”: 7, “older”: 3, “finest”: 9, “lowest”: 4}
在开始执行BPE之前,首先需要在每个单词的后面添加一个/w符号,以便算法知道每个单词的结束位置。这有助于算法浏览每个字符并找到最高频率的字符配对。稍后将看到它的具体作用。
现在来逐步执行BPE。
-
第一步、拆分成字符并统计词频:
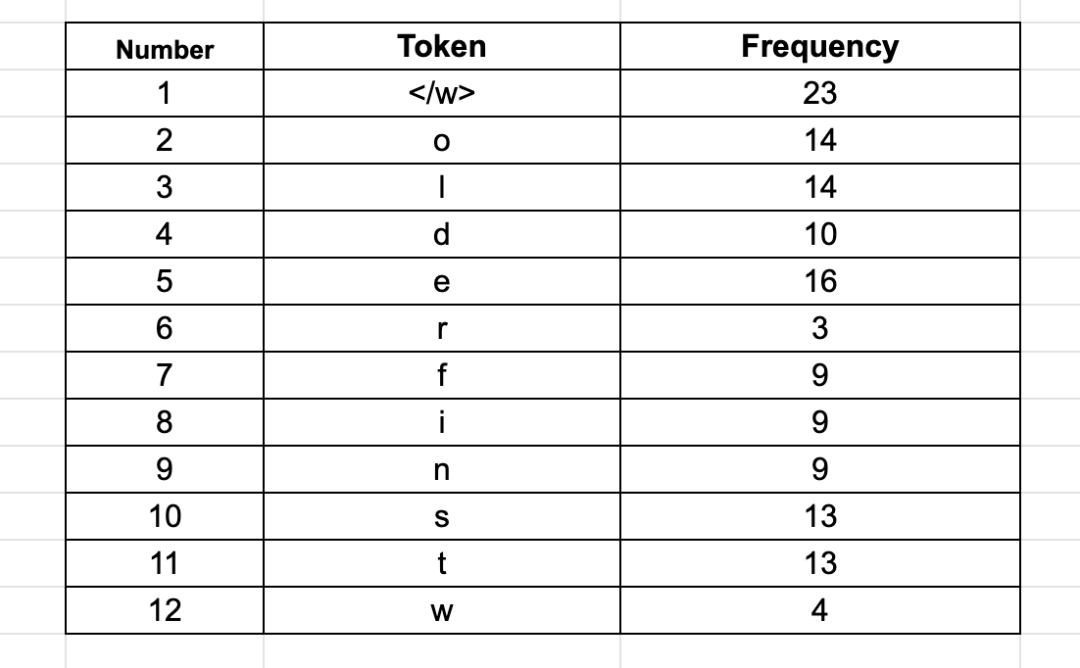
-
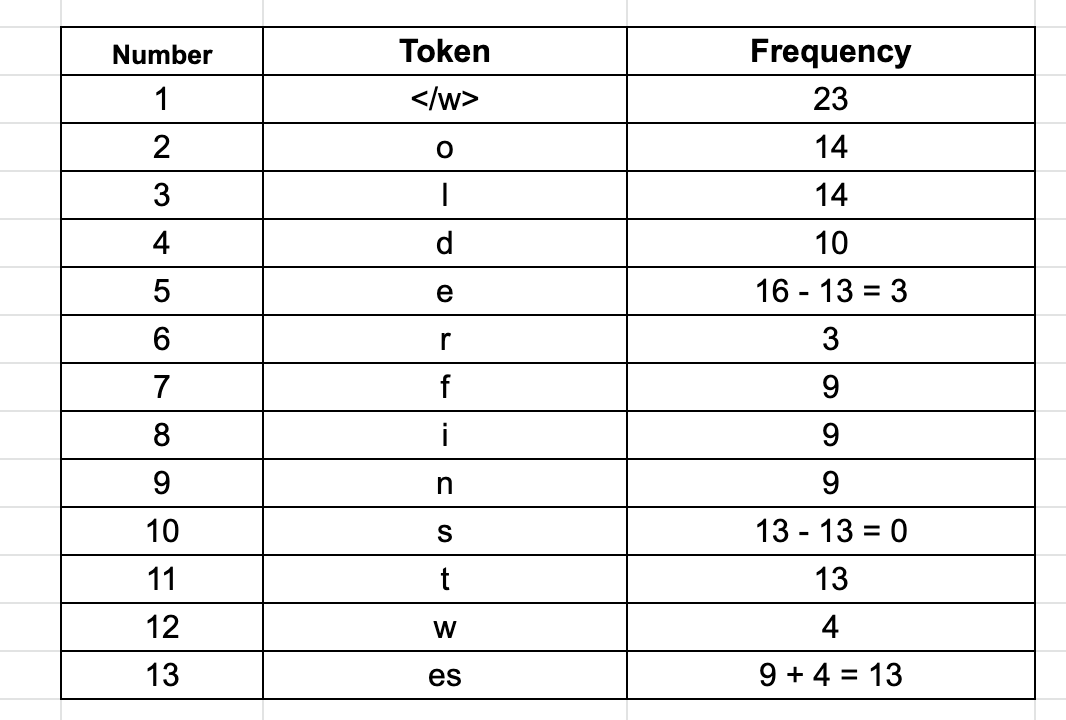
第二步、查找最频繁的配对字符,然后迭代的合并:
2.1 第一次迭代: 从第二常见的token “e” 开始。在当前例子的语料库中,最常见的带有 “e” 的字节对是 “e” 和 “s” (在单词 finest 和 lowest 中),它们出现了 9 + 4 = 13 次。我们将它们合并以形成一个新的token “es”,并将其频率记为 13。我们还将从单个token(“e”和“s”)中减少计数 13,从而得到剩余的 “e” 或 “s” 。可以看到 “s” 根本不单独出现,而 “e” 出现了 3 次。以下是更新后的表格:
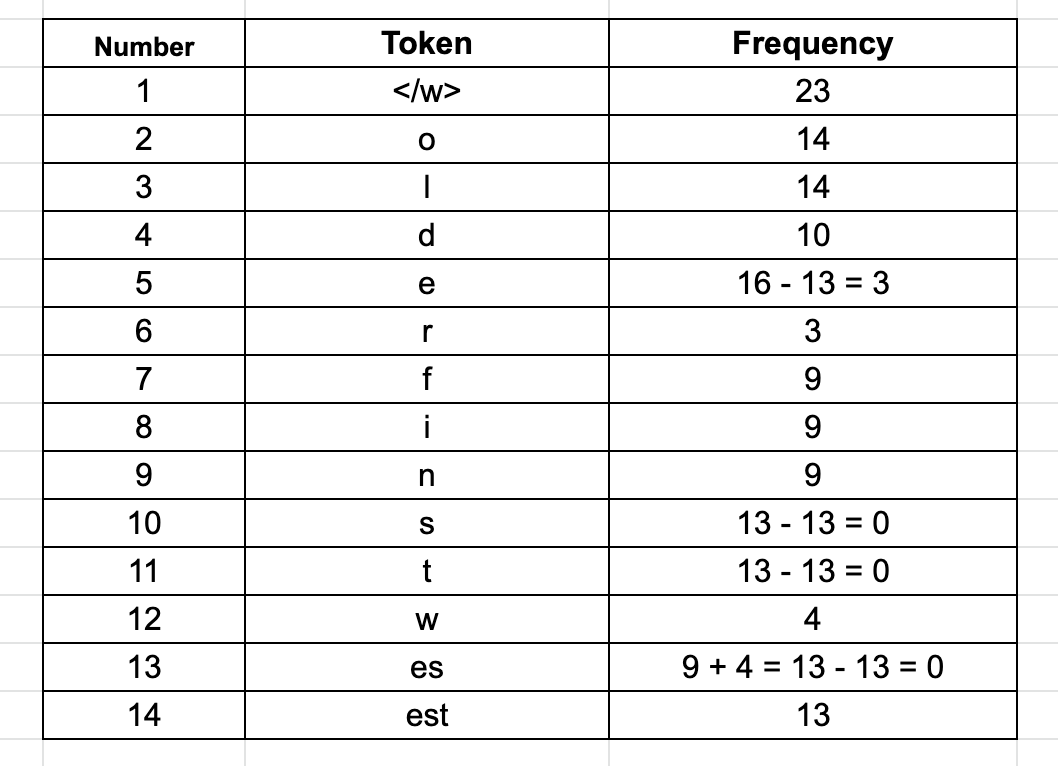
2.2 第二次迭代: 现在,合并 “es” 和 “t”,因为它们在当前例子的语料库中已经出现了 13 次。因此,获得有一个频率为 13 的新token “est”,同时把 “es” 和 “t” 的频率减少 13。
2.3 第三次迭代: 将“est”与“/w”合并
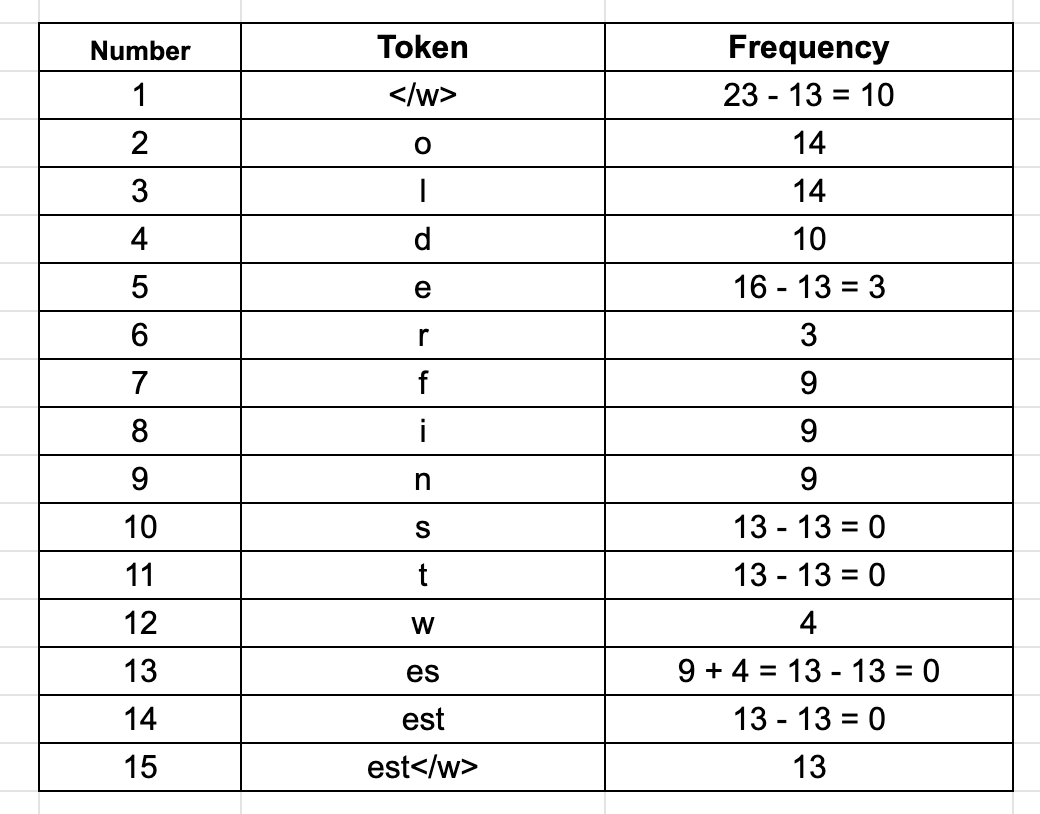
将“/w”合并非常重要,这有助于模型区分“highest”和“estimate”,两者都有“est“,但是前者是“est/w”,表明这是一个单独的token。
2.4 第四次迭代:
查看其他token,可以看到“o”和“l”在当前例子的语料库中出现了 7 + 3 = 10 次。
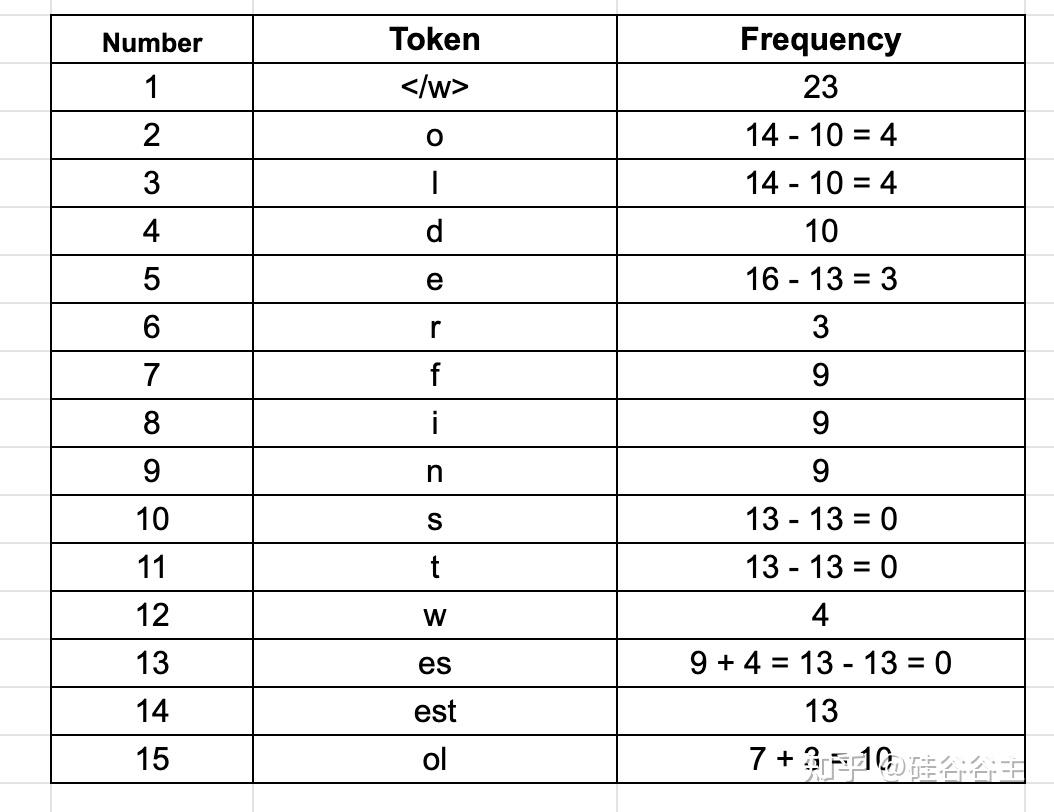
2.5 第五次迭代:
继续,可以看到字节对“ol”和“d”在语料库中出现了 10 次。
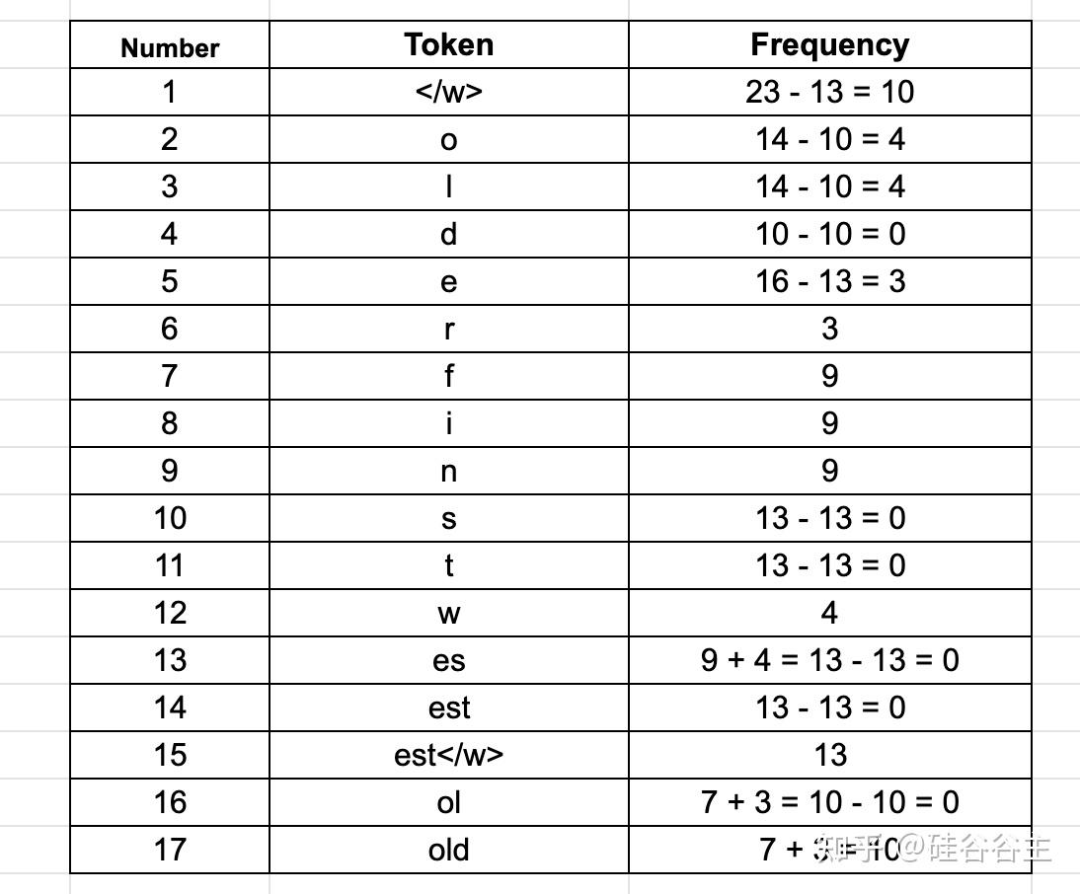
2.6 第六次迭代:
如果现在查看表格,会看到 “f”、“i” 和 “n” 的频率是 9,但只有一个单词包含这些字符,因此这里没有合并它们,最终的token列表如下:
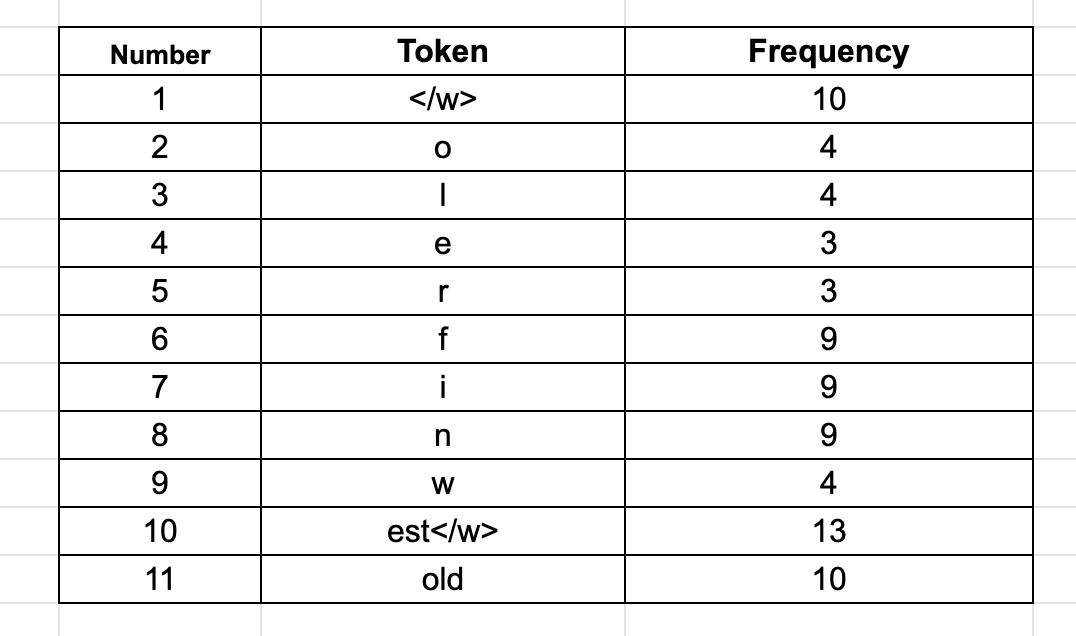
以上便是对BPE的介绍,现在用Python来调用BPE。
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
这样便得到了BPE tokenizer,来尝试一下:
text = (
"Hello, do you like tea? <|endoftext|> In the sunlit terraces"
"of someunknownPlace."
)
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
print(integers)
输出:
[15496, 11, 466, 345, 588, 8887, 30, 220, 50256, 554, 262, 4252, 18250, 8812, 2114, 1659, 617, 34680, 27271, 13]
解码回去:
strings = tokenizer.decode(integers)
print(strings)
输出:
Hello, do you like tea? <|endoftext|> In the sunlit terracesof someunknownPlace.
输出的文本 strings 有一个细微的区别:sunlit terracesof someunknownPlace 中缺少了空格。这个问题出现在词汇表的细粒度拆分上,子词分割可能将 terraces 和 of 合并成了一个词,因此没有在这两个部分之间添加空格。BPE或其他子词分割方法可能将某些词合并成子词序列,这会导致在解码时出现一些合并现象。
四、使用BPE为GPT自回归预训练阶段准备数据集
在GPT自回归预训练阶段,数据集中每个样本是由配对的[输入序列X,输出序列Y]组成的,这样的数据对是使用滑动窗口实现的。
举个例子,假设完整的句子经过BPE得到的token序列为[a,b,c,d,e],滑动窗口的大小为4,那么一个配对样本的格式为:
输入序列X:a,b,c,d
输出序列Y:b,c,d,e
其中,要预测的目标Y是使用滑动窗口将X向右偏移一位得到的。
注意,上述例子中,实际上包含了4个预测过程:
第一个预测过程:
输入a,预测b
第二个预测过程:
输出a,b,预测c
第三个预测过程:
输出a,b,c,预测d
第四个预测过程:
输出a,b,c,d,预测e
也就是说,构建配对数据时的滑动窗口大小等于一个数据对包含的预测过程数量。
现在手动敲代码实现一下上述的数据构建过程。
首先,读取所用到的数据集:
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
enc_sample = tokenizer.encode(raw_text)
print(len(enc_text))#5145
将滑动窗口大小context_size设置为4,构造一个示例的配对样本:
x = enc_sample[:context_size]
y = enc_sample[1:context_size+1]
print(f"x: {x}")
print(f"y: {y}")
输出:
x: [40, 367, 2885, 1464]
y: [367, 2885, 1464, 1807]
这个样本包含的context_size=4个预测过程为:
[40] ----> 367
[40, 367] ----> 2885
[40, 367, 2885] ----> 1464
[40, 367, 2885, 1464] ----> 1807
使用tokenizer解码一下更直观:
for i in range(1, context_size+1):
context = enc_sample[:i]
desired = enc_sample[i]
print(tokenizer.decode(context), "---->", tokenizer.decode([desired]))
输出:
I ----> H
I H ----> AD
I HAD ----> always
I HAD always ----> thought
ok,了解了单个数据对的构造方法,就可以编写一个用于GPT自回归预训练的数据加载器了:
from torch.utils.data import Dataset, DataLoader
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
# Tokenize the entire text
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
# 这里的max_length就是上面所讲的滑动窗口的大小context_size
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
def create_dataloader_v1(txt, batch_size=4, max_length=4,
stride=128, shuffle=True, drop_last=True,
num_workers=0):
# Initialize the tokenizer
tokenizer = tiktoken.get_encoding("gpt2")
# Create dataset
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
# Create dataloader
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers
)
return dataloader
现在,来调用上述函数创建一个数据加载器:
# 读取语料文本
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
# 创建数据加载器
dataloader = create_dataloader_v1(
raw_text, batch_size=1, max_length=4, stride=1, shuffle=False
)
这里的batch_size设置为1,来查看一下数据格式:
data_iter = iter(dataloader)
first_batch = next(data_iter)
print(first_batch)
输出:
[tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])]
现在,让我们调大batch_size:
dataloader = create_dataloader_v1(raw_text, batch_size=8, max_length=4, stride=4, shuffle=False)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Inputs:\n", inputs)
print("\nTargets:\n", targets)
输出:
Inputs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Targets:
tensor([[ 367, 2885, 1464, 1807],
[ 3619, 402, 271, 10899],
[ 2138, 257, 7026, 15632],
[ 438, 2016, 257, 922],
[ 5891, 1576, 438, 568],
[ 340, 373, 645, 1049],
[ 5975, 284, 502, 284],
[ 3285, 326, 11, 287]])
总结
在本文中,我们完成了tokenizer的构建,并基于此tokenizer设计了用于GPT自回归预训练阶段的数据加载器。
至此,数据已经从语料库转变成了PyTorch格式的数据集,可以被批量加载。那么在加载完成数据之后,接下来的数据流向又是怎样的呢?这些内容将在后续文章中继续讨论。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









