







一、安装库
需要安装有bs4、re、xlwt、sqlite3和requests
问题一:pip install request提示报错
ERROR: Could not find a version that satisfies the requirement request (from versions: none)
ERROR: No matching distribution found for request

原因:需要安装的库是requests,不是request!!!
二、利用requests库爬取网页获取数据
链接:https://blog.csdn.net/weixin_43848422/article/details/109246324
三、利用bs4库解析数据
链接:https://blog.csdn.net/weixin_43848422/article/details/109246523
四、实例:爬虫豆瓣电影Top250数据
1.利用requests库得到指定一个URL的网页内容
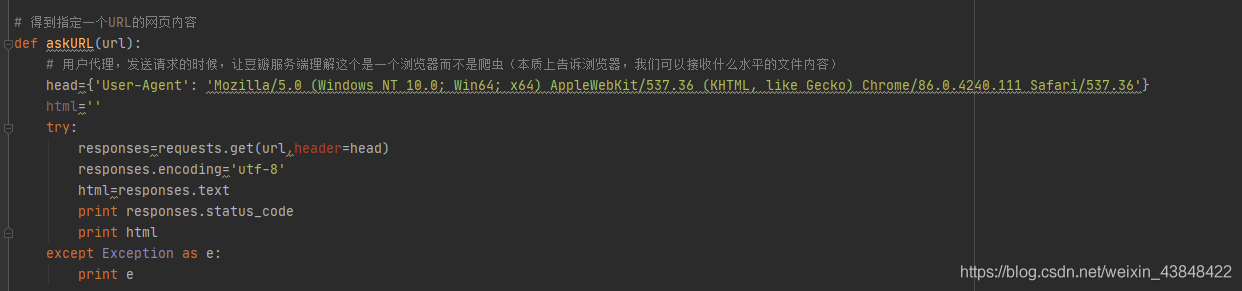
出现报错:request() got an unexpected keyword argument ‘header’
原因:关键字‘header’错误,应为**‘headers’**
修正后代码为&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2787
2787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









