







前言:
- 本文章主要是对 慕课网上的老师视频讲解的计算机基础知识进行简要的记录。以及自己在学习编程后很久后,渐渐地想到,或者是渴望去了解这些计算机基础内容, 听到老师讲到的知识点后,有哪些触动,和感悟。
书(计组,操作系统,计网)中很多东西都有详细记载并且学习过,所以很多内容便没有去加以赘述和记录。
为什么要学习计算机基础?
- 我的个人理解,计算机基础得学习,有助于对编程整体的进行理解,并且很多东西都是触类旁通的。 刚开始学编程的时候并不是很重视这些,但是慢慢的,当一直编程到一定深度的时候,就会主动的想去了解这些内容。 比方说 我所学的Python语言,作为高度封装的语言,但护短开发方向,包括数据库,Redis,网络编程,并发编程等,还要深入的去理解一个语言的设计和底层,是离不开这些东西的。
- (1)Python语言中的 虚拟机,运行时,就像是一颗软件CPU,包括字节码的。
- (2) 计算机网络,Python只需几句简单的语句便可以进行网络开发,但是底层封装的“妈都不认识~” ,要想要编好,至少要了解计算机网络原理和结构。包括五种IO模型。
- (3)并发编程就更不用说了, 进程直接涉及到 操作系统对进程的管理。 线程也涉及到用户态线程和 内核态线程,携程也需要懂的 虚拟机的运行机制和切换机制,很相似。 在不用说,执行的所有用户程序,包括我们写的程序,都是基于操作系统之上的!,不懂操作系统的内存管理,也是不行的! 比方说 我在做实验的时候,Python创建两个进程, 操作同一全局变量, 一个自增,一个自减, 打印的变量 地址,是相通的,但是输出时,确是 一个一直加,一个一直减, 你能说清楚里面的原理吗?
- (4)再比如 liunx操作系统, 一切皆文件。 Python在进行文件读写,以及socket网络编程时, 短短的几条语句,底层你知道在干什么吗? 什么是文件描述符?
- 面试时经常问到的,redis缓存和数据库,应该先更新哪一个? 以及缓存淘汰替换策略。 这些不是很像
计算机组成原理中的 替换策略还有,cache的写策略吗? - (5)触类旁通! ,借鉴计算机基础当中的优秀设计!运用到工作和实践当中。
- 比如工作中需要设计一个应用层的协议,那么可以参考 TCP协议的可靠性,UDP协议的不可靠性。 还有七层模型的分层设计思想,每层之间向上提供服务,并且 逻辑上,保证每层之间是直接 通信,忽略下层!
- 在比如设计缓存框架的时候,可以借鉴操作系统的存储管理或者是缓存的淘汰机制!(我面试当中被问到了 redis的缓存淘汰机制~ 嗨,触类旁通。)
- 还有很多东西,都是参考计算机基础设计的优秀!
计算机组成原理
数字的表示
- 不谈定点数,浮点数,还有计算时溢出啥的。 我们主要讲一下
原码,反码,补码,以及位运算。在很多时候编程时采取这些位运算,是要比直接计算要高效的,并且力扣中,很多问题也是可以采用位运算的。 - 补码的作用:计算机中负数是使用补码来表示的
- (1)统一数字0的表示
- (2) 简化整数的加减法计算
# 补码的作用:
"""
1. 统一数字0的表示。
2. 简化整数的加减法计算。
补码 = 反码 + 1(正数的原码反码,补码等于本身), 反码 = 除符号位以外,按位取反。
在原码中0有两种表示方式:[+0]原=00000000,[-0]原=10000000。
在反码表示中,0也有两种表示形式:[+0]反=00000000,[-0]反=11111111。
在补码表示中,0有唯一的编码:[+0]补=00000000,[-0]补=00000000。
补码是00000000,十进制数值为0
在进行计算的时候,简化计算。任何形式的计算,都可以转化为加法。 比如 -5 - 6, 5 + (-6)等
负数在计算机中以补码形式表示:
上面两个可以转换为 [-5]补 + [-6]补 = [结果]补码 [5]补 + [-6]补 = [结果]补
以第二个为例子:int 32位整数有符号
# 第一位表示符号位
5: 0000 0000 0000 0000 0000 0000 0000 0101
6: 1000 0000 0000 0000 0000 0000 0000 0110
补码:(整数不变,负数为取反加1)
[5]补: 0000 0000 0000 0000 0000 0000 0000 0101
[-6]补:1111 1111 1111 1111 1111 1111 1111 1010
那么,[5]补 + [-6]补 = [结果]补 (溢出情况不考虑)
0000 0000 0000 0000 0000 0000 0000 0101
1111 1111 1111 1111 1111 1111 1111 1010 +
-------------------------------------------------
1111 1111 1111 1111 1111 1111 1111 1111
补码-1再取反就得到结果为:-1
1000 0000 0000 0000 0000 0000 0000 0001
"""
- 位运算
- 位运算的基本概念
# 有符号整数,无符号整数
"""
如 -4(int 类型有符号) 二进制表示为: 最高位为符号位,1代表-, 0代表正
无符号整数,自然没有符号位,只能表示整数,当然多了一位,表示的数字范围也会大
1000 0000 0000 0000 0000 0000 0000 0100
"""
# 位运算,都是指在计算机中的二进制表示运算。 负数表示为 补码形式
# 得出结论: 左移和符号位没有关系。符号位都都不动的
# 得出结论:正数右移和 符号无关
# 得出结论: 负数的有符号右移 高位补1, 无符号高位补0,和符号位有关
"""
按位与(&): 同1出1,其他出0 : 有个经典的例子,Python中计算字典的hash表,计算存储位置时,需要对hash值进行取模运算。
但是当取模的数字是 2的倍数时,就可以替换为 & 运算。比如 18 % 8 , 等价于 18 & (8-1)
因为 7 的二进制位 0111 1111 ,&7, 就只剩下后七位为1的了,自然等于取模运算
按位或(|): 有1出1, 没1出0
按位异或(^): 同出0, 异出1
按位取反(~): 指将两个二进制数的每一二进位都进行取反操作, 0 换成 1 , 1 换成0
左移(有符号)(<<), 有符号右移(>>), 无符号右移(>>>)python中没有这个无符号右移运算符,默认有符号
举例子 int(4)(都是默认有符号的)
4: 0000 0000 0000 0000 0000 0000 0000 0100
4 << 2, 左移2
0000 0000 0000 0000 0000 0000 0001 0000 (右边低位空出来补0)
= 16
-4: 1111 1111 1111 1111 1111 1111 1111 1100
-4 << 2, 左移 2
1111 1111 1111 1111 1111 1111 1111 0000
= (补码-1 取反得到原数字) 1000 0000 0000 0000 0000 0000 0001 0000 = -16
得出结论: 左移和符号位没有关系。符号位都都不动的。
15: 0000 0000 0000 0000 0000 0000 0000 1111
15 >> 2, 有符号右移2
0000 0000 0000 0000 0000 0000 0000 0011 (右边空出补0)
= 3
15 >>> 2, 有符号右移2
0000 0000 0000 0000 0000 0000 0000 0011 (右边空出补0)
= 3
得出结论:正数右移和 符号无关
-15:1111 1111 1111 1111 1111 1111 1111 0001 (补码表示)
-15>>2, 有符号右移2
1111 1111 1111 1111 1111 1111 1111 1100 (前面空出补 1)
= 取反加1 = -4
-15 >>> 2 无符号右移2( 不将最高位当做符号位)
0011 1111 1111 1111 1111 1111 1111 1100 (空缺补0)
= 这是个很大的整数
得出结论: 负数的有符号右移 高位补1, 无符号高位补0
"""
# 有符号整数二进制规律
"""
前面提到的int有符号整形是 32位。那么还有其他形式
4 位的:最高一位表示符号位
0000 0
0001 1
0010 2
0011 3
0100 4
0101 5
0110 6
0111 7
1000 ?---> 表示负数,使用补码。 --> 减1 --> 1111 --> 1000 --> -8 有点绕, 1000表示8,但是是负数,那就是-8
表示范围是 -2^3 -- 2^3 - 1
"""
- 位运算技巧
# 位运算技巧
"""
(1). 拿到一个数字二进制的低16位:假设数字是 n
n & 0xFFFF FFFF代表16个1, 相&, 就是获取低16位了
(2). 对二进制的高16位进行取反:
假设 n: 0000 1010 0001 0000 1111 0010 0000 1010
n ^ 0xFFFF (异或)
0000 1010 0001 0000 1111 0010 0000 1010
0000 0000 0000 0000 1111 1111 1111 1111
-------------------------------------------
0000 1010 0001 0000 0000 1101 1111 0101 # 1. 相当于高16位不变,低16位取反
# 2. 再对整个 n 取反,就得到 高16位取反(因为低16位取反就变成原来的值了)
~n
总结: 这里的 0xFFFF 的作用就相当于是掩码(mask)
(3). 测试i+1位是否为1
原理很简单。假设 n: 0000 1010 0001 0000 1111 0010 0000 1010
测试第1位是否位1
n & (1>>1)
0000 1010 0001 0000 1111 0010 0000 1010
0000 0000 0000 0000 0000 0000 0000 0001
------------------------------------------
0 得到0 说明这一位不是1
同理测试第 i+1位是不是 0, 只需要 n & (i << i) != 0 就可以判断出来, 左移i 位, 来判断
(4). 去掉n的最后一位1
很简单,直接n & n - 1 即可
(5). 获取最后一位 1:
n & -n
n & ~(n-1)
n^(n&(n-1))
(6) A的位减去 B的位: A & ~B
就是 全部化为二进制相减。 对应的位相减,没有进位,借位。
1 - 1 = 0
0 - 1 = 0
1 - 0 = 1
0 - 0 = 0
(7) ^ 的用法技巧
a ^ 0 = a
a ^ a = 0
# 满足交换律(数字逻辑电路~~~学过这样的题去化简)
a ^ b ^ c = a ^ c ^ b
"""
- 位运算的一些高频算法题
- 关于计算机组成原理中讲的,如何进行两个二进制数的加法计算,具体可以参考这一片的博客讲解:
(1)冯诺依曼
- 运算器,控制器,存储器,输入设备,输出设备
(2)系统总线
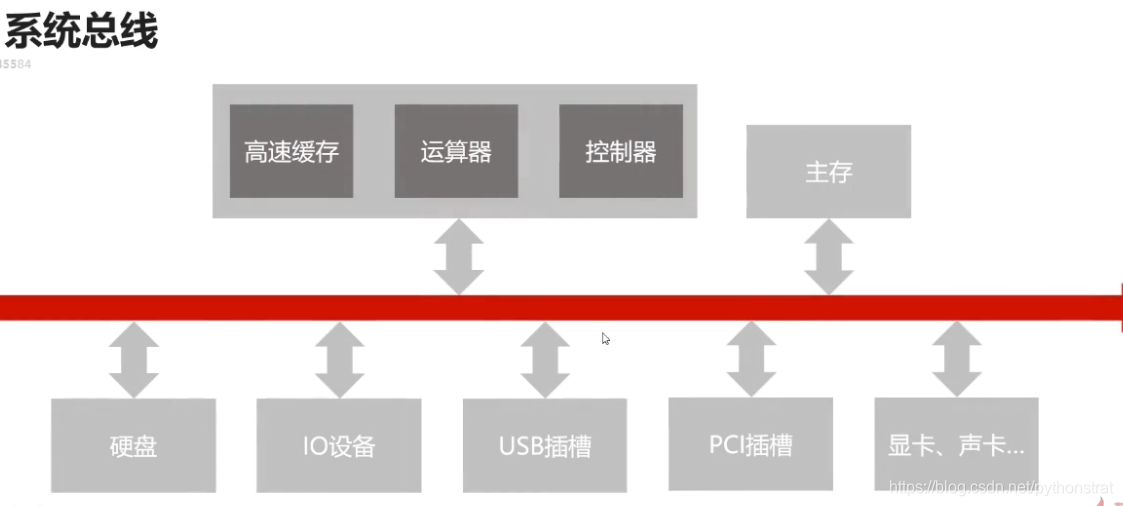
- 数据总线
- 一般位数和CPU位数是相同的(32位,64位)
- 双向传输各个部件的数据信息
- 数据总线的位数(总线宽度)是数据总线的重要参数。 如果是64位,则一次可以传输 64位,8byte(字节)的数据。
- 地址总线
- 用来传输数据的地址,用来寻址。指定源数据或目的数据在内存中的地址。
- 地址总线的位数与存储单元有关。如果地址总线的位数=n, 则寻址范围为 0~2^n,这个不难理解。
- 控制总线
- 发出各种控制信号的传输线
- 控制信号经由控制总线从一个组件发给另一个组件。例如,从CPU到键盘, CPU到主存等。
- 可以监视不同组件之间的状态(就绪/未就绪)
总线的仲裁
- 仲裁器,目的就是解决 使用总线的优先顺序的一个设备,也就是解决总线使用权的冲突问题。
- 总线冲裁的方法:
- 链式查询
- 设备依次呈链状链接。 当请求使用数据总线时,就会向仲裁控制器请求,然后依次使用。
- 计时器定时查询
- 独立请求
- 链式查询
DMA(直接存储器访问)
- CPU与IO设备的通信,CPU和IO设备的访问速度是不一样的
局部性原理(重要)
- 局部性原理是指CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。这是个很重要的概念,就是因为有这个理论,才有各种缓存的出现,并使计算机高效的运行。
计算机的高速缓存
高速缓存的工作原理
- 字: 是指存放在一个存储单元中的二进制代码的组合。字可以表示一个数据,一条指令,或者是一个字符串。字是内存中存储单元最小的单位。
- 字块:存储在连续的存储单元中,而被当做是一组字的集合。
- 假设:一个字有 32位, 一个字块有B个字, 主存共M个字块。
- 那么总字数为: B * M
- 主存总容量为:BM32 (单位是bit)
- 字的地址:
- 因为有了字和字块的概念,所以字的地址就包含两个部分组成了
- (1) 前m位指定字块的地址
- (2)后b位指定字在字块中的地址。
- 且有: 2^m = M。 2^b = B

- 命中率:
- 命中率是衡量缓存的重要性能指标。
- 理论上CPU每次都能从高速缓存去数据的时候,那么命中率为1。
- 命中率的计算: 假设访问主存 N次, 访问缓存M次。则 命中率h = M/(N + M)
- 访问时间平均时间与访问效率:
- 假设 访问效率:e ,访问主存时间为 t1, 访问缓存时间为 t2。
- 则访问 Cache-主存系统的平均时间为: *t = h*t2 + (1-h)t1
- Cache-主存系统的的平均效率 e = t2 / t
高速缓存的替换策略(redis面试被问到。也有缓存的替换策略)
-
FIFO,LFU,LRU的代码实现,请点击这里!!!
-
合理的缓存替换策略,才能尽量保证换粗你的高效命中率
-
(1)随机算法
-
(2)先进先出算法(FIFO)
- 把高速缓存看做是一个先进先出的队列
- 优先替换掉最先进入队列的字块
-
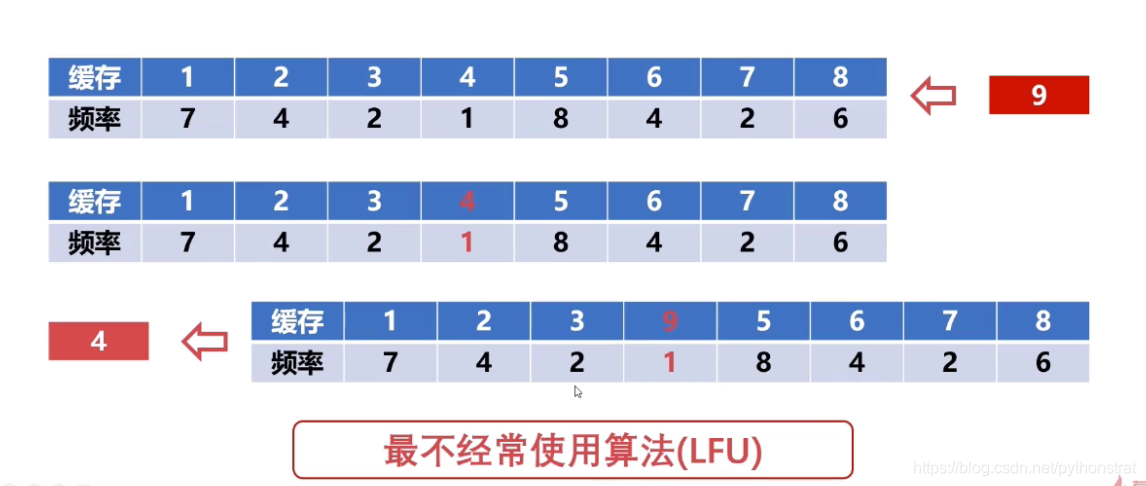
(3)最不经常使用算法(LFU)
- 优先淘汰最不经常使用的字块。
- 需要额外的空间记录字块的使用频率,当需要发生替换的时候,优先替换掉频率最低的 字块。
-
(4)最近最少使用算法(LRU)
-
优先淘汰一段时间内没有使用的字块
-
有多种实现方法,一般使用双向链表
-
把当前访问节点置于链表前面(保证链表头部节点是最近使用的),当需要淘汰时,就淘汰尾部的节点即可。

计算机的指令系统
机器指令的形式
- 机器指令主要由两个部分组成: 操作码和地址码
- 操作码: 指明指令所要完成的操作。
- 操作码的位数,反映了机器的操作种类。
- 假设操作码为 8位,则对应的操作有 2^8 = 256种
- 地址码: 直接给出操作数或者操作数的地址
- 分为 三地址码指令(地址码字段有三个地址), 二地址码指令(两个地址)和一地址码指令(一个地址)。
- 如三地址指令的形式: 主要完成的是 (addr1)OP(addr2)-> (addr3)。
将addr1,addr2 地址的数据取出,进行操作,将结果保留到 addr3

- 二地址:(addr1)OP(addr2)-> (addr1)or(addr2)
- 一地址:(addr1)OP -> (addr1) 或者 (addr1)OP(ACC) -> (addr1) 例如自增操作。
- 无地址码:
- 空操作,停机操作,中断返回操作等,都不需要地址码。
机器指令的操作类型
- 数据传输类型:
- 寄存器之间,寄存器与存储单元(高速缓存或者主存或者硬盘等),存储单元之间
- 数据读写, 交换地址数据,清零置一等操作。
- 算数逻辑操作:
- 操作数之间的加减乘除运算
- 操作数的与或非等逻辑运算
- 移位操作:
- 数据左移(乘2),数据右移(除2)
- 是完成数据在算术逻辑单元的必要操作。
- 控制指令:
- 等待指令,停机指令,空操作指令,中断指令等
机器指令的寻址方式
-
指令寻址
- 顺序寻址
- 跳跃寻址

-
数据寻址
-
立即寻址
- 指令直接获得操作数,指令里包含操作数,无序访问存储器。

- 指令直接获得操作数,指令里包含操作数,无序访问存储器。
-
直接寻址
- 机器指令里面直接给出操作数在主存的地址。
- 寻找操作数简单,无需计算数据地址。

-
间接寻址
- 指令地址码给出的是操作数地址的地址。
- 需要访问一次或多次主存来获取操作数。

-
-
三种寻址方式的比较:

计算机的控制器
- 控制器是协调和控制计算机运行的
- 程序计数器
- 用来存储下一条指令的地址
- 循环从程序计数器中拿出指令
- 当指令被拿出时,指向下一条指令
- 时序发生器
- 电气工程领域,用于发送时序脉冲
- CPU依据不同的时序脉冲有节奏的进行工作
- 指令译码器
- 指令译码器是控制器的重要部件之一
- 计算机指令由操作码和地址码组成
- 翻译操作码对应的操作,发出控制信号。对于地址码,会控制传输 地址码,及对应的操作数据。
- 各种寄存器
- 指令寄存器
- 从主存或者高速缓存取计算机指令
- 主存地址寄存器
- 保存当前CPU正要访问的内存单元的地址
- 主存数据寄存器
- 保存当前CPU正要读或写的主存数据
- 通用寄存器
- 用于暂时存放或传送数据或指令
- 可保存ALU(只要指加法器)的运算中间结果
- 指令寄存器
- 总线
计算机的运算器
- 主要进行数据的运算加工
- 数据缓冲器
- 输入缓冲:暂时存放外设送过来的数据
- 输出缓冲: 暂时存放送往外设的数据
- ALU:算数逻辑单元
- 完成常见的位运算(左右移,与或非等)
- 算术运算(加减乘除等)
- 通用寄存器
- 暂时存放或传送数据或指令
- 可保存ALU的运算中间结果
- 状态字寄存器
- 存放运算状态(条件码,进位,溢出,结果正负等)
- 存放运算的控制信息(调试跟踪标记位,允许中断位等)
- 总线
操作系统
(1)死锁:
- 定义:
一组进程中的每个进程都在等待仅由该组进程中其他的进程才能才能引发的事件,那么该组进程是死锁。
死锁产生的必要条件(缺一个就不会产生死锁)
- (1)互斥条件: 进程对所分配的资源进行排他性的使用。一段时间里该资源只能有一个进程占有,其他进程需等资源释放后才能请求获取该资源。
- (2)请求和保持条件:进程至少保持了一个资源,又提出了新的资源请求。此时可能请求的新资源已被其他进程占有,此时该进程陷入阻塞,但对自己已经获得的资源保持不放。
- (3)不可抢占条件:进程已获得的资源在未使用完之前不能被抢占,只能等该进程使用完后自己释放。
- (4)循环等待条件:也就是产生环形的进程–资源链,下面的(2)中所面熟的那样,相互循环请求对方的资源,产生环状。
死锁的产生
- (1) 竞争不可抢占式资源引起死锁
- 假设系统中两个进程 P1,P2还有两个可操作的文件F1,F2,这两个文件都属于可重用和不可抢占性资源。两个进程都要对文件进行写操作。都有如下代码:
P1 p2
... ...
open(f1, w) open(f2, w)
open(f2, w) open(f1, w)
... ...
当P1,P2并发执行的时候,P1首先打开f1, 而P2恰好打开f2. 那么此时就会出现问题,
当P1去试图打开f2时,恰好P2又试图打开f1,这个时候就会出现互相等待对方释放资源的情况,一直等待下去,从而产生死锁。
- (2)竞争可消耗资源引起死锁
- 这里假如说有三个进程P1,P2,P3。同时他们生产 m1,m2,m3 三块资源。并且是环形需求的, P1 -->(生产)m1 --> P2(接收m1) --> (生产)m2 --> P3(接收m2) --> (生产)m3 --> P1(接收) 对这样的环形相互需求。如:
P1: ...receive(P3, m3) send(p2, m1);...
P2: ...receive(P1, m1) send(p3, m2);...
P3: ...receive(P2, m2) send(p1, m3);...
1. 当出现三者都先 生产再发送,可以一直正常执行下去
2. 当出现上面的情况,三者都先进行 等待接收资源,那么必然会出现互相死等的情况,谁都等不到。
- (3) 进程的调度顺序不当
- 说到底就是和(1)类似。 进程之间正确的执行顺序,合理的互相合作,利用资源。但当进程的调度顺序不对,就会导致资源的竞争,双方陷入死锁状态。
死锁的处理
- 避免死锁: 银行家算法。

















 4742
4742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









