







 本文介绍了如何使用Python 3.6和相关模块来爬取新闻网站的数据,包括标题、内容、日期以及图片。通过解析静态网页,将信息保存为PDF和CSV文件,图片则保存到本地。详细步骤包括确定目标网页、请求网页、解析数据和文件保存。
本文介绍了如何使用Python 3.6和相关模块来爬取新闻网站的数据,包括标题、内容、日期以及图片。通过解析静态网页,将信息保存为PDF和CSV文件,图片则保存到本地。详细步骤包括确定目标网页、请求网页、解析数据和文件保存。
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
基本开发环境
- Python 3.6
- Pycharm
import requests
import parsel
import pdfkit
import csv
import threading
相关模块pip安装即可
确定目标网页

获取数据
- 标题
- 内容 保存成PDF
- 日期
- 图片 保存本地
- 详情页url、日期、图片地址等等 保存csv
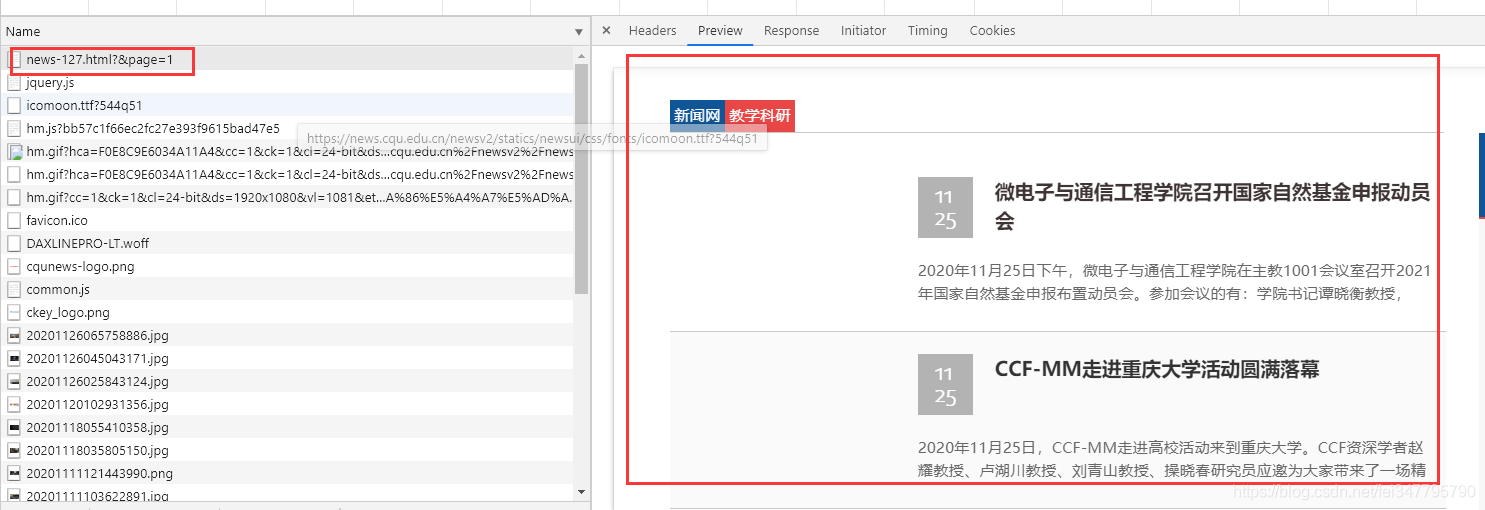
网站是静态网页,没有什么难度
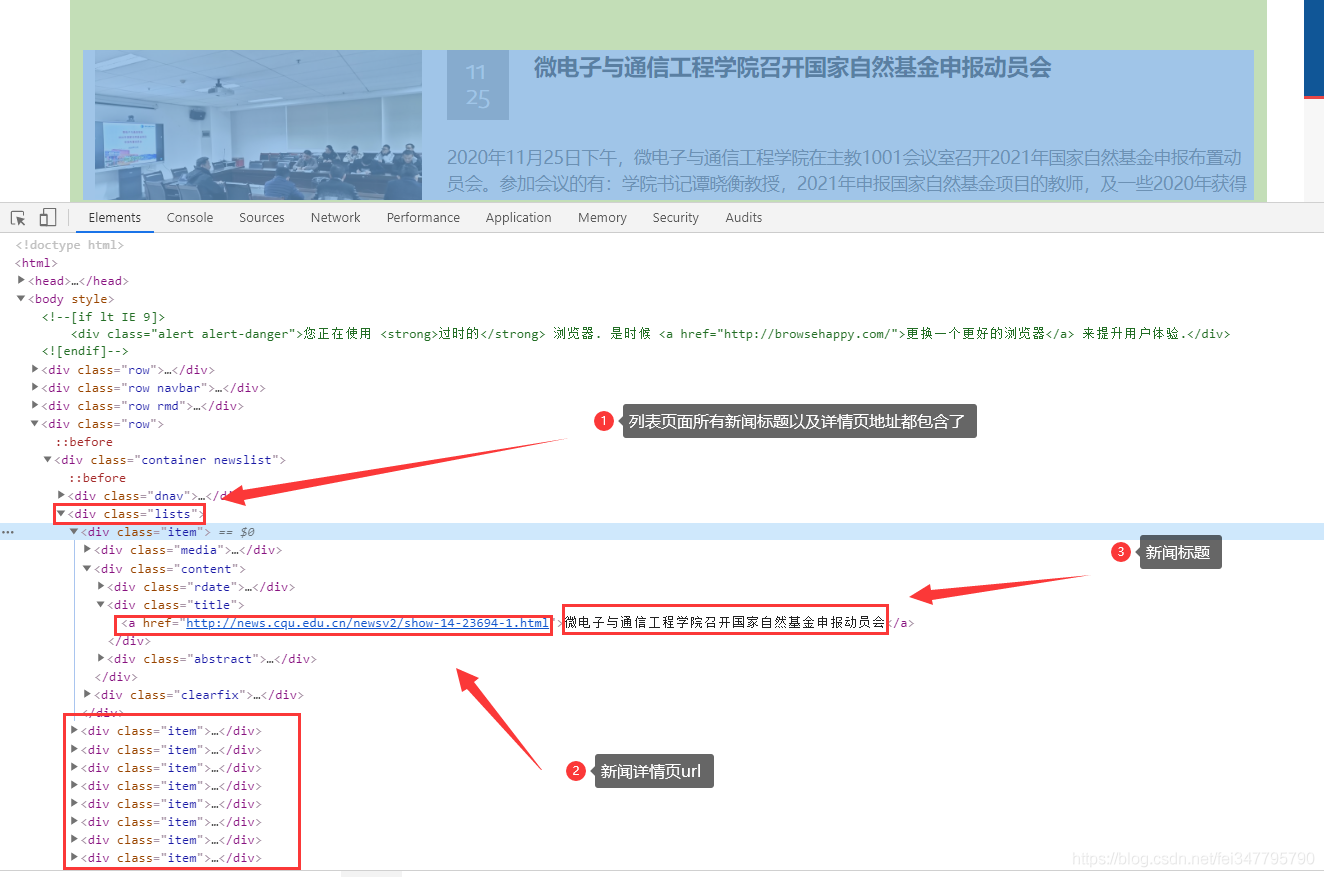
详情页
同样是静态页面
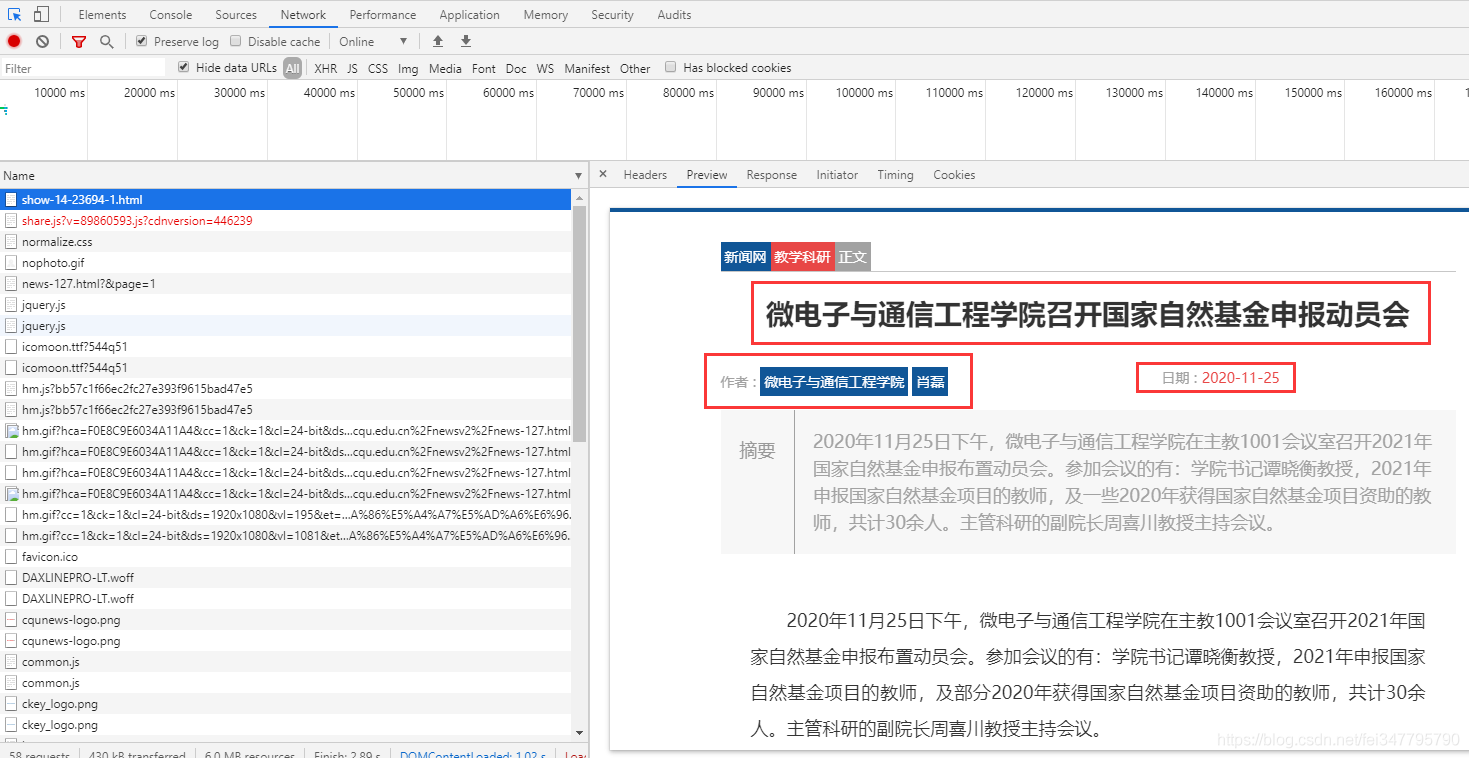
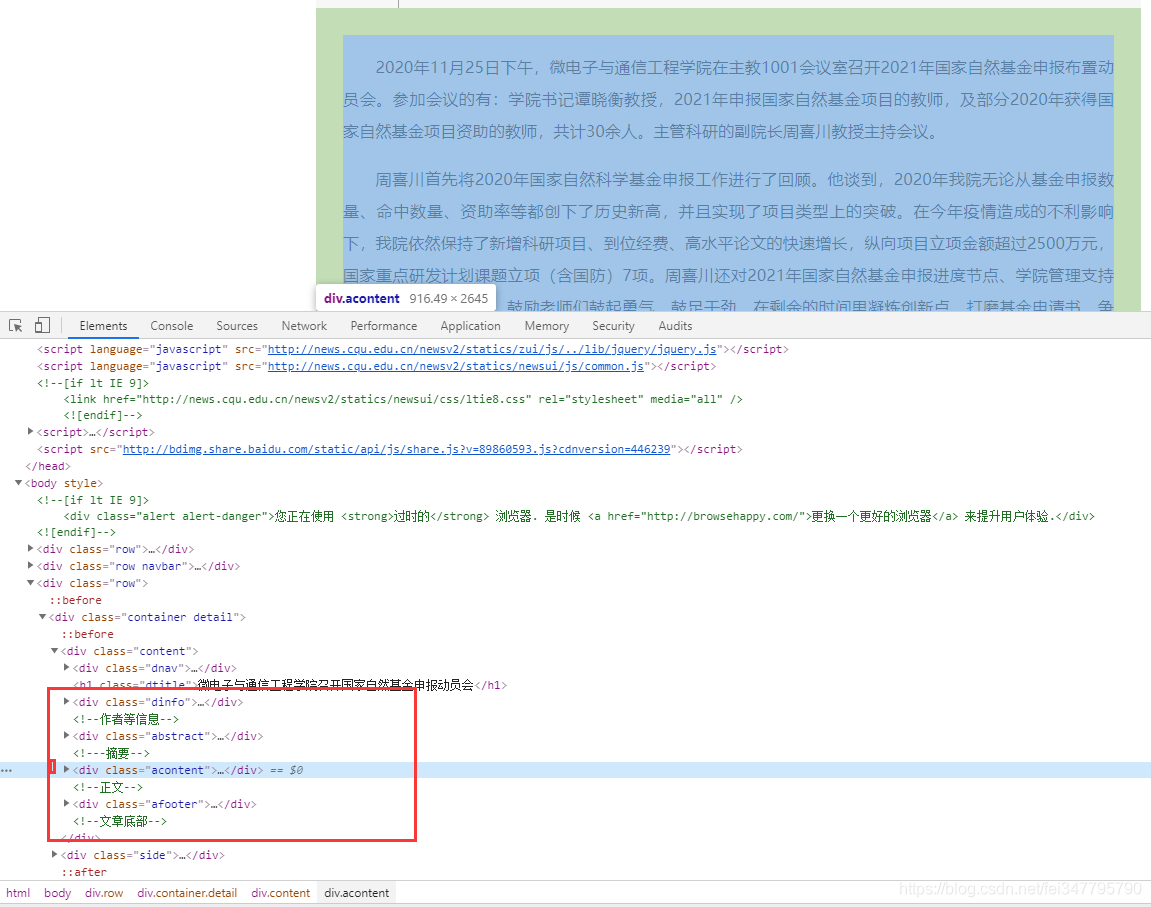
网页源代码已经说明数据在什么地方了,利用相关的解析工具,对网页数据进行解析即可。
代码实现
- 请求网页以及解析
def get_html(html_url):
response = requests.get(url=html_url, headers=headers)
return response
def get_pars(html_data):
selector = parsel.Selector(html_data)
return selector
- 保存内容 PDF格式
html_str = """
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
{article}
</body>
</html>
"""
def save_article(article, title):
html_path =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









