






Redis持久化配置
简介

Redis 提供了两种不同级别的持久化方式:RDB和AOF,可以通过修改redis.conf来进行配置.
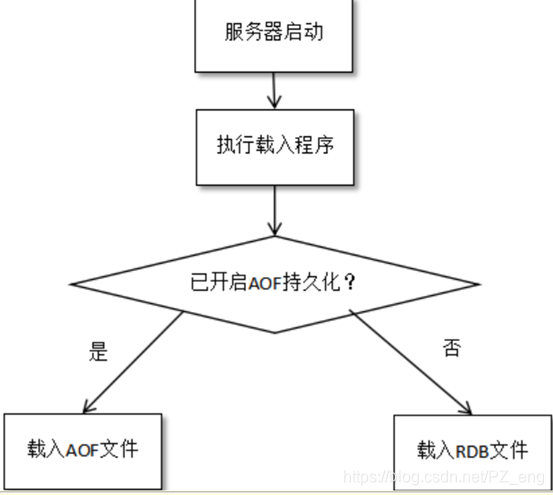
当满足持久化条件时,会进行持久化保存,还来不及保存的数据,会以aof日志的方式保存下来。Redis启动时,先解析日志文件(一堆命令),恢复数据。然后还要加载rdb文件(取并集)。
RDB模式
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照,默认开启该模式.
如何关闭 rdb 模式:
save “”
#save 900 1 //至少在900秒的时间段内至少有一次改变存储同步一次
#save xxx
#save 60 10000
AOF日志追加模式
AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集,默认关闭该模式。
如何开启aof模式:
appendonly yes //yes 开启,no 关闭
#appendfsync always //每次有新命令时执行一次fsync,就将缓冲区的数据放入aof文件
#这里我们启用 everysec
appendfsync everysec //每秒 fsync 一次
#appendfsync no //从不fsync(交给操作系统来处理,可能很久才执行一次fsync)
其它的参数请大家看redis.conf配置文件详解
如果满足保存策略,就会把内存的数据保存到数据文件中,还来不及保存那部分数据存放到更新日志中。在加载时,会把两个数据做一个并集。
Redis高级
redis集群
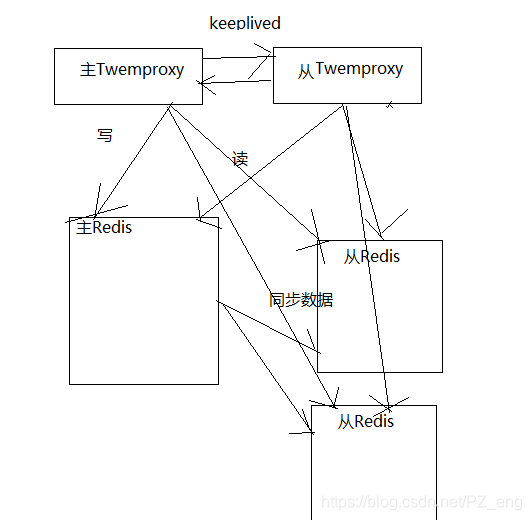
为啥要集群,一台服务器内存有限,存放的数据太多不能满足。多台服务器做集群,可实现高并发。
Redis Spring集成
一般项目总都是有Spring,我们使用jedis访问reids时,所有要jedis被Spring管理。集群原理就是把核心对象交给Spring管理。
Jedis核心对象:配置文件,连接池配置对象,连接池。
集成方式有两种:
Spring data-redis
自己封装(自己封装)
导入jar包
准备配置文件,配置核心对象
加载配置文件
连接池配置对象
连接池对象
管理连接对象
操作crud模板
把配置文件集成Spring–以外部文件的方式进行导入
测试
通过crud模板操作redis
Redis经典实用场景-缓存
- 为什么要使用缓存
把经常查询的数据,很少修改的数据存放到缓存中,减少访问数据库,降低数据库压力并且缓存一般都是内存,访问速度比较快。
- 哪些数据适合放到缓存中
经常查询:缓存就是提供数据查询高效访问。
很少修改:修改时要同步修改缓存和数据库
例如:地区数据、商品分类、数据字典 菜单(不考虑权限)
- 选择合适的缓存
Hibernate二级缓存,mybatis二级缓存,redis中央缓存
Hibernate二级缓存,mybatis二级缓存默认不支持集群缓存,要使用redis
- 怎么存储数据
1) json:把要存放的数据转换为json类型的字符串
保存缓存时:
Java Object----------->json字符串
获取缓存:
json字符串-------->Java Object-
Json框架:jdk-json-lib jackson gson fastjson(阿里巴巴)
2)二进制存放:把要存放的数据序列化为二进制
序列化框架实现
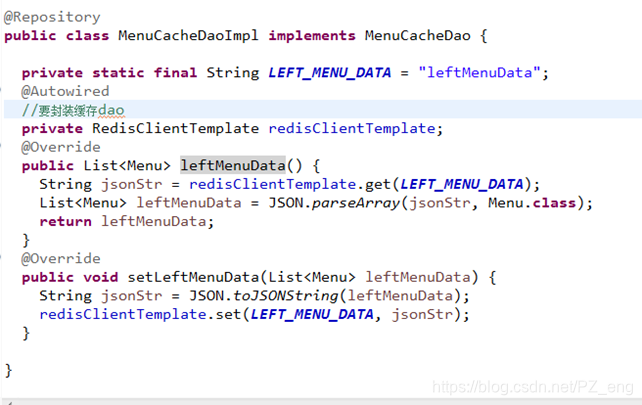
- 实现菜单缓存
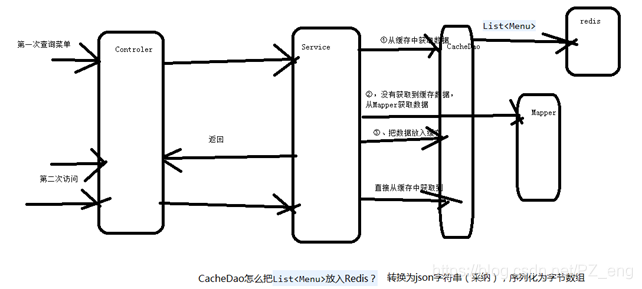
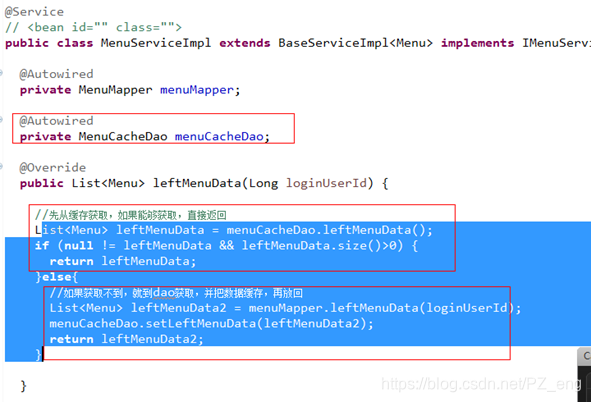
淘汰策略
- 为什么要淘汰数据
淘汰一些数据,达到redis数据量都是有效的。选择合适的淘汰策略进行淘汰.
- 怎么淘汰
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意(随机)选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据(不删除任意数据.默认策略,但redis还会根据引用计数器进行释放),这时如果内存不够时,会直接返回错误)
redis 确定驱逐某个键值对后,会删除这个数据并,并将这个数据变更消息发布到本地(AOF 持久化)和从机(主从连接)。














 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









