







自定义编码器解码器
通过一个简单案例,我们自己去实现一个编码器 和解码器
实现思路
- 编码器(Encoder)实现:
- 在编码器中,实现了
ByteToMessageCodec<Message>类,并覆盖了encode()方法来处理消息的编码。- 在
encode()方法中,首先写入协议的标识、版本号、序列化算法类型、消息类型、请求序号等信息。然后,将消息对象转换为字节数组,并写入到输出的ByteBuf中。- 解码器(Decoder)实现:
- 创建了一个继承自
ByteToMessageCodec<Message>的解码器,并实现了decode()方法来处理消息的解码。- 在
decode()方法中,从输入的ByteBuf中读取协议的标识、版本号、序列化算法类型、消息类型、请求序号等信息。然后,根据序列化算法类型,你反序列化字节数组为消息对象,并将解码后的消息放入到解码器的输出列表中。- 消息类(Message)设计:
- 定义了一个抽象的
Message类作为所有消息的基类,并规定了消息类型常量和消息类型与消息类的映射关系。- 每个具体的消息类都继承自
Message类,并实现了getMessageType()方法以及其他必要的属性和方法。- 测试程序:
- 编写测试程序,使用
EmbeddedChannel来测试编码和解码器的功能。- 在测试程序中,你写入一个登录请求消息,并通过编码器进行编码,然后通过解码器进行解码,最后验证解码后的消息是否正确。
登录请求消息
/**
* 登录请求消息
* 这里我们不再使用继承的方式,而是使用组合的方式
* 这样做的好处是,我们可以更加灵活的控制消息的格式
*/
@Data
@ToString(callSuper = true)
public class LoginRequestMessage extends Message {
private String username;
private String password;
private String nickname;
public LoginRequestMessage() {
}
public LoginRequestMessage(String username, String password, String nickname) {
this.username = username;
this.password = password;
this.nickname = nickname;
}
@Override
public int getMessageType() {
return LoginRequestMessage;
}
}
登录响应消息
/**
* 登录响应消息
*
*/
@Data
@ToString(callSuper = true)
public class LoginResponseMessage extends AbstractResponseMessage {
@Override
public int getMessageType() {
return LoginResponseMessage;
}
}
抽象Message消息类
/**
* 这里的 Message 是一个抽象类,它是所有消息的基类,所有的消息都需要继承自它。
* 这里定义了一些消息类型的常量,以及一个静态的 Map 对象,用来存储消息类型和消息类的映射关系。
* 这样就可以通过消息类型来获取消息类,这样就可以根据消息类型来创建对应的消息对象。
* 这里还定义了一个抽象方法 getMessageType,用来获取消息类型。
* 这样我们就可以通过消息对象来获取消息类型,然后根据消息类型来获取消息类,这样就可以根据消息类型来创建对应的消息对象。
*/
@Data
public abstract class Message implements Serializable {
public static Class<?> getMessageClass(int messageType) {
return messageClasses.get(messageType);
}
private int sequenceId;
private int messageType;
public abstract int getMessageType();
// 登录请求消息
public static final int LoginRequestMessage = 0;
// 登录响应消息
public static final int LoginResponseMessage = 1;
private static final Map<Integer, Class<?>> messageClasses = new HashMap<>();
static {
messageClasses.put(LoginRequestMessage, LoginRequestMessage.class);
messageClasses.put(LoginResponseMessage, LoginResponseMessage.class);
}
}
**继承ByteToMessageCodec 用来处理编解码 **
public class MessageCodec extends ByteToMessageCodec<Message> {
private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());
/**
* 编码
*
* @param channelHandlerContext
* @param message
* @param out
* @throws Exception
*/
@Override
protected void encode(ChannelHandlerContext channelHandlerContext, Message message, ByteBuf out) throws Exception {
// 拿到ByteBuf 往里面写入数据
// 1.魔数,就相当于一个标识,用来标识这是一个自定义的协议(4个字节的魔数)
out.writeBytes(new byte[]{1, 2, 3, 4});
// 2.版本号(1个字节)
out.writeByte(1);
// 3.序列化算法(先使用JDK作为序列化算法) 使用1个字节来表示序列化算法 jdk 0 json 1
out.writeByte(0);
// 4.指令类型(1个字节)
out.writeByte(message.getMessageType());
// 5.请求序号(4个字节)
out.writeInt(message.getSequenceId());
// 写个无意义的字节,是为了对其,填充字节,填充到8的倍数
out.writeByte(0xff);
// 6.获取内容的字节数组
// 将Java对象转为字节属猪
// 创建一个字节数组输出流
ByteArrayOutputStream bos = new ByteArrayOutputStream();
// 创建一个对象输出流
ObjectOutputStream oos = new ObjectOutputStream(bos);
// 将对象写入字节数组输出流
oos.writeObject(message);
// 获取字节数据
byte[] bytes = bos.toByteArray();
// 7.获取字节长度
out.writeInt(bytes.length);
// 8.写入内容
out.writeBytes(bytes);
}
/**
* 解码
*
* @param channelHandlerContext
* @param in
* @param list
* @throws Exception
*/
@Override
protected void decode(ChannelHandlerContext channelHandlerContext, ByteBuf in, List<Object> list) throws Exception {
// 1.魔数,就相当于一个标识,用来标识这是一个自定义的协议(4个字节的魔数)
int magicNum = in.readInt();
// 2.版本号(1个字节)
byte version = in.readByte();
// 3.序列化算法(先使用JDK作为序列化算法) 使用1个字节来表示序列化算法 jdk 0 json 1
byte serializeType = in.readByte();
// 4.指令类型(1个字节)
byte messageType = in.readByte();
// 5.请求序号(4个字节)
int sequenceId = in.readInt();
// 6.读取无意义的字节
in.readByte();
// 7.获取内容的字节数组
int length = in.readInt();
byte[] bytes = new byte[length];
in.readBytes(bytes, 0, length);
// 8.反序列化
if (serializeType == 0) {
// jdk bytes数据 用流包装了一下
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bytes));
Message message = (Message) ois.readObject();
// 解析出来的消息为
logger.error("{}.{},{},{},{},{}", magicNum, version, serializeType, messageType, sequenceId, length);
logger.error("解析出来的消息为:{}", message);
// 将解析出来的消息放入到list中,交给下一个handler处理 不然下一个handler无法处理
list.add(message);
} else if (serializeType == 1) {
// json
}
}
}
测试程序的编码
/**
* @author 13723
* @version 1.0
* 2024/3/5 22:21
*/
public class EmbeddedChannelTest {
private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());
public static void main(String[] args) {
// 创建一个EmbeddedChannel
EmbeddedChannel channel = new EmbeddedChannel(
new LoggingHandler(),
new MessageCodec());
// 写入一个对象 看看能不能编码
LoginRequestMessage message = new LoginRequestMessage("zhangsan", "123", "张三");
channel.writeOutbound(message);
}
}
通过打印消息信息,我们可以看到我们自定编码器,编码后的数据。
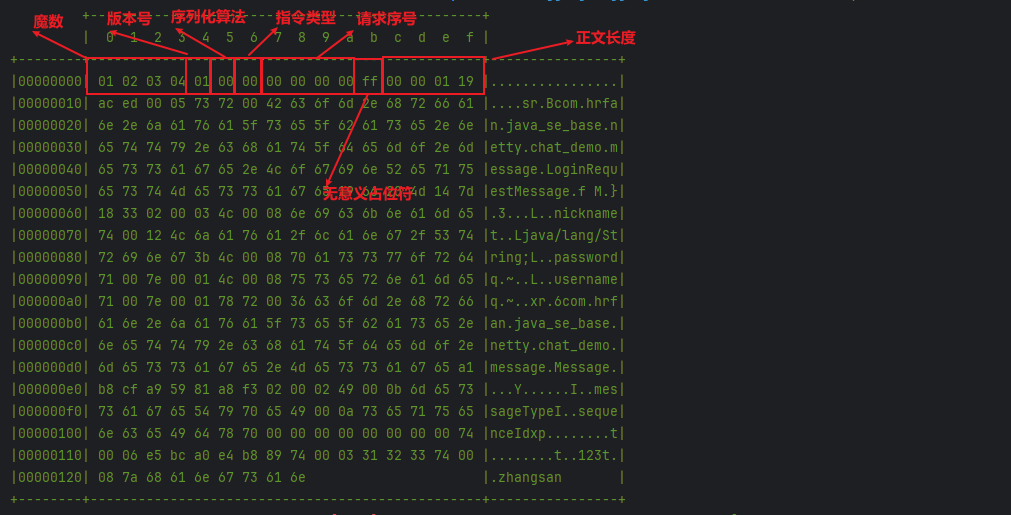
测试程序的解码
public class EmbeddedChannelTest {
private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());
public static void main(String[] args) throws Exception {
// 创建一个EmbeddedChannel
// 为了防止半包 还是需要配 LengthFieldBasedFrameDecoder 否则一旦序列化或者反序列化的字节数组过大,就会出现半包问题
EmbeddedChannel channel = new EmbeddedChannel(
// 参数1:最大长度 参数2:长度域的偏移量 参数3:长度域的长度 参数4:长度域的补偿 参数5:长度域的调整
new LengthFieldBasedFrameDecoder(1024, 12, 4, 0, 0),
new LoggingHandler(),
new MessageCodec());
// 写入一个对象 看看能不能编码
LoginRequestMessage message = new LoginRequestMessage("zhangsan", "123", "张三");
channel.writeOutbound(message);
// 测试解码
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer();
// 此时我们还需要再调用一次encode方法,因为我们在writeOutbound的时候,会调用encode方法
new MessageCodec().encode(null, message, buf);
// 入站
channel.writeInbound(buf);
}
}
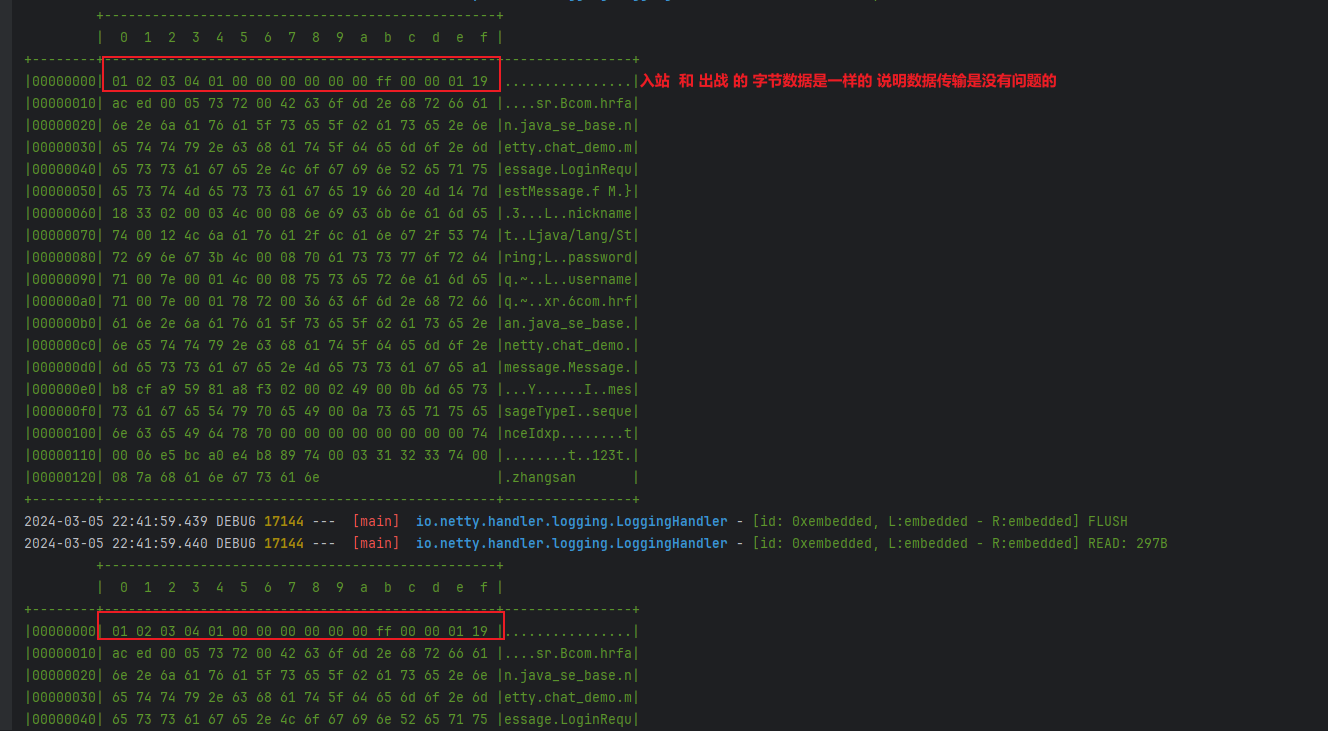

- 通过自定义编码器和解码器,我们可以更灵活地控制消息的格式和传输方式,以满足特定的通信需求。
- 在编码器中,负责将消息对象编码成字节数组,并添加协议标识、版本号、序列化算法类型等头部信息。
- 在解码器中,负责从字节数组中解析出消息对象,并根据协议头部信息进行反序列化。
- 使用消息类的继承和映射关系,可以根据消息类型动态地创建对应的消息对象,从而实现更加灵活的消息处理。
- 通过测试程序验证编码器和解码器的功能,可以保证通信协议的正确性和稳定性。
@Sharable
@Sharable是 Netty 中的一个注解,用于标识一个 ChannelHandler 是否可以被多个 Channel 共享。在 Netty 中,每个 Channel 都有一个对应的 ChannelPipeline,而 ChannelPipeline 中包含了一系列的 ChannelHandler,用于处理进入和离开 Channel 的事件。当一个 ChannelHandler 被标记为
@Sharable时,表示该 Handler 是线程安全的,可以被多个 Channel 共享使用。这意味着同一个实例可以被多个 ChannelPipeline 所共享,从而节省了资源并且减少了对象的创建开销。使用
@Sharable的关键是确保编写的 ChannelHandler 是无状态的或者线程安全的。这意味着它不依赖于 ChannelHandler 实例的状态,而是依赖于传入的事件的内容。以下是
@Sharable注解的一些特点和注意事项:
- 线程安全性: 标记为
@Sharable的 ChannelHandler 应该是线程安全的,因为它可能被多个 Channel 共享并在多个线程上同时调用。- 状态无关性:
@Sharable的 ChannelHandler 应该是状态无关的,即不应该依赖于 ChannelHandler 实例的状态。它应该根据传入的事件内容进行处理。- 共享性: 由于标记为
@Sharable的 ChannelHandler 可以被多个 Channel 共享,因此它们应该是轻量级的,并且不应该包含 Channel 相关的状态或信息。- 生命周期管理: 在使用
@Sharable的 ChannelHandler 时,需要注意其生命周期管理。因为它们可能会被多个 Channel 共享,所以需要确保适当地处理资源的初始化和释放。- 避免副作用:
@Sharable的 ChannelHandler 应该尽量避免副作用,即不要修改外部状态或进行与业务无关的操作。
通过在 MessageCodec 类上添加 @Sharable 注解,确保了该编解码器在多个 EventLoopGroup 中可以被安全地共享使用。
MessageCodec 类:
MessageCodec类继承自MessageToMessageCodec<ByteBuf, Message>,这是 Netty 提供的用于编解码处理的抽象类。- 使用
@Sharable注解标记MessageCodec,表示该编解码器是线程安全的,并且可以在多个 Channel 之间共享使用。 - 在
encode()方法中,将 Java 对象编码为字节数组,并将结果添加到输出列表中。 - 在
decode()方法中,从字节缓冲区中读取数据并进行解码,最后将解码后的消息对象添加到输出列表中。
/**
* 继承ByteToMessageCodec 用来处理编解码
* 1.编码:将Java对象转为字节数组
* 2.解码:将字节数组转为Java对象
* 加上注解 @Sharable 必须和LengthFieldBasedFrameDecoder一起使用,确保接收的数据是完整的,否则会出现半包问题。
* @author 13723
* @version 1.0
* 2024/3/5 21:45
*/
@ChannelHandler.Sharable
public class MessageCodec extends MessageToMessageCodec<ByteBuf,Message> {
private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());
/**
* 编码
* @param channelHandlerContext
* @param message
* @param list
* @throws Exception
*/
@Override
protected void encode(ChannelHandlerContext channelHandlerContext, Message message, List<Object> list) throws Exception {
ByteBuf out = channelHandlerContext.alloc().buffer();
// 拿到ByteBuf 往里面写入数据
// 1.魔数,就相当于一个标识,用来标识这是一个自定义的协议(4个字节的魔数)
out.writeBytes(new byte[]{1, 2, 3, 4});
// 2.版本号(1个字节)
out.writeByte(1);
// 3.序列化算法(先使用JDK作为序列化算法) 使用1个字节来表示序列化算法 jdk 0 json 1
out.writeByte(0);
// 4.指令类型(1个字节)
out.writeByte(message.getMessageType());
// 5.请求序号(4个字节)
out.writeInt(message.getSequenceId());
// 写个无意义的字节,是为了对其,填充字节,填充到8的倍数
out.writeByte(0xff);
// 6.获取内容的字节数组
// 将Java对象转为字节属猪
// 创建一个字节数组输出流
ByteArrayOutputStream bos = new ByteArrayOutputStream();
// 创建一个对象输出流
ObjectOutputStream oos = new ObjectOutputStream(bos);
// 将对象写入字节数组输出流
oos.writeObject(message);
// 获取字节数据
byte[] bytes = bos.toByteArray();
// 7.获取字节长度
out.writeInt(bytes.length);
// 8.写入内容
out.writeBytes(bytes);
list.add(out);
}
/**
* 解码 我们能保证完整的数据包,所以我们不需要考虑半包问题,因为我们能保证上一个处理器是黏包半包处理器
* @param channelHandlerContext
* @param in
* @param list
* @throws Exception
*/
@Override
protected void decode(ChannelHandlerContext channelHandlerContext, ByteBuf in, List<Object> list) throws Exception {
// 1.魔数,就相当于一个标识,用来标识这是一个自定义的协议(4个字节的魔数)
int magicNum = in.readInt();
// 2.版本号(1个字节)
byte version = in.readByte();
// 3.序列化算法(先使用JDK作为序列化算法) 使用1个字节来表示序列化算法 jdk 0 json 1
byte serializeType = in.readByte();
// 4.指令类型(1个字节)
byte messageType = in.readByte();
// 5.请求序号(4个字节)
int sequenceId = in.readInt();
// 6.读取无意义的字节
in.readByte();
// 7.获取内容的字节数组
int length = in.readInt();
byte[] bytes = new byte[length];
in.readBytes(bytes, 0, length);
// 8.反序列化
if (serializeType == 0) {
// jdk bytes数据 用流包装了一下
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bytes));
Message message = (Message) ois.readObject();
// 解析出来的消息为
logger.error("{}.{},{},{},{},{}", magicNum, version, serializeType, messageType, sequenceId, length);
logger.error("解析出来的消息为:{}", message);
// 将解析出来的消息放入到list中,交给下一个handler处理 不然下一个handler无法处理
list.add(message);
} else if (serializeType == 1) {
// json
}
}
}
测试
-
EmbeddedChannelTest类是用于测试自定义编解码器的示例。 -
在
main方法中,创建了一个 Netty 服务器并绑定到本地的 8080 端口。 -
在
ChannelInitializer中,配置了LengthFieldBasedFrameDecoder、LoggingHandler和自定义的MessageCodec。 -
这样配置后,服务器将能够正确地解析传入的消息,并将其交给
MessageCodec处理。 -
如果
MessageCodec类没有使用@Sharable注解标记,并且试图将其添加到多个ChannelPipeline中,就会抛出异常。这是因为 Netty 要求每个ChannelHandler默认情况下是不可共享的,除非显式地使用@Sharable注解进行标记。如果你尝试将一个不带
@Sharable注解的ChannelHandler添加到多个ChannelPipeline中,Netty 将会在运行时抛出ChannelPipelineException异常,提示你不能重复地添加同一个ChannelHandler实例到不同的ChannelPipeline中。 -
如果
MessageCodec类中的encode和decode方法是无状态的,那么它们也是线程安全的,即使MessageCodec没有被标记为@Sharable。无状态意味着
encode和decode方法不依赖于实例的状态,并且对于相同的输入始终产生相同的输出。在这种情况下,即使MessageCodec实例被多个ChannelPipeline共享,也不会引发线程安全问题。因此,如果你的
MessageCodec类中的encode和decode方法是无状态的,它们仍然可以被安全地共享在多个ChannelPipeline中,即使没有使用@Sharable注解。
public class EmbeddedChannelTest {
private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());
public static void main(String[] args) throws Exception {
NioEventLoopGroup boos = new NioEventLoopGroup();
NioEventLoopGroup worker = new NioEventLoopGroup();
LoggingHandler loggingHandler = new LoggingHandler(LogLevel.DEBUG);
// 自定义编解码器 这里是无状态的,因为没有成员变量 所有线程安全
MessageCodec messageCodec = new MessageCodec();
try {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(boos, worker)
.channel(NioServerSocketChannel.class)
.handler(loggingHandler)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel channel) throws Exception {
channel.pipeline().addLast(new LengthFieldBasedFrameDecoder(1024, 12, 4, 0, 0));
channel.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
channel.pipeline().addLast(messageCodec);
}
});
// 测试编解码器
ChannelFuture sync = serverBootstrap.bind(8080).sync();
sync.channel().closeFuture().sync();
}catch (Exception e){
logger.error("serverBootstrap error",e);
e.printStackTrace();
}finally {
boos.shutdownGracefully();
worker.shutdownGracefully();
}
}
}
// 此时再次启动就不会报错了



EmbeddedChannelTest22类是另一个测试示例,使用EmbeddedChannel来测试编解码器的功能。- 在
main方法中,创建了一个EmbeddedChannel,并添加了LengthFieldBasedFrameDecoder、MessageCodec和LoggingHandler。 - 然后,写入一个登录请求消息,并使用
readOutbound()方法读取处理后的消息。
public class EmbeddedChannelTest22 {
private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());
public static void main(String[] args) throws Exception {
// 测试编解码器
EmbeddedChannel channel = new EmbeddedChannel(
new LengthFieldBasedFrameDecoder(1024, 12, 4, 0, 0),
new MessageCodec(),
new LoggingHandler(LogLevel.DEBUG));
// 准备数据
LoginRequestMessage message = new LoginRequestMessage("zhangsan", "123", "张三");
// 写数据
channel.writeOutbound(message);
// 读数据
channel.readOutbound();
}
}

消息也是能够正常读取的















 1152
1152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









