







RedisOperationsSessionRepository,由其负责Session数据到Redis数据库的读写。
接下来简单看一下Redis中的Session数据存储细节。
RedisSession在Redis缓存中的存储细节大致有3种Key(根据版本不同可能不完全一致),分别如下:
spring:session:SESSION_KEY:sessions:0cefe354-3c24-40d8-a859-fe7d9d3c0dba
spring:session:SESSION_KEY:expires:33fdd1b6-b496-4b33-9f7d-df96679d32fe
spring:session:SESSION_KEY:expirations:1581695640000
第一种Key(键)的Value(值)用来存储Session的详细信息,Key的最后部分为Session ID,这是一个UUID。这个Key的Value在Redis中是一个hash类型,内容包括Session的过期时间间隔、最近的访问时间、属性等。Key的过期时间为Session的最大过期时间+5分钟。如果设置的Session过期时间为30分钟,那么这个Key的过期时间为35分钟。第二种Key用来表示Session在Redis中已经过期,这个键-值对不存储任何有用数据,只是为了表示Session过期而设置。
第三种Key存储过去一段时间内过期的Session ID集合。这个Key的最后部分是一个时间戳,代表计时的起始时间。这个Key的Value所使用的Redis数据结构是set,set中的元素是时间戳滚动至下一分钟计算得出的过期Session Key(第二种Key)。
Spring Session的使用和定制
=====================
结合Redis使用Spring Session需要导入以下两个Maven依赖包:
org.springframework.session
spring-session-data-redis
org.springframework.session
spring-session-core
按照Spring Session官方文档的说明,在添加所需的依赖项后,可以通过以下配置启用基于Redis的分布式Session:
@EnableRedisHttpSession
public class Config {
//创建一个连接到默认Redis (localhost:6379)的RedisConnectionFactory
@Bean
public LettuceConnectionFactory connectionFactory() {
return new LettuceConnectionFactory();
}
}
@EnableRedisHttpSession注释创建一个名为
springSessionRepositoryFilter的过滤器,它负责将原始的HttpSession替换为RedisSession。为了使用Redis数据库,这里还创建了一个连接Spring Session到Redis服务器的RedisConnectionFactory实例,该实例连接的默认为Redis,主机和端口分别为localhost和6379。有关Spring Session的具体配置可参阅参考文档,地址为
https://www.springcloud.cc/spring-session.html。
在crazy-springcloud脚手架的共享Session架构中,网关和微服务提供者之间、微服务提供者和微服务提供者之间所传递的不是SessionID而是User ID,所以目标Provider收到请求之后,需要通过User ID找到Session ID,然后找到RedisSession,最后从Session中加载缓存数据。整个流程需要定制3个过滤器,如图6-10所示。
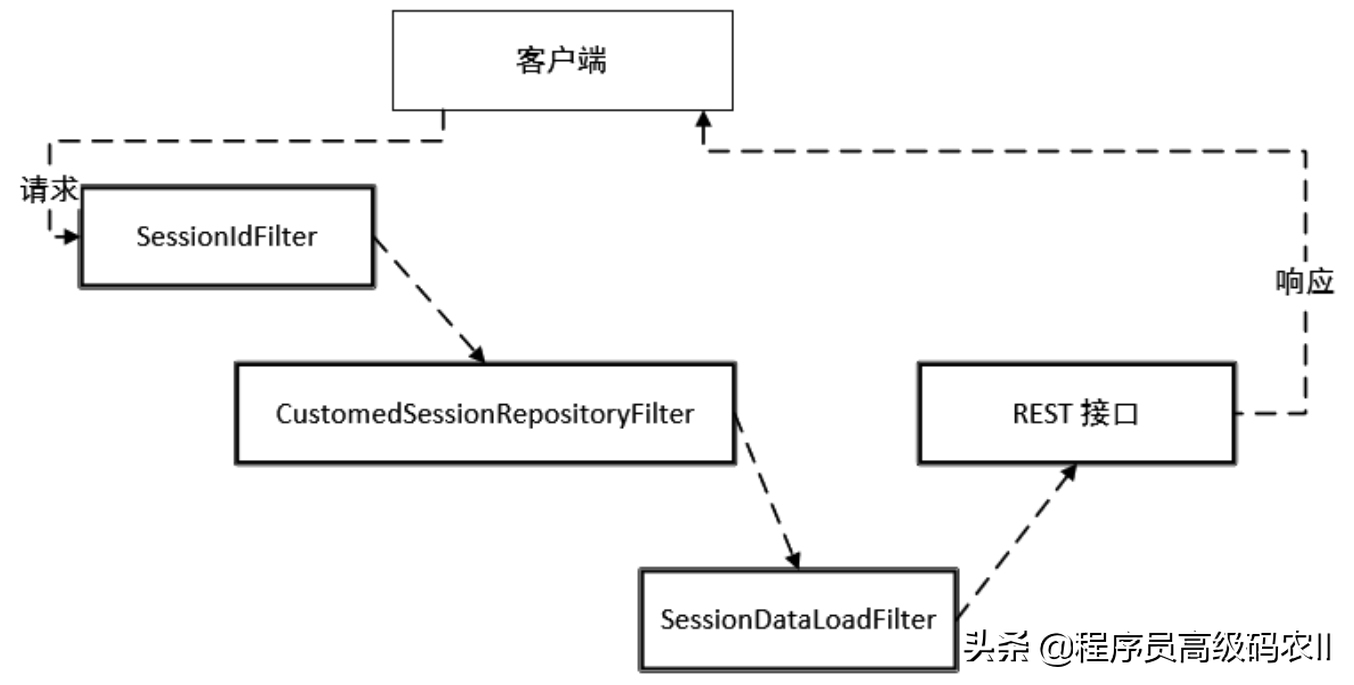
图6-10 crazy-springcloud脚手架共享Session架构中的过滤器
第一个过滤器叫作SessionIdFilter,其作用是根据请求头中的用户身份标识User ID定位到分布式会话的Session ID。
第二个过滤器叫作
CustomedSessionRepositoryFilter,这个类的源码来自Spring Session,其主要的逻辑是将request(请求)和response(响应)进行包装,将HttpSession替换成RedisSession。
第三个过滤器叫作SessionDataLoadFilter,其判断RedisSession中的用户数据是否存在,如果是首次创建的Session,就从数据库中将常用的用户数据加载到Session,以便控制层的业务逻辑代码能够被高速访问。
在crazy-springcloud脚手架中,按照高度复用的原则,所有和会话有关的代码都封装在base-session基础模块中。如果某个Provider模块需要用到分布式Session,只需要在Maven中引入base-session模块依赖即可。
通过用户身份标识查找Session ID
====================
通过用户身份标识(User ID)查找Session ID的工作是由SessionIdFilter过滤器完成的。在前面介绍的UAA提供者服务(crazymakeruaa)中,用户的User ID和Session ID之间的绑定关系位于缓存Redis中。
base-session借鉴了同样的思路。当带着User ID的请求进来时,SessionIdFilter会根据User ID去Redis查找绑定的Session ID。如果查找成功,那么过滤器的任务完成;如果查找不成功,后面的两个过滤器就会创建新的RedisSession,并将在Redis中缓存User ID和Session ID之间的绑定关系。
SessionIdFilter的代码如下:
package com.crazymaker.springcloud.base.filter;
//省略import
@Slf4j
public class SessionIdFilter extends OncePerRequestFilter
{
public SessionIdFilter(RedisRepository redisRepository,
RedisOperationsSessionRepository sessionRepository)
{
this.redisRepository = redisRepository;
this.sessionRepository = sessionRepository;
}
/**
*RedisSession DAO
*/
private RedisOperationsSessionRepository sessionRepository;
/**
*Redis DAO
*/
RedisRepository redisRepository;
/**
*返回true代表不执行过滤器,false代表执行
*/
@Override
protected boolean shouldNotFilter(HttpServletRequest request)
{
String userIdentifier = request.getHeader(SessionConstants.USER_IDENTIFIER);
if (StringUtils.isNotEmpty(userIdentifier))
{
return false;
}
return true;
}
/**
*将session userIdentifier(用户id)转成session id
*@param request请求
*@param response响应
*@param chain过滤器链
*/
@Override protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response, FilterChain chain) throws IOException, ServletException
{
/**
*从请求头中获取session userIdentifier(用户id)
*/
String userIdentifier = request.getHeader(SessionConstants.USER_IDENTIFIER);
SessionHolder.setUserIdentifer(userIdentifier);
/**
*在Redis中,根据用户id获取缓存的session id
*/
String sid = redisRepository.getSessionId(userIdentifier);
if (StringUtils.isNotEmpty(sid))
{
/**
*判断分布式Session是否存在
*/
Session session = sessionRepository.findById(sid);
if (null != session)
{
//保存session id线程局部变量,供后面的过滤器使用
SessionHolder.setSid(sid);
}
}
chain.doFilter(request, response);
}
}
SessionIdFilter过滤器中含有两个DAO层的成员:一个RedisRepository类型的DAO成员,负责根据User ID去Redis查找绑定的Session ID;另一个DAO成员的类型为Spring Session专用的
RedisOperationsSessionRepository,负责根据Session ID去查找RedisSession实例,用于验证Session是否真正存在。
查找或创建分布式Session
===============
SessionIdFilter过滤处理完成后,请求将进入下一个过滤器
CustomedSessionRepositoryFilter。这个类的源码来自Spring Session,其主要的逻辑是将request(请求)和response(响应)进行包装,并将原始请求的HttpSession替换成RedisSession。定制之后的过滤器稍微做了一点过滤条件的修改:如果请求头中携带了用户身份标识,就开启分布式Session,否则不会进入分布式Session的处理流程。
CustomedSessionRepositoryFilter的部分代码如下:
package com.crazymaker.springcloud.base.filter;
//省略import
public class CustomedSessionRepositoryFilter extends OncePerRequestFilter
{
//执行过滤
@Override
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException
{
…
//包装上一个过滤器的HttpServletRequest请求至SessionRepositoryRequest
Wrapper
SessionRepositoryRequestWrapper wrappedRequest =
new SessionRepositoryRequestWrapper(request, response, this.
servletContext);
//包装上一个过滤器的HttpServletResponse响应至SessionRepository
ResponseWrapper
SessionRepositoryResponseWrapper wrappedResponse =
new SessionRepositoryResponseWrapper(wrappedRequest, response);
try
{
filterChain.doFilter(wrappedRequest, wrappedResponse);
} finally
{
//会话持久化到数据库
wrappedRequest.commitSession();
}
}
/**
*返回true代表不执行过滤器,false代表执行
*/
@Override
protected boolean shouldNotFilter(HttpServletRequest request)
{
//如果请求中携带了用户身份标识
if (null == SessionHolder.getUserIdentifer())
{
return true;
}
return false;
}
…
}
SessionRepositoryFilter首先会根据一个sessionIds清单进行Session查找,查找失败才创建新的RedisSession。它会调用CustomedSessionIdResolver实例的resolveSessionIds方法获取sessionIds清单。
作为Session ID的解析器,CustomedSessionIdResolver的部分代码如下:
package com.crazymaker.springcloud.base.core;
…
@Data
public class CustomedSessionIdResolver implements HttpSessionIdResolver
{
…
/**
*解析session id,用于在Redis中进行Session查找
*@param request请求
*@return session id列表
*/
@Override
public List resolveSessionIds(HttpServletRequest request)
{
//获取第一个过滤器保存的session id
String sid = SessionHolder.getSid();
return (sid != null) ? Collections.singletonList(sid) : Collections.emptyList();
}
…
}
CustomedSessionRepositoryFilter会对sessionIds清单进行判断,然后根据结果进行分布式Session的查找或创建:
(1)如果清单中的某个Session ID对应的Session存在于Redis,过滤器就会将分布式RedisSession查找出来作为当前Session。
(2)如果清单为空,或者所有Session ID对应的RedisSession都不在于Redis,过滤器就会创建一个新的RedisSession。
加载高速访问数据到分布式Session
===================
CustomedSessionRepositoryFilter处理完成后,请求将进入下一个过滤器SessionDataLoadFilter。这个类的主要逻辑是加载需要高速访问的数据到分布式Session,具体如下:
(1)获取前面的SessionIdFilter过滤器加载的Session ID,用于判断Session ID是否变化。如果变化就表明旧的Session不存在或者旧的Session ID已经过期,需要更新Session ID,并且在Redis中进行缓存。
(2)获取前面的
CustomedSessionRepositoryFilter创建的Session,如果是新创建的Session,就加载必要的需要高速访问的数据,以提高后续操作的性能。
需要高速访问的数据比较常见的有用户的基础信息、角色、权限等,还有一些基础的业务信息。
CustomedSessionRepositoryFilter的部分代码如下:
package com.crazymaker.springcloud.base.filter;
…
@Slf4j
public class SessionDataLoadFilter extends OncePerRequestFilter
{
UserLoadService userLoadService;
RedisRepository redisRepository;
public SessionDataLoadFilter(UserLoadService userLoadService, RedisRepository redisRepository)
{
this.userLoadService = userLoadService;
this.redisRepository = redisRepository;
}
…
@Override
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain)
throws ServletException, IOException
{
//获取前面的SessionIdFilter过滤器加载的session id
String sid = SessionHolder.getSid();
//获取前面的CustomedSessionRepositoryFilter创建的session,加载必要的数据到session
HttpSession session = request.getSession();
/**
*之前的session不存在
*/
if (StringUtils.isEmpty(sid) || !sid.equals(request.getSession()
.getId()))
{
//取得当前的session id
sid = session.getId();
//user id和session id作为键-值保存到redis
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

总结
一般像这样的大企业都有好几轮面试,所以自己一定要花点时间去收集整理一下公司的背景,公司的企业文化,俗话说「知己知彼百战不殆」,不要盲目的去面试,还有很多人关心怎么去跟HR谈薪资。
这边给大家一个建议,如果你的理想薪资是30K,你完全可以跟HR谈33~35K,而不是一下子就把自己的底牌暴露了出来,不过肯定不能说的这么直接,比如原来你的公司是25K,你可以跟HR讲原来的薪资是多少,你们这边能给到我的是多少?你说我这边希望可以有一个20%涨薪。
最后再说几句关于招聘平台的,总之,简历投递给公司之前,请确认下这家公司到底咋样,先去百度了解下,别被坑了,每个平台都有一些居心不良的广告党等着你上钩,千万别上当!!!
Java架构学习资料,学习技术内容包含有:Spring,Dubbo,MyBatis, RPC, 源码分析,高并发、高性能、分布式,性能优化,微服务 高级架构开发等等。
还有Java核心知识点+全套架构师学习资料和视频+一线大厂面试宝典+面试简历模板可以领取+阿里美团网易腾讯小米爱奇艺快手哔哩哔哩面试题+Spring源码合集+Java架构实战电子书。

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
「知己知彼百战不殆」,不要盲目的去面试,还有很多人关心怎么去跟HR谈薪资。
这边给大家一个建议,如果你的理想薪资是30K,你完全可以跟HR谈33~35K,而不是一下子就把自己的底牌暴露了出来,不过肯定不能说的这么直接,比如原来你的公司是25K,你可以跟HR讲原来的薪资是多少,你们这边能给到我的是多少?你说我这边希望可以有一个20%涨薪。
最后再说几句关于招聘平台的,总之,简历投递给公司之前,请确认下这家公司到底咋样,先去百度了解下,别被坑了,每个平台都有一些居心不良的广告党等着你上钩,千万别上当!!!
Java架构学习资料,学习技术内容包含有:Spring,Dubbo,MyBatis, RPC, 源码分析,高并发、高性能、分布式,性能优化,微服务 高级架构开发等等。
还有Java核心知识点+全套架构师学习资料和视频+一线大厂面试宝典+面试简历模板可以领取+阿里美团网易腾讯小米爱奇艺快手哔哩哔哩面试题+Spring源码合集+Java架构实战电子书。
[外链图片转存中…(img-Iz0yqm4E-1713683299134)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 9679
9679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









