







线性模型使用范围
相比于非线性模型,线性模型更适用于:
1. 小数据集
2. 低信噪比
3. 稀疏数据
1. 线性回归模型
约定数据集
X=(X1,X2,...,Xp)
有p个特征,
Xj∈RN
共N个样本。
给X增加一列1,
X=(1,X1,X2,...,Xp)
,
β=(β0,β1,...,βp)T
,上式可写成矩阵形式:
这里的
f(X)
为真实模型,
β
为真实模型参数,相对应的有估计模型和估计参数, 估计模型的结果为估计的响应变量y
在统计学习里,我们一般认为真实的,即观测到的响应变量为估计与误差的叠加
这里
ε=(ε0,ε1,...,εN)T
, 是每个样本预测值和真实值的误差组成的向量,假设它服从高斯分布
那么y也服从高斯分布
根据X的不同来源,线性模型的表达能力可以得到极大的扩展:
- 定量输入
- 定量输入的变换,如log, 平方根,平方
- 基展开,如 X2=X21,X3=X31
- 哑变量,类别变量做独热编码变成的由0,1组成的稀疏矩阵
- 交互项,如 X3=X1X2
2. 最小二乘法
2.1 求解方法与理解
为了求得真实模型,我们希望y和
y^=Xβ^
的误差尽量小,因此需要求得使残差平方和
RSS(β)=(y−Xβ)T(y−Xβ)
最小的模型参数
β
,这是无约束二次优化问题,直接求导即可
当X列满秩时,若以y为未知数,方程组Xy=0中y只有0解,而这里y≠0,因此Xy≠0,所以
yT(XTX)y=(Xy)T(Xy)>0
,即
XTX
正定,非奇异,则
其实,要使所求解为极小值点也必须满足
因此X列满秩是必须满足的条件。下面只讨论X列满秩的情况。
那么
可见,
y^
是X列向量的线性组合,
y^∈span<X0,X1,...,Xp>
,所以
真实的
y=f(X)+ε
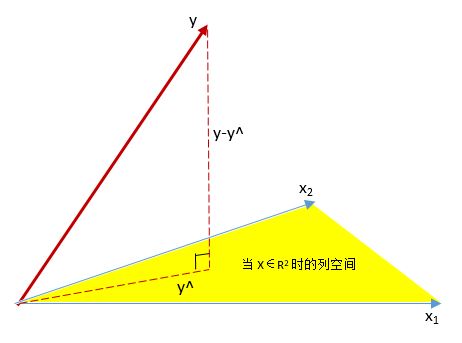
, 由于误差的存在,y不在X的列空间里边。所以,对于最小二乘法来说,最小化残差平方和
min||y−y^||2
即找到一个
y^
使得
y−y^
正交于X的列空间。此时,
||y−y^||
取得最小值,放张图感受一下。
根据维数公式,有
所以,
dim(y−y^)=dim(y)−dim(y^)=N−(p+1)
(求这个是为了后面求卡方分布的自由度)
那么,什么是回归?就是求y在X列空间的投影,所以我们说
y^
是y在X上的回归。而最小二乘法所做的就是找到这种正交映射。令
H=X(XTX)−1XT
H就是这个投影矩阵。
2.2 β^ 的期望与方差
我们估计的
β^
与真实的
β
差别有多大呢?
可见,用最小二乘法所估计出来的模型参数是无偏估计。
其中
另外,如果我们能估计出
σ
,那么也就能估计出
Var(β^)
, 也就能求出
β^
的置信区间了。
我们知道,误差服从高斯分布
残差平方和服从自由度为N-p-1的卡方分布(一个高斯分布的平方自然是 χ2 分布了),所以有
则
可证明,上面的
σ^
是
σ
的无偏估计。因此
2.3 β^j 的假设检验
2.3.1 单个 β^j 的假设检验
由
β^=(XTX)−1XTy
,以及y服从高斯分布可知,
β^
也服从高斯分布
写成分量形式,对于 j=1,2,…,N,
其中, vjj 为 (XTX)−1 的第j个对角元, vjjσ^2 是 βj^ 的方差,其标准差应为 vjj−−−√σ^ 。不过,我们不知道是否有 vjj>0
设
u∈Rp+1
列向量,构造
w=(XTX)−1u
,也是p+1维列向量,自然有
u=XTXw
,因此
显然,只有当u=0时,才有w=0,进而才恒有
uT(XTX)−1u=0
, 因此
(XTX)−1
正定,故
vjj>0
,此时我们可以写出参数
β^j
的z分数了。
在原假设
β^j=0
下,z服从自由度为N-p-1的t分布(一个高斯分布除以一个
χ2
分布的平方根,自然是t分布了),绝对值大的z分数,其对应的p值(可以查t分布表)也就越小,越可以拒绝原假设,即
β^j>0
,相应的特征
Xj
应该被保留。
当N足够大时,t分布近似于高斯分布,t分布的尾分数与高斯分布的尾分数几乎相等,因此也可认为z服从高斯分布。这是一般的假设检验过程,这里不详述了。
2.3.2 多个 β^j 的假设检验
F统计量可检验一组系数是否可置0,
其中 RSS1 是用较大模型(参数多)算出来的残差平方和, p1 是该模型的参数数量(特征维数), RSS0 是较小模型的残差平方和, p0 是该模型的参数数量(特征维数)。在高斯假设下,设较小模型更正确为零假设下,F统计量服从 Fp1−p0,N−p1−1 分布,可查表得到相应p值以判断是否拒绝原假设,即较小模型是否更好。
2.4 β^j 的置信区间
上面提到参数
β^j
的z分数
z服从自由度为N-p-1的t分布,那么z的
1−α
置信区间为
因此真实模型参数
βj
的
1−α
置信区间为
其中
z1−α2
可通过查表得到。比如我想要个95%置信区间
若样本较多,N很大,可查标准正太分布表有
所以
βj
的95%置信区间为
总结自The Elements of Statistical Learning
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









