






为什么要有线索二叉树呢:
对于一个有n个结点的二叉链表,一共有2n个指针域,而n个结点的二叉树一共有n-1条分支线数,也就是说存在n+1个空指针域,这些空间要是不储存任何东西就很浪费了。
线索二叉树的思路:
我们在对二叉树进行遍历后,我们便会知道在该遍历方法下任意一个结点的前驱和后继是哪一个结点,而在二叉链表中我们每次知道想要知道莫个结点的前驱或者后继都需要遍历一次,这就导致效率很低,所以我们可以在遍历一次该二叉树后就记住每个结点的前驱和后继,我们可以考虑利用那些空地址来储存莫种遍历次序下结点的前驱和后继的地址,这个过程我们称为线索化。
1.线索二叉树储存结点结构
枚举类型重命名
typedef enum { Link, Thread } PointerTag;//线索二叉树储存结点结构
typedef struct BiThrNode
{
//数据域
ElemType data;
//左,右子树指针
BiThrNode* lchild, * rchild;
//左右线索标志
PointerTag LTag, RTag;
}BiThrNode,*BiThrTree;由于我们要判断在左右指针中指向的到底是该结点的左右孩子还是前驱和后继,所以我们需要在结点中在加入两个线索标志来进行判断(加入线索标志虽然会导致一部分的内存浪费,但是由于只是一个枚举类型,占用的空间很小)
2.构造二叉树(利用前序遍历)
//构造二叉树(利用前序遍历)
//输入#就表明是空结点
void CreateBiTheTree(BiThrTree& T)
{
ElemType ch;
cin >> ch;
//是空结点,不创建相应的结点
if (ch == '#')
{
//我们遍历到的指针T所指向的位置不需要创建结点,所以是个空指针
T = NULL;
}
else
{
T = new(BiThrNode);
if (!T)
exit(0);
//创建结点后,初始化结点中的信息
T->data = ch;
//左右线索标志一开始都假设为Link,在对二叉树线索化的函数中才赋确切的值
T->LTag = Link;
T->RTag = Link;
//递归左子树
CreateBiTheTree(T->lchild);
//递归右子树
CreateBiTheTree(T->rchild);
}
}
此时只是创建一个普通的二叉树,我们还不知道前驱和后继之间的关系,所以左右标志都暂定为Link表示左右指针指向的是左右孩子。我们要在创建好一个普通的二叉树后再进行线索化。
3.中序遍历线索化二叉树
//全局变量,始终指向刚刚遍历过的结点
BiThrTree pre;
//中序遍历线索化二叉树
void InThreading(BiThrTree& T)
{
//判断树是否为空
if (T)
{
//用p来遍历树
BiThrTree p=T;
//递归左子树
InThreading(p->lchild);
//对结点进行处理
//我们只用考虑左右孩子不存在的情况,因为存在的情况在构造二叉树时已经完成了
if (!p->lchild)
{
//改变线索标志表示左指针指向的是前驱
p->LTag = Thread;
//指向当前结点的前驱pre,pre目前还未初始化,要在后面的函数才具体实现
p->lchild = pre;
}
//判断刚刚遍历过的结点pre是否有右孩子,之所以不判断p而是pre
//是因为我们在遍历的过程中只知晓当前结点T以及前驱结点pre的情况
if (!pre->rchild)
{
pre->RTag = Thread;
pre->rchild = p;
}
//更新pre指向的结点,让pre始终指向刚刚遍历过的结点
pre = p;
//递归右子树
InThreading(p->rchild);
}
}线索化二叉树主要体现在对结点的处理上,我们在遍历二叉树时只能知道当前结点和上一个结点,所以只能线索化当前结点的前驱和上一个结点的后继,我们定义了一个全局变量pre始终指向刚刚遍历过的结点,实际上在当前函数pre是无意义的因为它还未进行初始化,而我们将它设为全局变量也是为了在下一个函数初始化它。
4.创建线索二叉树,Thrt指向头结点,初始化pre
//创建线索二叉树,Thrt指向头结点,初始化pre
void InOrderThreading(BiThrTree& Thrt, BiThrTree& T)
{
Thrt = new(BiThrNode);
//头结点的左右指针要指向的结点已经是确定的了
//头结点的左指针要指向根结点,根结点作为头结点的左孩子
Thrt->LTag = Link;
Thrt->RTag = Thread;
//Thrt的右指针指向最后一个遍历到的结点,此时还不知道
Thrt->rchild = Thrt;//右指针回指
//判断二叉树T是否存在
if (!T)
{
//二叉树T若是不存在,头结点Thrt只能指向自身
Thrt->lchild = Thrt;//左指针回指
}
else
{
Thrt->lchild = T;
//初始化pre
pre = Thrt;
//中序遍历线索二叉树
InThreading(T);
//经过上面的感受1线索二叉树后,最后一个结点的右指针仍然是空的,可以让其指向头结点,形成一个循环结构
pre->RTag = Thread;
pre->rchild = Thrt;
//头结点的右指针也是空的,可让其指向最后一个结点,形成循环结构
Thrt->rchild = pre;
}
}在该函数中我们主要实现下图这样的结构:
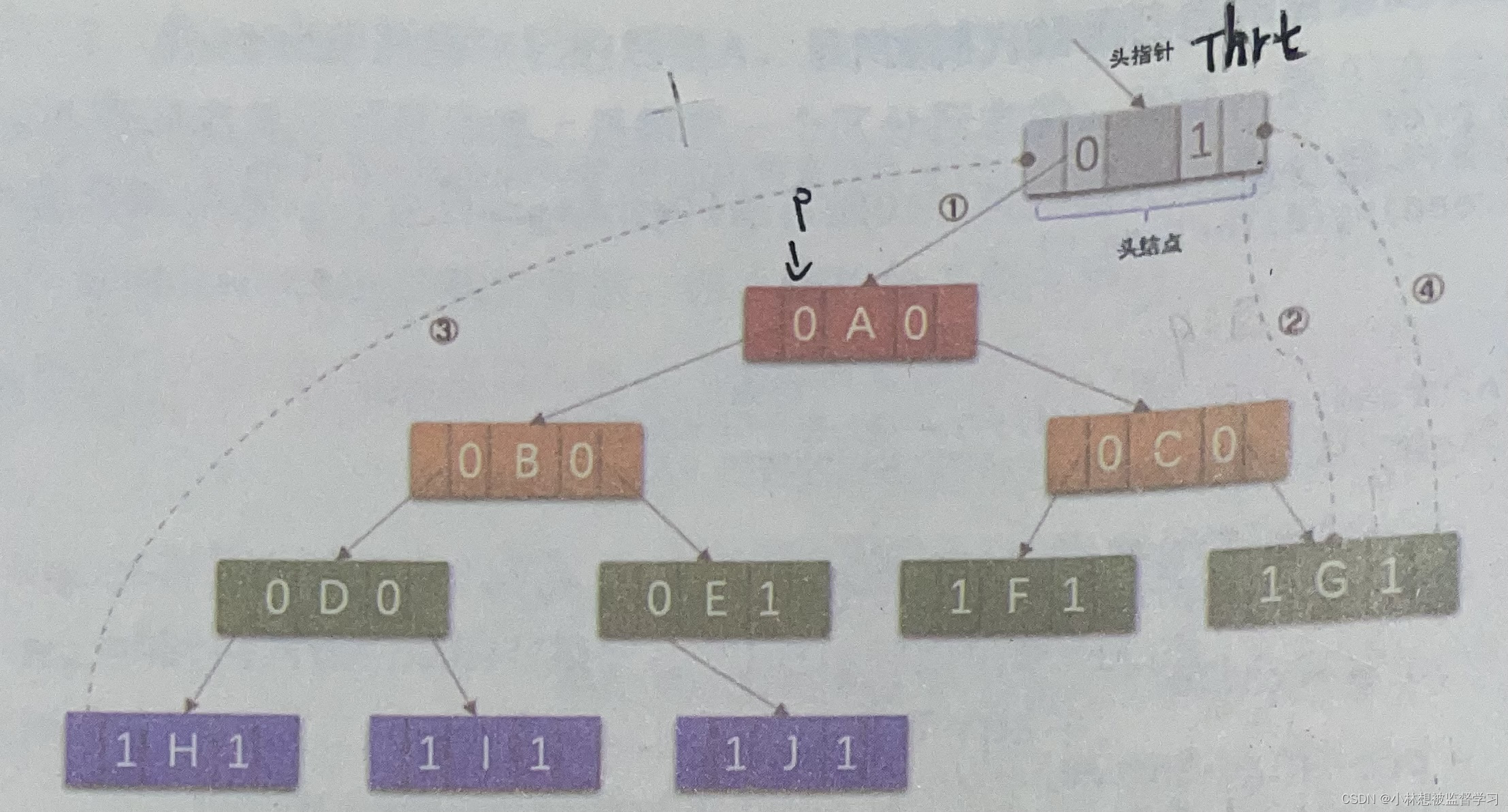
所以我们要创建一个头结点,并让头结点通过1,2,3,4的分支线连入二叉树,并初始化pre指向头结点,这样线索化的遍历从根结点A开始就能让pre始终指向之前遍历过的结点
5.中序遍历线索二叉树(非递归算法)
//中序遍历线索二叉树(非递归算法)
void InOrderTraverse_Thr(BiThrTree& Thrt)
{
BiThrTree p = Thrt->lchild;
//遍历树到最后一个结点为止
//当p=Thrt时说明树已经遍历完了
while (p != Thrt)
{
//遍历到中序遍历的第一个结点
while (p->lchild && p->LTag == Link)
{
p = p->lchild;
}
cout << p->data << " ";
//当前结点有后继结点的情况
while (p->RTag == Thread && p->rchild != Thrt)
{
p = p->rchild;
cout << p->data << " ";
}
//当前结点有右子树的情况
p = p->rchild;
}
}我们既然已经线索化了二叉树就不需要像之前一样需要递归来对二叉树进行遍历了,通过后继指针便可以很好的通过迭代遍历完二叉树。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











