









跳跃表
-
skipList 调表的原理以及golang实现
-
调表skiplist 是一个特殊的链表,相比一般的链表有更高的查找效率,跳跃表的查找,插入,删除的时间复杂度O(logN)
-
Redis中的有序集合zset,LevelDB,HBase 中Memtables使用调表这种数据结构
-
跳表本质上是一个链表, 它其实是由有序链表发展而来。
-
跳表在链表之上做了一些优化,跳表在有序链表之上加入了若干层用于索引的有序链表。
-
索引链表的结点来源于基础链表,不过只有部分结点会加入索引链表中,并且越高层的链表结点数越少。
-
跳表查询从顶层链表开始查询,然后逐级展开,直到底层链表。这种查询方式与树结构非常类似,使得跳表的查询效率相近树结构。
-
另外跳表使用概率均衡技术而不是使用强制性均衡,因此对于插入和删除结点比传统上的平衡树算法更为简洁高效。因此跳表适合增删操作比较频繁,并且对查询性能要求比较高的场景。

-
有序链表是一个线性结构,不能使用二分法查找数据(因为二分查找需要用到中间位置的节点,而链表不能随机访问),在有序链表中找数据,需要从头开始逐个进行比较,直到找到包含数据的那个节点。

- 为基础链表建立一层索引表,索引表只有基础链表结点的1/2。添加了索引表之后的数据结构如上图所示。索引表相当于基础链表的目录,查询时首先从索引表开始查找,当遇到比待查数据大的结点时,再从基础链表中查找。
-
-
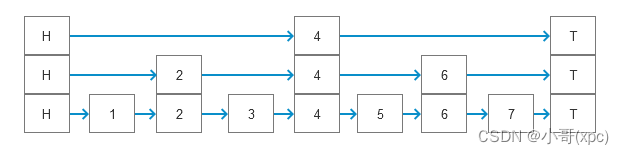
我们还为基础链表添加第二层索引表,第二层索引表结点的数量是第一层索引表的1/2,添加了第二层索引表之后的数据结构如上图所示,第二层索引表的结点的数量只有基础链表的1/4左右,查找时首先从第二层索引表开始查找,当遇到比待查数据大的结点时,再从第一层索引表开始查找,然后再从基础链表中查找数据。这种逐层展开的方式与树结构的查询非常类似,因此跳表的查询性能与树结构接近,时间的复杂度为O(logN)。
-
一个平衡的二叉树,在增加/删除结点后会造成二叉树结构的不平衡,降低二叉树的查询性能。跳表也会面临同样的问题,造成跳表查询性能的降低。跳表采用了一种概率均衡技术来创建上层链表, 保证各层链表之间的比例关系。在为跳表增加一个结点时,会调用一个概率函数来计算一个结点的层次(level),例如若level=3,则结点除了出现在基础链表外,还会出现在第一层索引以及第二层索引链表中。结点层次的计算逻辑如下
-
每个节点肯定都在基础链表中;如果一个节点存在于第i层链表,那么它有第(i+1)层链表的概率为p;节点最大的层数不允许超过一个最大值
-
跳表每一个节点的层数是随机的,且新插入一个节点不会影响其它节点的层数。因此插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整,这就降低了插入操作的复杂度。实际上这是跳表的一个很重要的特性,这让跳表在增删操作的性能上明显优于平衡树的方案
-
跳跃表查询,查找某个元素时,先从顶层链表查询,逐个查找节点,当遇到比带查询大的节点时,跳到下一层链表中继续向前查询,当遍历到第一层时,下一个节点就是目标节点
-
package main import ( "fmt" "math/rand" "sync" ) /** 链表节点 */ type SkipNode struct { key int64 // 表示一个节点,用于查询 value interface{} //可以表示任意类型的数据 next []*SkipNode //各层的后向节点指针数组,数组的长度为层高,level } /** 跳跃表 */ type SkipList struct { SkipNode //跳表的header mutex sync.RWMutex //锁 update []*SkipNode //查询过程中的链式变量 maxL int //最大层数,32 skip int //层之间的比例,skip=4,1/4节点出现再上层 level int //跳表当前层数 length int32 //调表的节点数 } /** 初始化跳跃表 */ func NewSkipList() *SkipList { l := &SkipList{} l.maxL = 32 l.skip = 4 l.SkipNode.next = make([]*SkipNode, l.maxL) l.update = make([]*SkipNode, l.maxL) return l } /** 节点查找 */ func (l *SkipList) Get(key int64) interface{} { l.mutex.Lock() defer l.mutex.Unlock() var prev = &l.SkipNode var next *SkipNode //1.从底层链表开始查询 for i := l.level - 1; i >= 0; i-- { next = prev.next[i] for next != nil && next.key < key { prev = next next = prev.next[i] } } if next != nil && next.key == key { return next.value } else { return nil } } /** 1. 查找待插入的位置,需要获取每层的前驱节点 2.构造新节点,通过概率函数计算节点的层数level 3.讲新节点插入到第0层到第level-1层的链表中 */ func (l *SkipList) Set(key int64, val interface{}) { l.mutex.Lock() defer l.mutex.Unlock() var prev = &l.SkipNode var next *SkipNode for i := l.level - 1; i >= 0; i-- { next = prev.next[i] for next != nil && next.key < key { prev = next next = prev.next[i] } l.update[i] = prev } //如果key已经存在 if next != nil && next.key == key { next.value = val return } //随机生成新结点的层数 level := l.randomLevel() if level > l.level { level = l.level + 1 l.level = level l.update[l.level-1] = &l.SkipNode } //申请新的结点 node := &SkipNode{} node.key = key node.value = val node.next = make([]*SkipNode, level) //调整next指向 for i := 0; i < level; i++ { node.next[i] = l.update[i].next[i] l.update[i].next[i] = node } l.length++ } func (l *SkipList) Remove(key int64) interface{} { l.mutex.Lock() defer l.mutex.Unlock() //获取每层的前驱节点=>list.update var prev = &l.SkipNode var next *SkipNode for i := l.level - 1; i >= 0; i-- { next = prev.next[i] for next != nil && next.key < key { prev = next next = prev.next[i] } l.update[i] = prev } //结点不存在 node := next if next == nil || next.key != key { return nil } //调整next指向 for i, v := range node.next { if l.update[i].next[i] == node { l.update[i].next[i] = v if l.SkipNode.next[i] == nil { l.level -= 1 } } l.update[i] = nil } l.length-- return node.value } func (l *SkipList) randomLevel() int { i := 1 for ; i < l.maxL; i++ { if rand.Int()%l.skip != 0 { break } } return i } func main() { l := NewSkipList() l.Set(1, 10) l.Set(2, 20) l.Set(3, 30) l.Set(4, 40) l.Set(5, 50) l.Set(6, 60) fmt.Println(l.Get(4)) fmt.Println(l.Remove(5)) /** 40 50 */ }
















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











