







从另一个角度对主键进行分类:
1、 自然主键,该列与其他列没有依赖关系;
2、 业务主键,该列数据与其他列数据之间有着依赖的关系;
第三种约束:默认约束 defaut
此种约束也是用来限制列数据内容的;
作用是:当向表中添加记录时,如果该列中设置了默认值,没有显式提供插入数据,则以默认值自动填充;如果显式提供了数据,则以提供的数据填充。
好处在于省略了相同而重复的内容值。
作一个建筑工人表,包括自然主键,姓名,性别,年龄等信息
create table worker(wid int identity(1000,1) primary key,
wname nvarchar(10)not null,
wsex nchar(1)default'男',--默认值为'男'
wtime datetime default getdate(),--动态的默认值
)
插入数据:
insert into worker(wname) values('张三')
insert into worker(wname,wsex) values('李四','女')
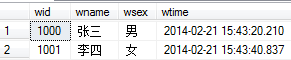
默认约束是所有约束中,功能最差的一个,因为只有在没有显式提供数据时,这个约束也有作用,一旦显式提供了列值,则此约束没有任何作用。
在特定情况下,如果和其他约束联合起来,会起到一个特别的作用。
和唯一性标识类型作主键,和默认结束结合。
重新设计users表:
create table users
(
userid uniqueidentifier primary key default newid(),
--将主键约束和默认约束结合起来使用
username nvarchar(20) not null,
password varchar(20) not null,
)
向表中添加记录:
insert into users(username,password) values('admin','admin')
insert into users(username,password) values('member','member')

向表中的wsex列追加默认约束,默认值为’男’:
alter table worker add
--constraint df_worker_wsex 可以省略
default '男'
for wsex
go
第四类约束:唯一性约束,unique
此类约束也是用来表中的某列,它和默认约束一样,都可以修饰多列,即默认约束、唯一性在一个表中可以有多个,而主键约束只有一个;
与主键的区别在于它支持null值,根据唯一性的特点,只能有一个。
此类是单表约束中,操作最简单的一个。
使用场合:如果表中的非主键列中,需要限制列数据为不能重复,则将唯一性约束设置到该列上。如用户表中的用户名这一列。
重新设计用户表users:
create table users(
uid uniqueidentifier primary key default newid(),
uname nvarchar(20)not null unique,
upasswd nvarchar(20)not null,
)
向表中添加记录:
insert into users(uname,upasswd) values('没核儿','passwd123没核儿')

如果继续添加记录:
insert into users(uname,upasswd) values('没核儿','123')

向表中追加唯一性约束:
alter table users
add
unique(username)
go
表的拷贝:
数据库内部拷贝
跨数据库拷贝
数据库中表的拷贝使用into子句,表拷贝语法:
select*into worker_copy from workerselect*from worker_copy
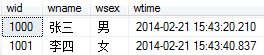
execute sp_help worker
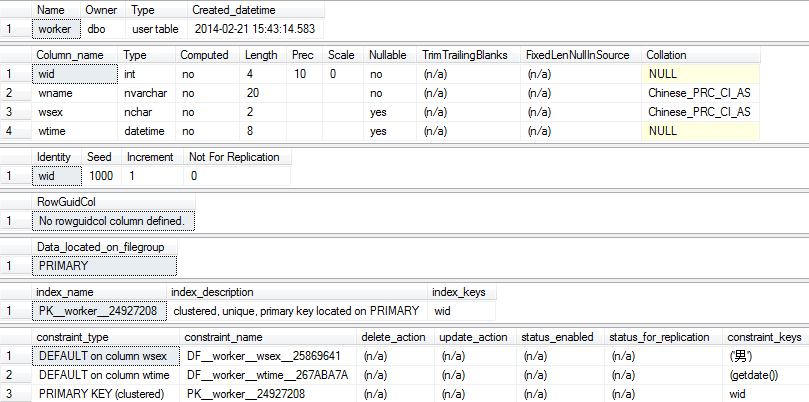
execute sp_help worker_copy
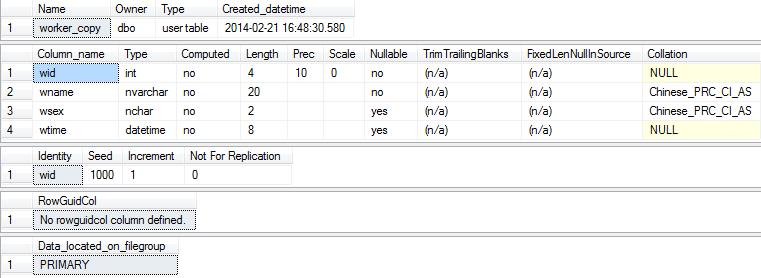
表拷贝的优点在于不需要创建目录表的结构(部分)就将源表的结构及行记录信息复制过来。
表拷贝的缺点在于除了自增属性以外,其他所有的约束都会丢失。
如果要将新表成为一张安全的表格,则需要在新表中追加所需要的约束
简单的查询:
查询表的前面n条记录:
select top 4 *from sysobjects
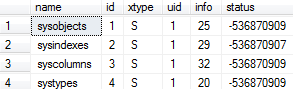
查询表前4行记录中的部分列:
select top 4 name,id,xtype,uid from sysobjects
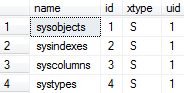
查询表中从前面数n%的行记录:
select top 4 percent name,id,xtype,uid from sysobjects
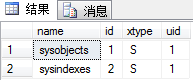
条件查询:使用where子句
在查询测试时,因为用户数据库中的数据量比较少,所以我们引入一些外部数据。
附加数据库和分离数据库功能。
以上两个功能都是通过系统存储过程来完成的。
从外部介质上拷贝来的数据库文件,是不能直接在当前服务器使用的,即不是可用数据库,最多只能说是“备用”。
--附加pubs数据库
use master
go
execute sp_attach_db @dbname='pubs',
@filename1='C:\Microsoft SQL Server\MSSQL.1\MSSQL\Data\pubs.mdf',
@filename2='C:\Microsoft SQL Server\MSSQL.1\MSSQL\Data\pubs_log.ldf'
go
分离数据库,此功能与删除数据库功能不同。当数据库被分离之后,它不会被删除,只是不能被当前服务器调用了;一旦需要,附加即可。
使用master数据库中的系统存储过程sp_detach_db
use master
go
--将northwind数据库从当前服务器中分离,由可用变为不可用
execute sp_detach_db 'northwind','true'
go
将示例数据库pubs中的表jobs和authors拷贝到mydb中。
use mydbselect*into jobs from pubs.dbo.jobs
拷贝来的表中,只有自增属性保留下来,所有约束都丢失了。
use mydb
select *into authors from pubs..authors --若数据库的模式(目录)为dbo时,中间的dbo可省略
select*from authors

查找authors表中,属于KS州的作者信息:
select*from authors where state='ks'

作者中属于mi,in或tn州的作者信息:
select*from authors where state='mi'or state='in'or state='tn'

查找Authors表中将姓和名合并起来及其他部分列,取前5行。
select top 5 au_id,au_fname+' '+au_lname as 'au_name',phone,address from authors
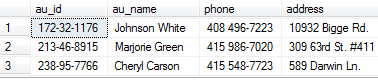
查找作者表中姓的首字母为s的作者:
select *from authors where--left(au_lname,1)='s' 其中一种方法
substring(au_lname,1,1)='s'
go

查找作者表中姓的第三个字符为e,并且名的长度大于10的作者:
select *from authors where substring(au_lname,3,1)='e' and len(au_fname)>10
















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









