







前言:这是在慕课网上学习剑指Java面试-Offer直通车时所做的笔记,主要供本人复习之用.主要介绍的是数据库索引的一些基础知识,主要以mysql为例进行了说明.
参考:https://www.cnblogs.com/zjfjava/p/6922494.html
目录
第一章 索引的意义
我们查询数据的方式有全表扫描,我们将整张表的数据全部或者分批次加载进内存当中,存储的最小单位是块或者页,它们由多行数据组成,数据库将这些块加载进来逐个块去轮询,大量数据下这种方式是比较慢的.
在字典中,我们将关键信息组织起来,比如偏旁部首,查询的时候依据这些信息的指引就能找到我们想要的页,很快就能定位到我们要找的字了.
我们要避免全表扫描情况发生,可以仿照上面的字典查询引入一种查询机制,于是我们的数据库引入了一种索引机制,我们将能把记录限定在一定查找范围内的字段作为索引,通过索引进行数据的查找,我们的主键便是很好的切入点,唯一键,普通键也可以作为索引.
第二章 索引的数据结构
有了关键字还是不行,我们要将关键字按照一定的结构组织起来才能更高效查找.
注意:索引的存储块与数据库的最小存储单位块或者页并非一一对应,为了看着方便,我们这里对应起来了
2.1 二叉查找树
生成索引,建立二叉查找树进行二分查找.

二叉查找树的性质:
对于某个节点来说,左子树的任意节点的值均小于此节点,右子树的任意节点的值均大于此节点.
平衡二叉树:任意一个节点的左右子树高度差不超过一.
一个平衡二叉树经过删除与插入容易退化成线性的二叉树,我们可以用树的翻转来解决退化成的线性的问题,但是影响程序运行速度的主要是io,如果我们把这些索引块都放在磁盘中,拿左图中的二叉查找树来讲,去找6,会发生三次io分别将5,7,6加入进内存中,即检索深度每增加一机会增加一次io,而我们的数据很多,树的深度就会很深,io的次数也会很多,这样数据一多,就会比全表扫描都慢,所以为了降低io的次数我们要将树的高度变得矮一些,即每个节点能存储的数据多一些.

2.2 B-Tree树
生成索引,建立BTree结构进行查找.
如果每个节点最多有m个孩子,那么这样的树就是m阶b树,下图就是一个三阶b树的样子,现实中每个索引的孩子数上限是远大于3的.每个块中主要包括关键字和指向孩子的指针,最多能有几个孩子取决于存储快的容量与数据库的相关配置,通常情况是m是很大的
当B-Tree进行子节点的增删时,b树通过上移下移分裂来保持特征,,所以不会变成线性的情况.

B-Tree定义:


拿一开始的示例图举个例子.
关键字就是上图中的8,12,即关键字是从小到大排的.
p[1]指向关键字小于k[1]的子树,即p1指向的3,5都小于8.p[M]指向关键字大于k[M-1],即13,15大于12,其它P[i]指向关键字属于(K[i-1],K[i])的子树,即中间的指针指向的节点的值,在两个关键字之间,即9,10,在8,12之间.这也表明了关键字最多m-1个的原因,因为最多m个子节点.
当我们查找10时,发现小于17,查p1节点,大于8小于12,查p2节点,找到10.
2.3 B+-Tree树
题目中的-是杠的意思.
生成索引,建立B+Tree结构进行查找(mysql索引生成的主要方式).
B+-Tree的定义与B树基本相同,除了:

第二条表示,第三条表示所有的搜索都将在叶子节点终结.第四条方便我们进行统计.
实例:
关键字5的指针指向的子节点的关键字在5,20之间.

结论:
B+-Tree更适合用来存储索引.
其磁盘读写代价更低,其非叶子节点不存在指向关键数据的指针,即不存放数据,只存放索引信息,因此其内部节点相对于B-Tree更小,如果把所有内部节点的同一关键字存储在盘块中,这个盘块所能容纳的关键字也越多,一次性读入内存中的需要查找的关键字也就越多,相对来说io读写次数也就降低了.
B+-Tree的查找效率更加稳定.
B+-Tree更有利于对数据库的扫描.B-Tree没有解决扫描数据库效率底下的问题,而B+-Tree只需要遍历叶子节点就能完成对全部数据库的扫描,所以对于数据库中频繁使用的范围查询,我们只需顺着指针去找就行了.
2.4 建立Hash结构进行查找
生成索引,建立Hash结构进行查找.
有的数据库也支持hash索引,即将关键字进行hash,比如对SandraDee进行哈希,映射到152号,然后将152号对应的entry全部加载到内存中,因为entry是个链表,我们跟再一个个查找,最终找到SandraDee.


还有一种hash索引是BitMap索引,感兴趣可以自己再去网上查一下(mysql不支持).
第三章 密集索引和稀疏索引的区别
3.1 一般数据库的情况
定义:

密集索引保存的不仅仅是键值(索引值),还保存了位于同一行记录里的其它信息,由于密集索引决定了表的物理排列顺序,一个表只能有一个物理排列顺序,所以一个表只能创建一个密集索引.
稀疏索引的叶子节点仅保留了键位信息以及该行数据的地址,有的稀疏索引是仅保存了键位信息与其主键,定位到叶子节点后依然需要通过地址或者主键信息进一步定位到数据.
示例图:

3.2 mysql数据库的情况
MyISAM的所有主键,唯一键,普通索引都是稀疏索引.
InnoDB必须有且只有一个密集索引.具体密集索引的生成规则如下.

注意非主键索引也就是稀疏索引的叶子节点并不存储行数据的物理地址,而是存储的是该行的主键值,所以非主键索引包含了两次查找,先索引自身,再查找主键.
示例:
InnoDB将主键存储到一个B+-Tree中,行数据存储到叶子节点上,InnoDB的主键索引和对应的数据是保存在一个文件当中的,所以检索的时候在加载叶子节点的主键进入内存的同时,也加载了对应的数据.
若对稀疏索引进行条件筛选需要两个步骤,首先在稀疏索引的B+-Tree中检索该键,然后定位到主键信息,获取到主键信息后,再使用主键从主键索引中查找.

创建表的时候经常有primary key,unique key ,foreign key, index等
primary key 有两个作用,一是约束作用(constraint),用来规范一个存储主键和唯一性,但同时也在此key上建立了一个主键索引;
unique key 也有两个作用,一是约束作用(constraint),规范数据的唯一性,但同时也在这个key上建立了一个唯一索引;
foreign key 也有两个作用,一是约束作用(constraint),规范数据的引用完整性,但同时也在这个key上建立了一个index;
key与index就一个作用,定义一个索引.
第四章 调优慢sql
4.1 大概思路

4.2 开启慢sql记录
打开慢sql的配置:
show variables like '%quer%';查看慢sql查询语句的数量
show status like '%slow_queries%';开启慢日志记录
set global slow_query_log =on;将慢查询时间设置为1s,重新连接.
注:在这里设置如果我们重启了mysql服务,配置又将还原,我们要去my.ini中去配置才不会还原.
set global long_query_time =1;最后的配置:

4.3 实例
我向数据库中插入了200W条数据
select count(id) from person结果: 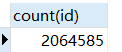
执行查询 :
select * from person order by age打开慢查询记录,可以看到用了9.6s.
# Time: 190328 18:53:49
# User@Host: root[root] @ localhost [127.0.0.1]
# Query_time: 9.597941 Lock_time: 0.000000 Rows_sent: 2064585 Rows_examined: 4129170
SET timestamp=1553770429;
select * from person order by age;4.3.1 explain介绍
Explain关键字段:
type:是mysql找到数据行的方式,性能排列如下:
index与all表名本次查询走的是全表扫描,当我们看到语句是慢查询语句且类型是index与all的时候就要考虑优化了.

extra:有很多,这里我们举两个可能需要优化的extra

key表明使用的是哪个键的索引.
继续分析实例:
用explain对查询语句进行分析
explain select * from person order by age分析结果如下图,key为空,表明没有用索引进行分析.

我们给age加上索引.
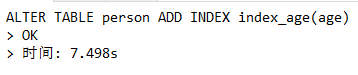
ALTER TABLE person ADD INDEX index_age(age);加入成功.
再次进行相同的查询
select * from person force index(index_age) order by age打开慢记录查询只用了6.6S,快了3S,提升了近百分之30的效率.
# Time: 190328 19:22:35
# User@Host: root[root] @ localhost [127.0.0.1]
# Query_time: 6.654758 Lock_time: 0.000000 Rows_sent: 2064585 Rows_examined: 2064585
SET timestamp=1553772155;
select * from person force index(index_age) order by age;继续分析查询语句,可以看到使用索引值index_age
explain select * from person force index(index_age) order by age
第五章 联合索引的最左匹配的原则的成因
假设我们有两列a,b,我们对a,b设置一个联合索引,顺序是a,b,我们在where中调用where a=.. and b= ..时就会走a,b的联合索引.如果我们调用where a=...也会调用这个索引,但是如果我们调用where b=...的时候没有a的时候就不会走这个索引了.
实际例子:
建立title和area的索引

两个一起查,在possible_keys中走的是联合索引.

![]()
删掉area,发现不走联合索引了,取而代之走了全表扫描.


那么具体原则是什么呢?,乱序就是可以换位置,只要换位置后满足最左匹配原则那么都可以用索引查找.

原因:创建复合索引的规则是首先对复合索引最左边的第一个数据进行排序,在第一个索引的基础上再对第二个索引进行排序,类似于order by字段1,order by字段2,第一个字段是绝对有序的,第二个字段就是无序的了,所以我们如果直接使用第二个条件判断,我们是用不到索引的(B+-Tree是根据索引字段值的大小进行构建的,乱序的话大于小于的查找没有意义),所以我们要强调最左匹配.
下图的B+-Tree是按照col3进行排序的.可以看到人名是有序的,col2的数字在同一个人名下是有序的,换一个就无序了.

第六章 索引是建立的越多越好吗?
















 201
201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









