







算法的基本知识
算法就是计算或者解决问题的步骤
第一章 数据结构
数据存储于内存时,决定了数据顺序和位置关系的便是“数据结构”
链表 (循环链表, 双向链表)
链表是数据结构之一,其中的数据呈线性排列。在链表中,数据的添加和删除都较为方便,就是访问比较耗费时间

双向链表存在两个缺点:
一是指针数的增加会导致存储空间需求增加;
二是添加和删除数据时需要改变更多指针的指向;
数组
数组也是数据呈线性排列的一种数据结构
在数组中,访问数据十分简单,而添加和删除数据比较耗工夫
数据按顺序存储在内存的连续空间内
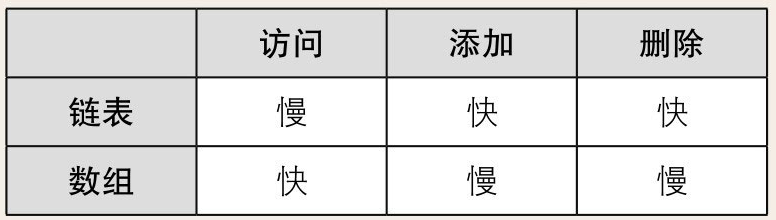
栈 (先进后出)
栈也是一种数据呈线性排列的数据结构
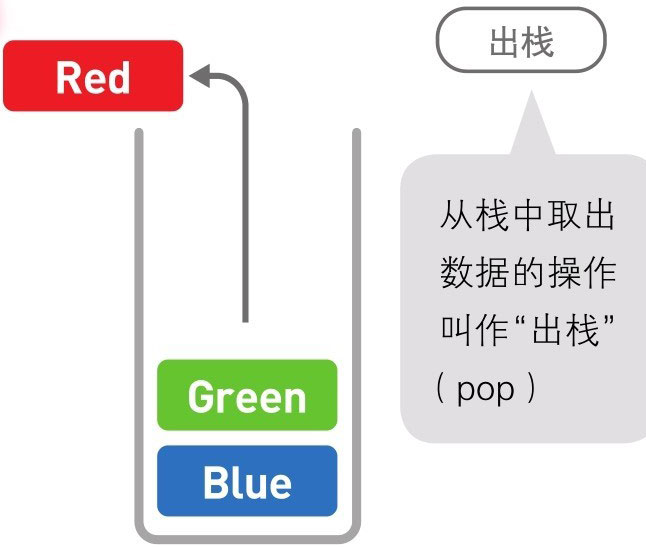
队列 (先进先出)
队列中的数据也呈线性排列
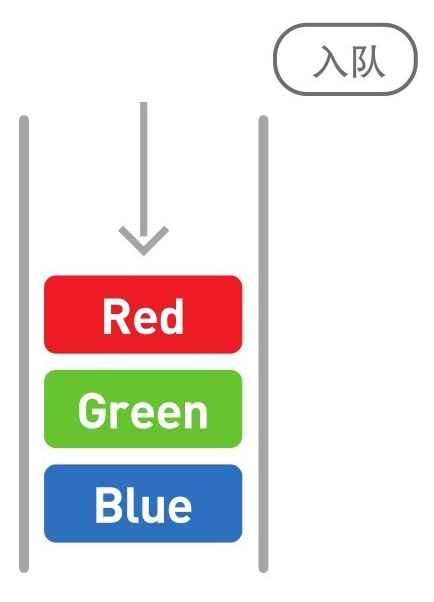
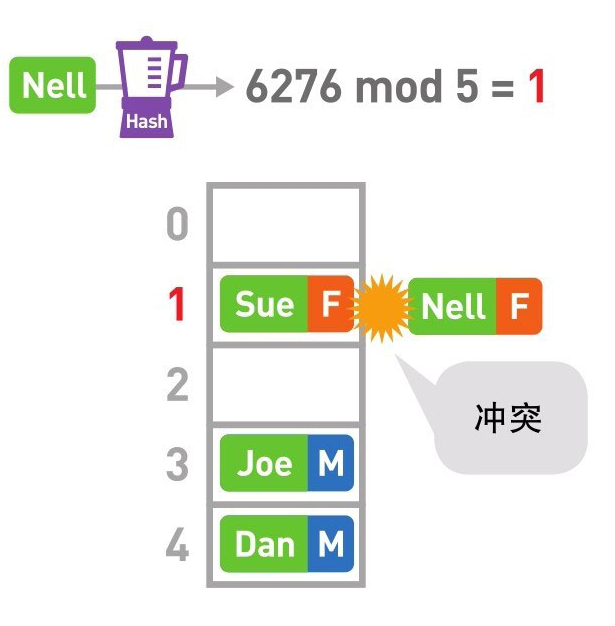
哈希表
哈希表存储的是由键(key)和值(value)组成的数据
哈希值除以数组的长度5,求得其余数。这样的求余运算叫作“mod运算”。此处mod运算的结果为3
冲突时, 使用链表在已有数据的后面继续存储新的数据
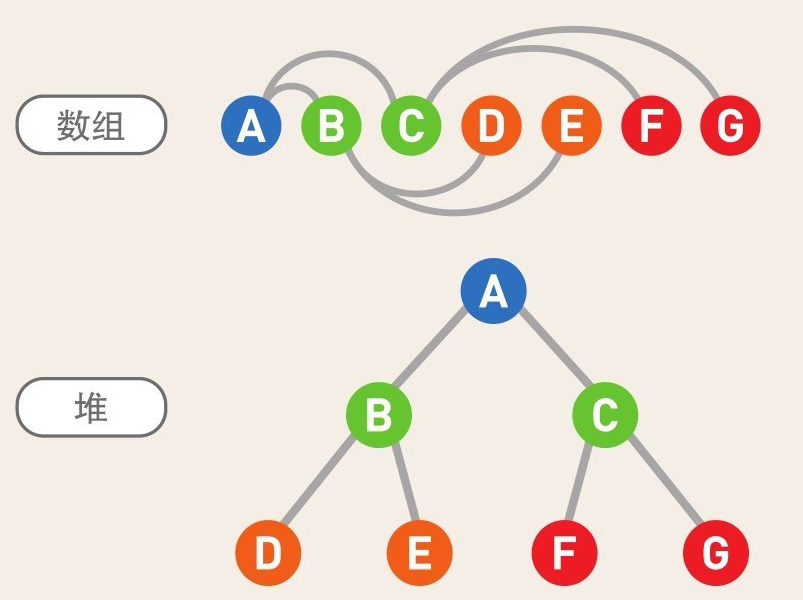
堆
堆是一种图的树形结构
在堆中存储数据时必须遵守这样一条规则:子结点必定大于父结点。
堆中最顶端的数据始终最小,所以无论数据量有多少,取出最小值的时间复杂度都为O(1)
取出/添加 数据需要的运行时间和树的高度成正比 O(logn)
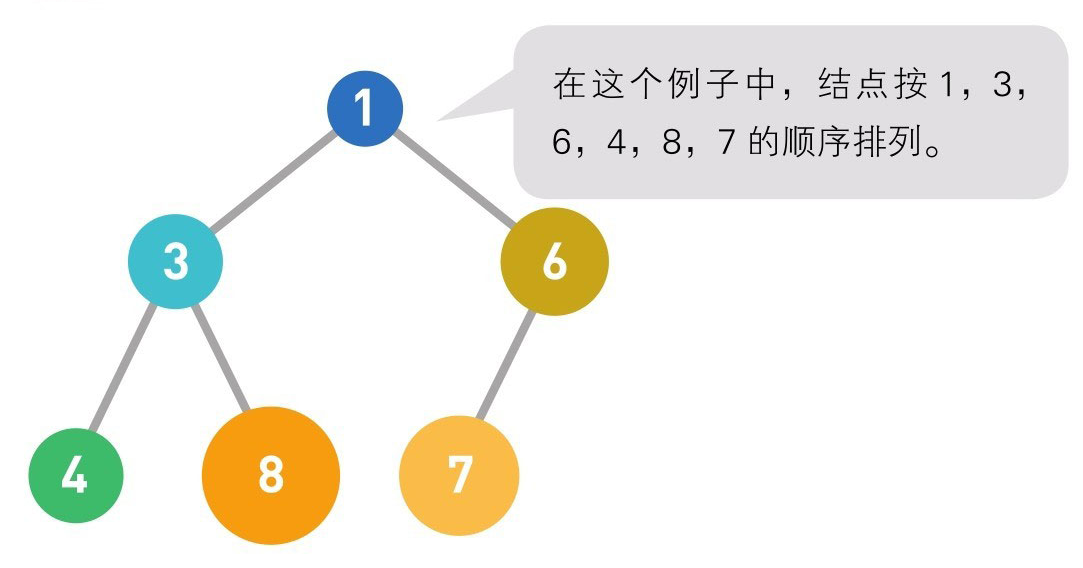
二叉查找数
二叉查找树(又叫作二叉搜索树或二叉排序树)是一种数据结构,采用了图的树形结构
参考博文: 二叉树及堆;二叉搜索树-CSDN博客
第二章 排序
什么是排序
排序就是将输入的数字按照从小到大的顺序进行排列
冒泡排序
从序列右边开始比较相邻两个数字的大小,再根据结果交换两个数字的位置”这一操作的算法。在这个过程中,数字会像泡泡一样,慢慢从右往左“浮”到序列的顶端,所以这个算法才被称为“冒泡排序”
选择排序
选择排序就是重复“从待排序的数据中寻找最小值,将其与序列最左边的数字进行交换”这一操作的算法。在序列中寻找最小值时使用的是线性查找。
插入排序
插入排序是一种从序列左端开始依次对数据进行"交换"排序的算法。在排序过程中,左侧的数据陆续归位,而右侧留下的就是还未被排序的数据。插入排序的思路就是从右侧的未排序区域内取出一个数据,然后将它插入到已排序区域内合适的位置上。
堆排序
堆排序的特点是利用了数据结构中的堆
相当于将堆嵌入到包含了序列的数组中,然后在数组中通过交换数据来进行排序
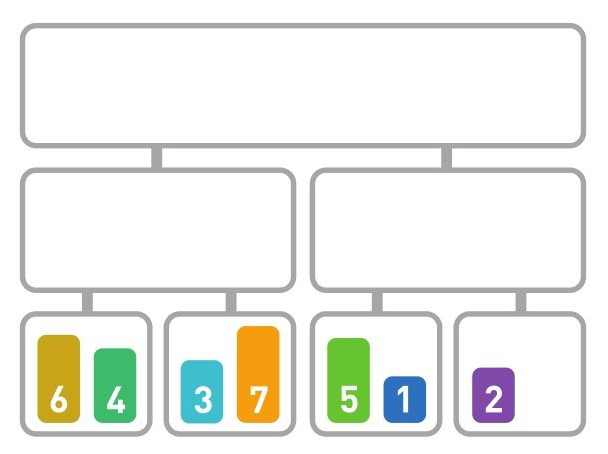
归并排序
归并排序算法会把序列分成长度相同的两个子序列,当无法继续往下分时(也就是每个子序列中只有一个数据时),就对子序列进行归并(结合)。
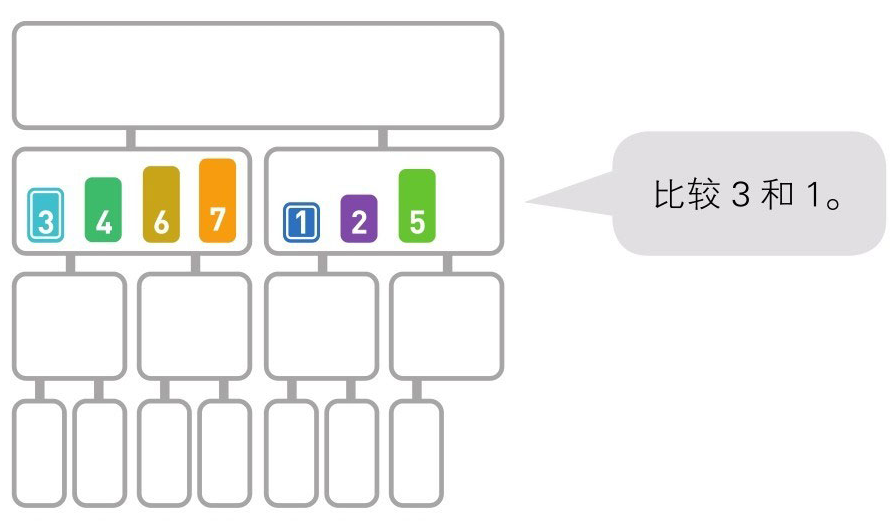
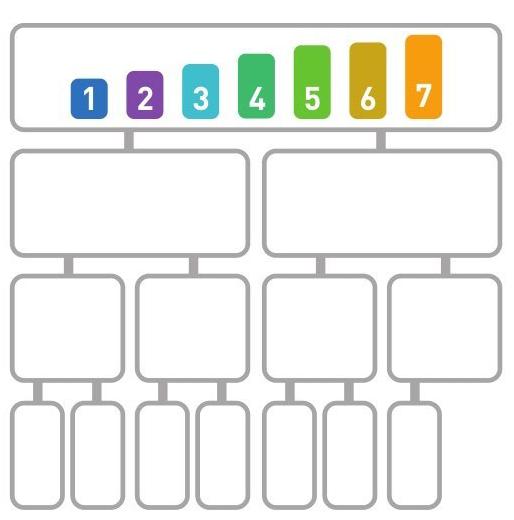
快速排序
快速排序算法首先会在序列中随机选择一个基准值(pivot),然后将除了基准值以外的数分为“比基准值小的数”和“比基准值大的数”这两个类别,再将其排列成以下形式。

快速排序是一种“分治法”。它将原本的问题分成两个子问题(比基准值小的数和比基准值大的数),然后再分别解决这两个问题
第三章 数组的查找
线性查找
线性查找是一种在数组中查找数据的算法, 按顺序依次不断的查询
二分查找
二分查找通过比较数组中间的数据与目标数据的大小,可以得知目标数据是在数组的左边还是右边
二分查找利用已排好序的数组,每一次查找都可以将查找范围减半。查找范围内只剩一个数据时查找结束。
第四章 图的搜索
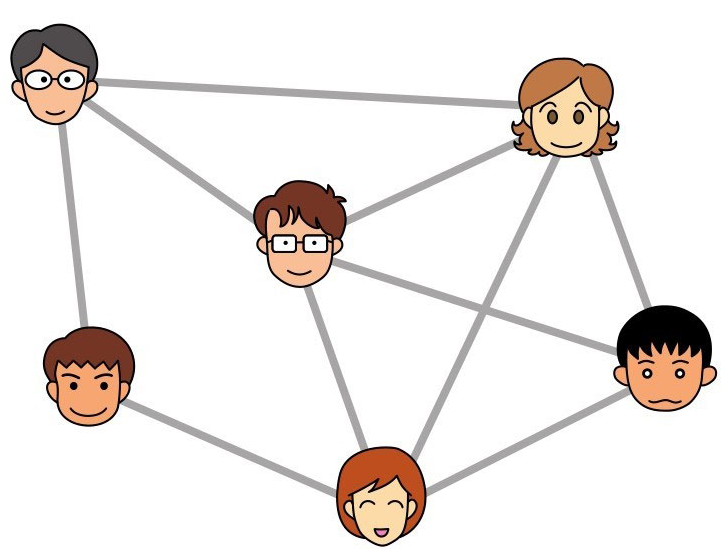
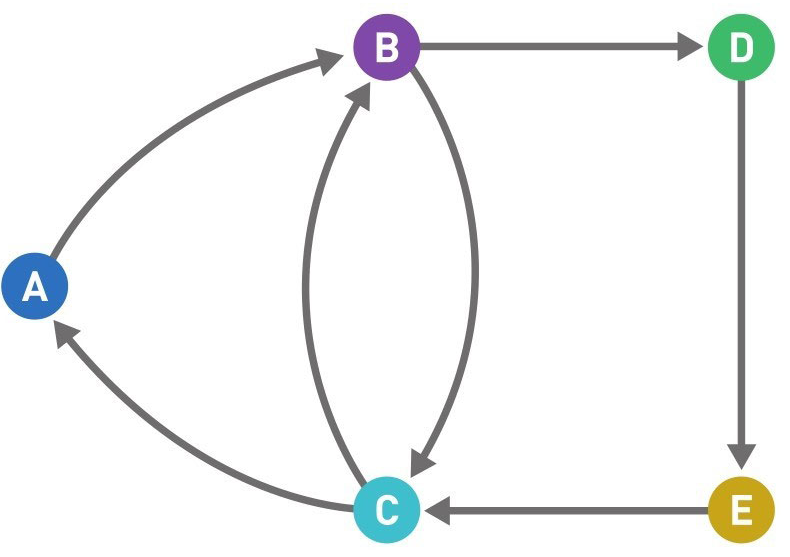
什么是图
圆圈叫作“顶点”(也叫“结点”),连接顶点的线叫作“边”, 由顶点和连接每对顶点的边所构成的图形就是图
图可以表现社会中的各种关系,使用起来非常方便
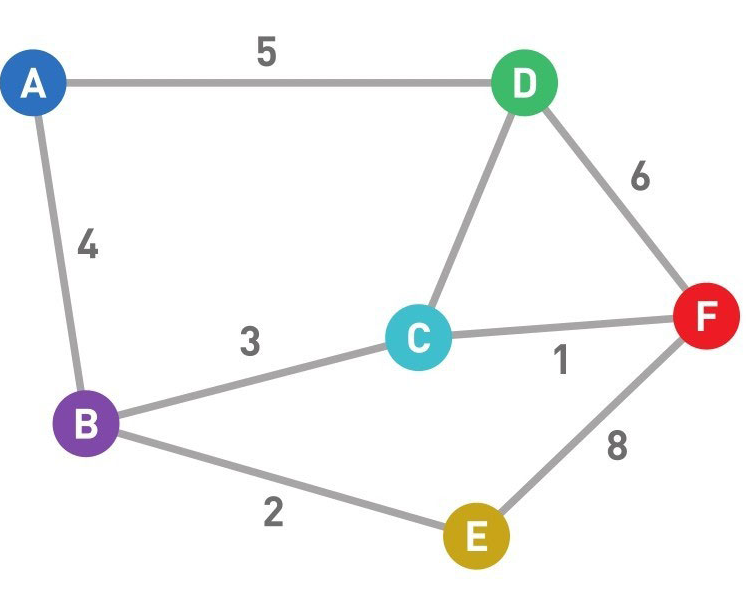
加权图
值叫作边的“权重”或者“权”,加了权的图被称为“加权图” , 没有权的边只能表示两个顶点的连接状态,而有权的边就可以表示顶点之间的“连接程度”, 根据图的内容不同,“程度”表示的意思也不同, 有可能是 次数, 有可能是 时间, 也有可能是 长短
有向图
当我们想在路线图中表示该路线只能单向行驶时,就可以给边加上箭头,而这样的图就叫作“有向图”
图能给我们带来哪些便利
寻找计算机网络中通信时间最短的路径,寻找路线图中耗时最短的路径,寻找路线图中最省乘车费的路径等
广度优先搜索
广度优先搜索是一种对图进行搜索的算法
深度优先搜索
深度优先搜索会沿着一条路径不断往下搜索直到不能再继续为止,然后再折返,开始搜索下一条候补路径。
贝尔曼-福特算法
贝尔曼-福特(Bellman-Ford)算法是一种在图中求解最短路径问题的算法。
狄克斯特拉算法
也是求解最短路径问题的算法
A-Star算法
A*(A-Star)算法也是一种在图中求解最短路径问题的算法,由狄克斯特拉算法发展而来
第五章 安全算法
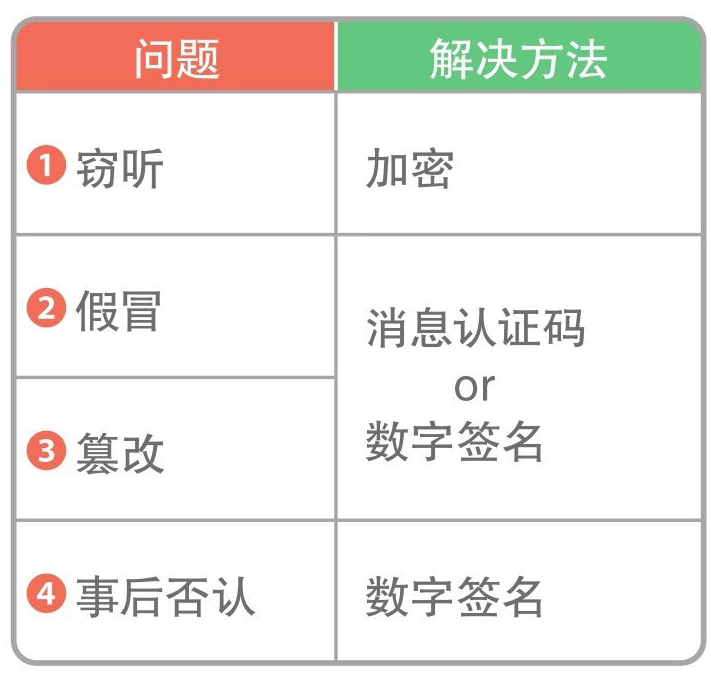
传输数据时的四个主要问题
第六章 聚类
第七章 其他算法
欧几里得算法
欧几里得算法(又称辗转相除法)用于计算两个数的最大公约数,被称为世界上最古老的算法
汉诺塔
汉诺塔是一种移动圆盘的游戏,同时也是一个简单易懂的递归算法应用示例。















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









