







python实现爬虫
最近由于参加学校举办短时速学python的比赛,学习了一遍python这门语言,原来一直认为Java语言是最牛逼的,现在发现python也有它的可取之处,它开发快,语言简洁,对于数组的处理,让我发现利用它开发一些简单的程序真的比java快^^
下面,记录一下我利用python实现爬虫,获取百度文库词条其中包含”python”信息的样例(技术Python、Mysql)
1、爬虫架构,以及原理
爬虫重要的架构有三个,分别是URL管理器、网页下载器、网页解析器,还有一个调度器、数据输出器
URL管理器:管理所有的URL,负责取出URL给网页下载器,并将该URL设定为以爬取
网页下载器:将互联网对应的网页下载到本地
网页解析器:解析网页中重要的数据信息(在本样例中为词条信息),并且从该网页中获取其他符合要求的URL,存入Mysql,以便URL管理器取
调度器:类似与java中的main方法,相当于开启爬虫的入口,它负责初始化第一个入口URL(地址),利用while循环依次调用URL管理器、网页下载器、网页解析器完成相关功能。
数据输出器:将得到数据输出
如下图:
2、代码框架
1、利用Mysql数据库,
数据库表baike_spider,账户:root,密码:0203


CREATE TABLE `baike_spider` (
`webSite` varchar(255) DEFAULT NULL,
`isCraw` int(1) DEFAULT '0',
`title` varchar(255) DEFAULT NULL,
`cont` text,
KEY `webSide` (`webSite`) USING HASH
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、源程序框架

3、爬取结果展示:
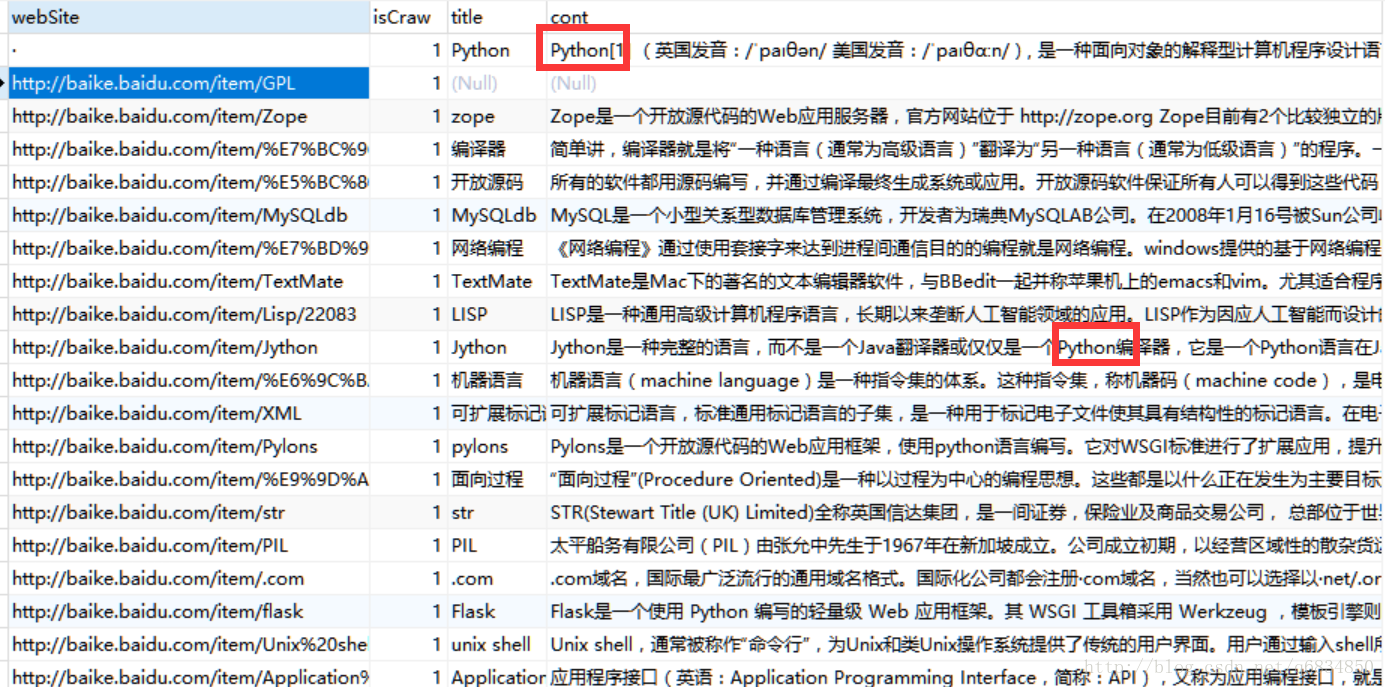
尴尬,显示的python就两三个。。
不过没关系,肯定在没显示出来的地方^_^.
- 3、调度器
# coding=utf-8
# import baike_sider
import url_manager, html_donloader, html_parse, html_outputer
import sys
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
class SpiderMain(object):
def __init__(self):
# 初始化四个管理器
self.urls = url_manager.UrlManager()
self.donloader = html_donloader.HtmlDonload()
self.parse = html_parse.HtmlParse()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, root_url):
# 初始化urls管理器,赋初值
self.urls.init_url(root_url)
# 计算一个count来存储爬虫收集的网站个数
count = 0
# 当url管理器中还存在未被搜刮的网站,循环继续
while self.urls.has_new_url():
try:
# 从URL管理器中获取一个新的url地址
new_url = self.urls.get_new_url()
# 利用网站下载器将其下载下来
cont = self.donloader.donload(new_url)
# 解析器解析cont网站,得到新的urls,和新的数据
urls, new_data = self.parse.parse(new_url, cont)
# 将新的地址存入URL管理器
self.urls.add_new_urls(urls)
# 输出管理器收集这些新信息
if new_data is not None:
self.outputer.collect_data(new_url, new_data)
# 如果爬虫搜刮的网站个数到达1000,停止运行
print "爬完%s,得到%d个新网站,得到信息%s,%s" % (new_url,len(urls),new_data.values()[0],new_data.values()[1])
print "正在爬第%d个网站" % count
if count == 1000:
break
# 统计网站个数加一
count += 1
except Exception,value:
print "craw error :",value
# 返回输出管理器
# return self.outputer
print "craw完毕"
pass
__name__ = "_main_"
if __name__ == "_main_":
root_url = "http://baike.baidu.com/item/Python"
obj_spider = SpiderMain()
obj_spider.craw(root_url)- 4、URL管理器
# coding=utf-8
import MySQLdb as mdb
# try:
# cursor = self.db.cursor()
#
# self.db.commit()
# except Exception,value:
# self.db.rollback()
# print "URLManager.__init__url: ",value
# finally:
# cursor.close()
class UrlManager(object):
def __init__(self):
self.db = mdb.connect("localhost","root","0203","bigData",charset="utf8")
cursor = self.db.cursor()
delete_sql = '''drop table if exists baike_spider'''
create_sql = '''create table if not exists baike_spider(
webSite varchar(255),
isCraw int(1) default '0',
title varchar(255),
cont text,
KEY `webSide` (`webSite`) USING HASH
)'''
try:
cursor.execute(delete_sql)
cursor.execute(create_sql)
cursor.execute("SET NAMES UTF8")
self.db.commit()
except Exception,value:
print "URLManager.__init__Error: ",value
self.db.rollback()
finally:
cursor.close()
pass
def init_url(self, root_url):
try:
cursor = self.db.cursor()
cursor.execute("SET NAMES UTF8")
insert_sql = '''insert into baike_spider(webSite) values('%s')''' % root_url
cursor.execute(insert_sql)
self.db.commit()
except Exception,value:
self.db.rollback()
print "URLManager.__init__url: ",value
finally:
cursor.close()
pass
def has_new_url(self):
new = 0
try:
cursor = self.db.cursor()
cursor.execute("SET NAMES UTF8")
select_sql = '''select isCraw from baike_spider where isCraw=0 limit 1'''
new = cursor.execute(select_sql)
except Exception,value:
print "URLManager.has_new_url: ",value
finally:
cursor.close()
# print 'new=',new
return new
pass
def get_new_url(self):
url = ""
try:
cursor = self.db.cursor()
cursor.execute("SET NAMES UTF8")
select_sql = '''select * from baike_spider where isCraw=0 limit 1'''
cursor.execute(select_sql)
url = cursor.fetchone()[0]
update_sql = '''update baike_spider set isCraw=1 where webSite='%s' '''
cursor.execute(update_sql % url)
self.db.commit()
except Exception,value:
self.db.rollback()
print "URLManager.has_new_url: ",value
finally:
cursor.close()
return url
def add_new_urls(self,urls):
is_exist = '''select isCraw from baike_spider where webSite='%s' '''
insert_sql = '''insert into baike_spider(webSite) values('%s')'''
try:
cursor = self.db.cursor()
cursor.execute("SET NAMES UTF8")
for url in urls:
flag = cursor.execute(is_exist % url)
if flag:continue
else:
cursor.execute(insert_sql % url)
self.db.commit()
except Exception,value:
print "URLManager.add_new_urls: ",value
self.db.rollback()
finally:
cursor.close()
pass
# urlManage = UrlManager()
# urlManage.has_new_url()
# urls = ["http://www.baidu.com","http://www.baidu.com4","http://www.baidu.com2","http://www.baidu.com1","http://www.baidu.com3"]
# print urlManage.add_new_urls(urls)
- 5、网页下载器
# coding=utf-8
import urllib2
class HtmlDonload():
def __init__(self):
pass
def donload(self, url):
cont = ""
try:
response = urllib2.urlopen(url)
if response.getcode()==200:
#读取网页内容
cont = response.read()
#输出内容
# print cont
except Exception,value:
print "HtmlDonload(),Error",value
return cont
pass
# HtmlDonload().donload("http://www.baidu.com")- 6、网页解析器
# coding=utf-8
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParse():
def __init__(self):
pass
def _get_new_urls(self, page_url, soup):
new_urls = set()
links = soup.find_all(name='a', href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
new_full_url = urlparse.urljoin(page_url, new_url)
# print "new_full_url = ",new_full_url
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, url, soup):
res_data = {}
title_node = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data["title",] = title_node.get_text()
summary_node = soup.find("div", class_="lemma-summary")
res_data["summary"] = summary_node.get_text()
# print "res_data = ", res_data
return res_data
def parse(self, url, cont):
if cont is None or url is None:
return
# 将cont传入生成一个beautifulSoup对象
soup = BeautifulSoup(cont, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(url, soup)
new_data = self._get_new_data(url, soup)
return new_urls, new_data
# parse = HtmlParse()
# parse.parse("baidu.html",open("hello.html"))
- 7、数据输出器
# coding=utf-8
import MySQLdb as mdb
class HtmlOutputer():
def __init__(self):
self.db = mdb.connect("localhost","root","0203","bigData",charset="utf8")
pass
def collect_data(self, url, new_data):
try:
cursor = self.db.cursor()
cursor.execute("SET NAMES UTF8")
insert_sql = '''update baike_spider set title='%s',cont='%s' where webSite='%s' '''
data = new_data.values()
cursor.execute(insert_sql % (data[0],data[1],url))
self.db.commit()
except Exception,value:
self.db.rollback()
print "HtmlOutputer.collect_data: ",value
finally:
cursor.close()
pass
def print_data(self):
print 123
try:
cursor = self.db.cursor()
cursor.execute("SET NAMES UTF8")
insert_sql = '''select * from baike_spider where isCraw=1 '''
cursor.execute(insert_sql)
results = cursor.fetchall()
for result in results:
print result[2],result[3]
self.db.commit()
except Exception,value:
self.db.rollback()
print "HtmlOutputer.collect_data: ",value
finally:
cursor.close()
pass
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









