





大家好,相信点进来看的小伙伴都对爬虫非常感兴趣,博主也是一样的。博主刚开始接触爬虫的时候,就被深深吸引了,因为感觉SO COOL啊!每当敲完代码后看着一串串数据在屏幕上浮动,感觉很有成就感,有木有?更厉害的是,爬虫的技术可以应用到很多生活场景中,例如,自动投票啊,批量下载感兴趣的文章、小说、视频啊,微信机器人啊,爬取重要的数据进行数据分析啊,切实的感觉到这些代码是给自己写的,能为自己服务,也能为他人服务,所以人生苦短,我选爬虫。
说实在的,博主也是个朝九晚五的上班族,学习爬虫也是利用业余时间,但就凭着对爬虫的热情开始了爬虫的学习之旅,俗话说嘛,兴趣是最好的老师。博主也是一个小白,开这个公众号的初衷就是想和大家分享一下我学习爬虫的一些经验以及爬虫的技巧,当然网上也有各种各样的爬虫教程都可供大家参考学习,在后面博主会分享一些开始学习时用到的资源。好了,不废话了,开始我们的正题。
1. 什么是爬虫?
首先应该弄明白一件事,就是什么是爬虫,为什么要爬虫,博主百度了一下,是这样解释的:
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
其实,说白了就是爬虫可以模拟浏览器的行为做你想做的事,订制化自己搜索和下载的内容,并实现自动化的操作。比如浏览器可以下载小说,但是有时候并不能批量下载,那么爬虫的功能就有用武之地了。
实现爬虫技术的编程环境有很多种,Java,Python,C++等都可以用来爬虫。但是博主选择了Python,相信很多人也一样选择Python,因为Python确实很适合做爬虫,丰富的第三方库十分强大,简单几行代码便可实现你想要的功能,更重要的,Python也是数据挖掘和分析的好能手。这样爬取数据和分析数据一条龙的服务都用Python真的感觉很棒啊!
2. 爬虫学习路线
知道了什么是爬虫,给大家说说博主总结出的学习爬虫的基本路线吧,只供大家参考,因为每个人都有适合自己的方法,在这里只是提供一些思路。
学习Python爬虫的大致步骤如下:首先学会基本的Python语法知识
学习Python爬虫常用到的几个重要内置库urllib, http等,用于下载网页
学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
开始一些简单的网站爬取(博主从百度开始的,哈哈),了解爬取数据过程
了解爬虫的一些反爬机制,header,robot,时间间隔,代理ip,隐含字段等
学习一些特殊网站的爬取,解决登录、Cookie、动态网页等问题
了解爬虫与数据库的结合,如何将爬取数据进行储存
学习应用Python的多线程、多进程进行爬取,提高爬虫效率
学习爬虫的框架,Scrapy、PySpider等
学习分布式爬虫(数据量庞大的需求)
以上便是一个整体的学习概况,好多内容博主也需要继续学习,关于提到的每个步骤的细节,博主会在后续内容中以实战的例子逐步与大家分享,当然中间也会穿插一些关于爬虫的好玩内容。
3. 从第一个爬虫开始
第一个爬虫代码的实现我想应该是从urllib开始吧,博主开始学习的时候就是使用urllib库敲了几行代码就实现了简单的爬数据功能,我想大多伙伴们也都是这么过来的。当时的感觉就是:哇,好厉害,短短几行竟然就可以搞定一个看似很复杂的任务,于是就在想这短短的几行代码到底是怎么实现的呢,如何进行更高级复杂的爬取呢?带着这个问题我也就开始了urllib库的学习。
首先不得不提一下爬取数据的过程,弄清楚这到底是怎样一个过程,学习urllib的时候会更方便理解。
爬虫的过程
其实,爬虫的过程和浏览器浏览网页的过程是一样的。道理大家应该都明白,就是当我们在键盘上输入网址点击搜索之后,通过网络首先会经过DNS服务器,分析网址的域名,找到了真正的服务器。然后我们通过HTTP协议对服务器发出GET或POST请求,若请求成功,我们就得到了我们想看到的网页,一般都是用HTML, CSS, JS等前端技术来构建的,若请求不成功,服务器会返回给我们请求失败的状态码,常见到的503,403等。
爬虫的过程亦是如此,通过对服务器发出请求得到HTML网页,然后对下载的网页进行解析,得到我们想要的内容。当然,这是一个爬虫过程的一个概况,其中还有很多细节的东西需要我们处理的,这些在后续会继续与大家分享。
了解了爬虫的基本过程后,就可以开始我们真正的爬虫之旅了。
urllib库
Python有一个内置的urllib库,可谓是爬虫过程非常重要的一部分了。这个内置库的使用就可以完成向服务器发出请求并获得网页的功能,所以也是学习爬虫的第一步了。
博主用的是Python3.x,urllib库的结构相对于Python2.x有一些出入,Python2.x中使用的urllib2和urllib库,而Python3.x中合并成一个唯一的urllib库。
首先,我们来看看Python3.x的urllib库都有什么吧。
博主用的IDE是Pycharm,编辑调试非常方便,很赞。
在控制台下输入如下代码:>>importurllib
>>dir(urllib)
['__builtins__','__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__','__path__', '__spec__', 'error', 'parse', 'request', 'response']
可以看到urllib除了以双下划线开头结尾的内置属性外,还有4个重要的属性,分别是error,parse,request,response。
在Python的urllib库中doc开头是这样简短描述的:Error:"Exception classesraised by urllib.”----就是由urllib举出的exception类
Parse:"Parse (absolute andrelative) URLs.”----解析绝对和相对的URLs
Request:"An extensiblelibrary for opening URLs using a variety of protocols”
----用各种协议打开URLs的一个扩展库
Response:"Response classesused by urllib.”----被urllib使用的response类
这4个属性中最重要的当属request了,它完成了爬虫大部分的功能,我们先来看看request是怎么用的。
request的使用
request请求最简单的操作是用urlopen方法,代码如下:import urllib.request
response = urllib.request.urlopen('http://python.org/')
result = response.read()
print(result)
运行结果如下:b'
...
得到的就是我们想要的html的网页了,怎么样,简单吧。
下面来介绍一下这个urlopen方法和其中应用的参数。
urlopen方法def urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TI
MEOUT,*, cafile=None, capath=None,
cadefault=False, context=None):
urlopen是request的其中一个方法,功能是打开一个URL,URL参数可以是一串字符串(如上例子中一样),也可以是Request对象(后面会提到)。url:即是我们输入的url网址,(如:http://www.xxxx.com/);
data:是我们要发给服务器请求的额外信息(比如登录网页需要主动填写的用户信息)。如果需要添加data参数,那么是POST请求,默认无data参数时,就是GET请求;一般来讲,data参数只有在http协议下请求才有意义
data参数被规定为byte object,也就是字节对象
data参数应该使用标准的结构,这个需要使用urllib.parse.urlencode()将data进行 转换,而一般我们把data设置成字典格式再进行转换即可;data在以后实战中会介绍如何使用
timeout:是选填的内容,定义超时时间,单位是秒,防止请求时间过长,不填就是默认的时间;
cafile:是指向单独文件的,包含了一系列的CA认证 (很少使用,默认即可);
capath:是指向文档目标,也是用于CA认证(很少使用,默认即可);
cafile:可以忽略
context:设置SSL加密传输(很少使用,默认即可);
它会返回一个类文件对象,并可以针对这个对象进行各种操作(如上例中的read操作,将html全部读出来),其它常用方法还有:geturl(): 返回URL,用于看是否有重定向。
result = response.geturl()
结果: https://www.python.org/
info():返回元信息,例如HTTP的headers。
result = response.info()
结果:x-xss-protection: 1; mode=block
X-Clacks-Overhead: GNU Terry Pratchett
...
Vary: Cookie
Strict-Transport-Security: max-age=63072000;includeSubDomains
getcode():返回回复的HTTP状态码,成功是200,失败可能是503等,可以用来检查代理IP的可使用性。
result = response.getcode()
结果:200
Request方法class Request:
def __init__(self, url, data=None, headers={},
origin_req_host=None, unverifiable=False,
method=None):
如上定义,Request是一个类,初始化中包括请求需要的各种参数:url,data和上面urlopen中的提到的一样。
headers是HTTP请求的报文信息,如User_Agent参数等,它可以让爬虫伪装成浏览器而不被服务器发现你正在使用爬虫。
origin_reg_host, unverifiable, method等不太常用
headers很有用,有些网站设有反爬虫机制,检查请求若没有headers就会报错,因此博主为保证爬虫的稳定性,基本每次都会将headers信息加入进去,这是反爬的简单策略之一。
那么如何找到你所在浏览器的headers呢?
可以通过进入浏览器F12查看到
比如,博主用的Chrome浏览器,按F12->network就可以查看request的headers,可以把这个浏览器的headers信息复制下来使用。
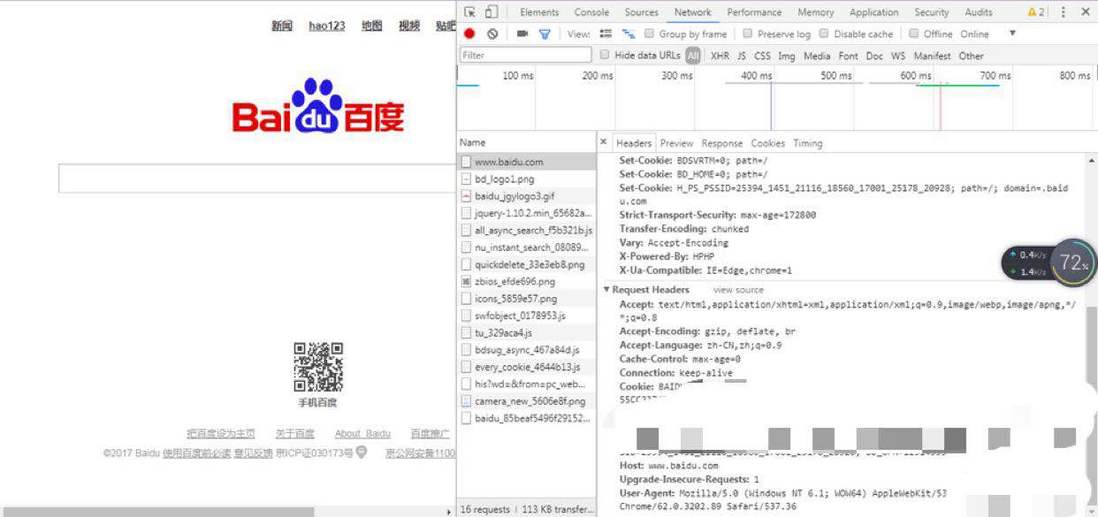
下面来看看Request如何使用吧,代码如下:import urllib.request
headers = {'User_Agent': ''}
response = urllib.request.Request('http://python.org/', headers=headers)
html = urllib.request.urlopen(response)
result = html.read().decode('utf-8')
print(result)
结果和前面urlopen是一样的,前面提到urlopen除了可以接受指定参数,也可以接受Request类的对象。' '里面填写自己浏览器的信息即可。
urllib库的requset属性里面还有很多其它方法,代理、超时、认证、HTTP的POST模式下请求等内容将在下次进行分享,这次主要介绍基本功能。
下面来说说异常,urllib库的error方法。
error的使用
error属性里面主要包括了两个重要的exception类,URLError类和HTTPError类。
1. URLError类def __init__(self, reason, filename=None):
self.args = reason,
self.reason = reason
if filename is not None:
self.filename = filenameURLError类是OSError的子类,继承OSError,没有自己的任何行为特点,但是将作为error里面所有其它类型的基类使用。
URLError类初始化定义了reason参数,意味着当使用URLError类的对象时,可以查看错误的reason。
2. HTTPErro类def __init__(self, url, code, msg, hdrs, fp):
self.code = code
self.msg = msg
self.hdrs = hdrs
self.fp = fp
self.filename = urlHTTPError是URLError的子类,当HTTP发生错误将举出HTTPError。
HTTPError也是HTTP有效回应的实例,因为HTTP协议错误是有效的回应,包括状态码,headers和body。所以看到在HTTPError初始化的时候定义了这些有效回应的参数。
当使用HTTPError类的对象时,可以查看状态码,headers等。
下面我们用一个例子来看一下如何使用这两个exception类。import urllib.request
import urllib.error
try:
headers = {'User_Agent': 'Mozilla/5.0 (X11; Ubuntu;
Linux x86_64; rv:57.0) Gecko/20100101
Firefox/57.0'}
response = urllib.request.Request('http://python.org/',
headers=headers)
html = urllib.request.urlopen(response)
result = html.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'reason'):
print('错误原因是' + str(e.reason))
except urllib.error.HTTPError as e:
if hasattr(e, 'code'):
print('错误状态码是' + str(e.code))
else:
print('请求成功通过。')
以上代码使用了try..exception的结构,实现了简单的网页爬取,当有异常时,如URLError发生时,就会返回reason,或者HTTPError发生错误时就会返回code。异常的增加丰富了爬取的结构,使其更加健壮。
为什么说更加健壮了呢?
不要小看了这些异常的错误,这些异常的错误非常好用,也非常关键。想想看,当你编写一个需要不断自动运行爬取并解析的代码时,你是不希望程序中间被打断而终止的。如果这些异常状态没有设置好,那么就很有可能弹出错误而被终止,但如果设置好了完整的异常,则遇到错误时就会执行发生错误的代码而不被打断(比如向上面代码一样打印错误code等)。
这些打断程序的错误可能是很多种,尤其当你使用代理ip池的时候,会发生很多不同错误,这时异常就起到作用了。
4. 总结介绍了爬虫的定义和学习路线
介绍了爬虫的过程
介绍开始爬虫学习的urllib库的使用,包含以下几个方法:request请求: urlopen, Request
error异常
原创不易,期待你的三连!
关注微信公众号 Python数据科学,回复:666 获取100g学习资料。
个人网站:http://www.datadeepin.com/















 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









