






MapReduce模型简介:
MapReduce最核心的就是Map函数与Reduce函数:
| 函数 | 输入 | 输出 | 说明 |
| Map | <k1,v1> 如: <行号,”a b c”> | List(<k2,v2>) 如: <“a”,1> <“b”,1> <“c”,1> | 1.将小数据集进一步解析成一批<key,value>对,输入Map函数中进行处理 2.每一个输入的<k1,v1>会输出一批<k2,v2>。<k2,v2>是计算的中间结果 |
| Reduce | <k2,List(v2)> 如:<“a”,<1,1,1>> | <k3,v3> <“a”,3> | 输入的中间结果<k2,List(v2)>中的List(v2)表示是一批属于同一个k2的value |
MapReduce的体系结构:
MapReduce主要有以下4个部分组成:
1)Client
2)JobTracker
3)TaskTracker
4)Task
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动
MapReduce各个执行阶段:
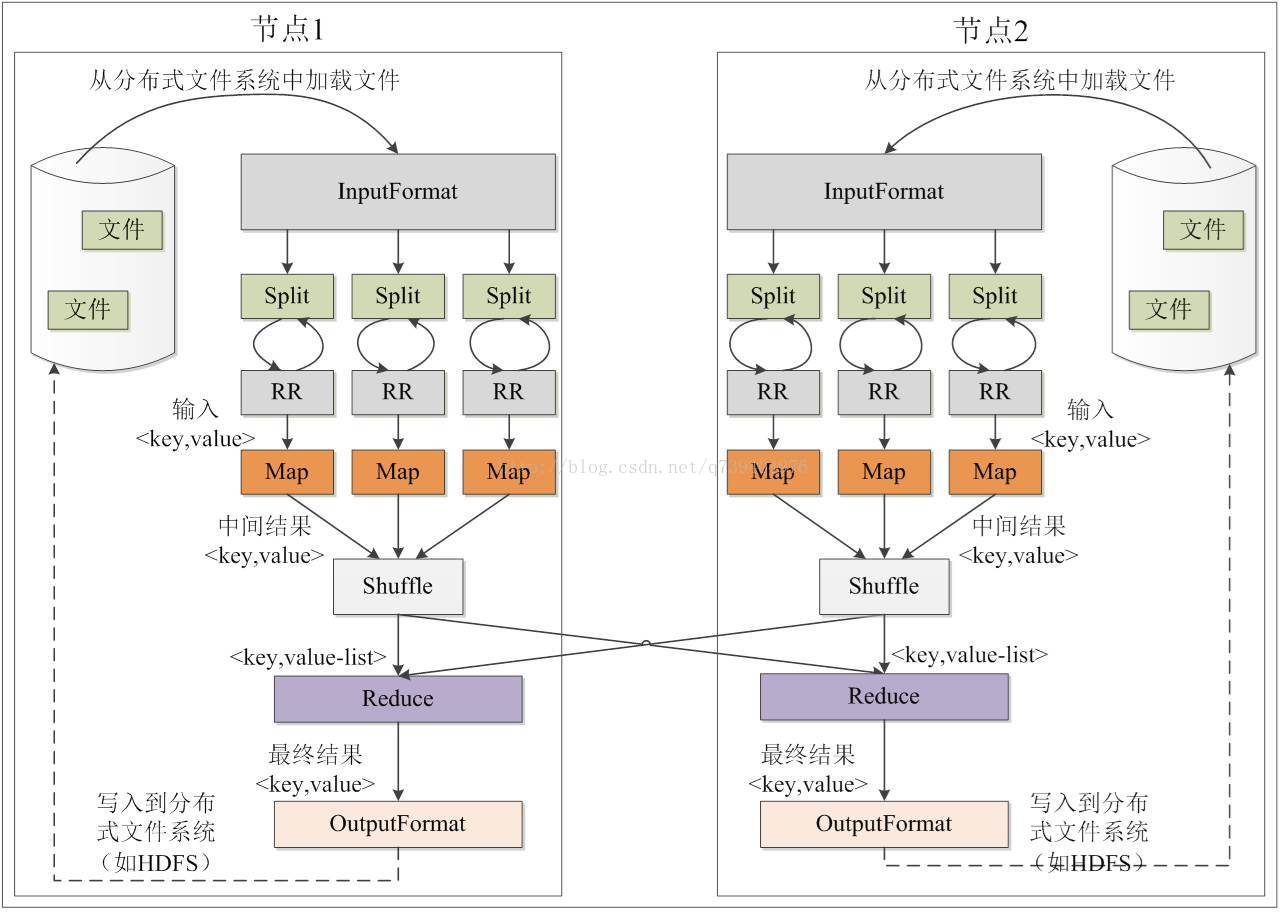
Shuffle过程简介:
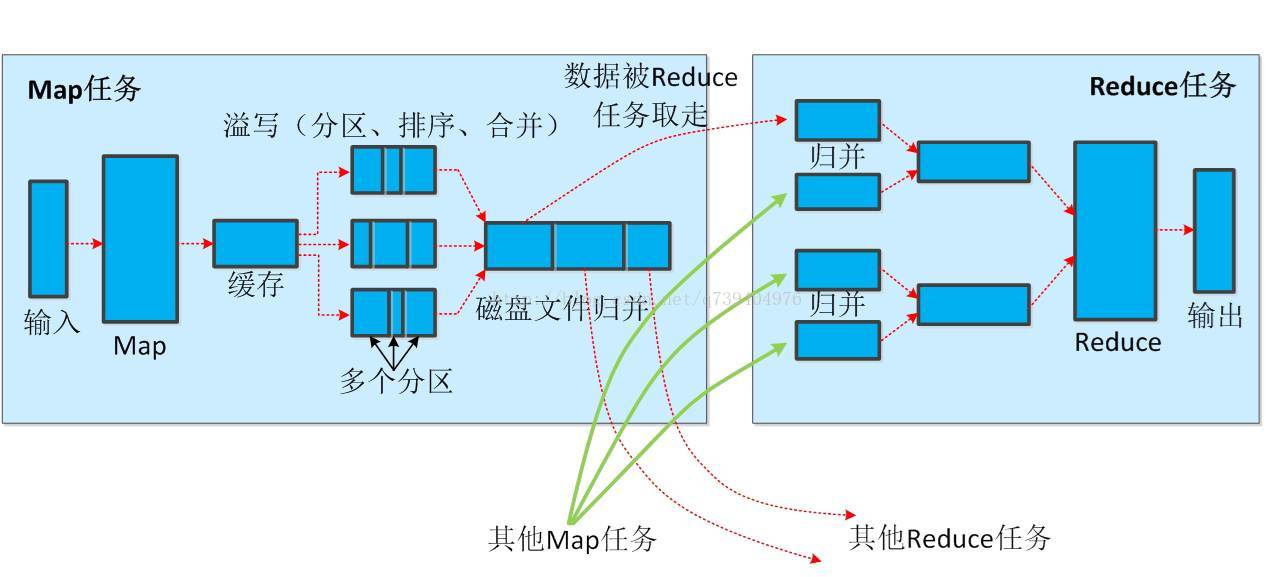
其中Map端的Shuffle过程:
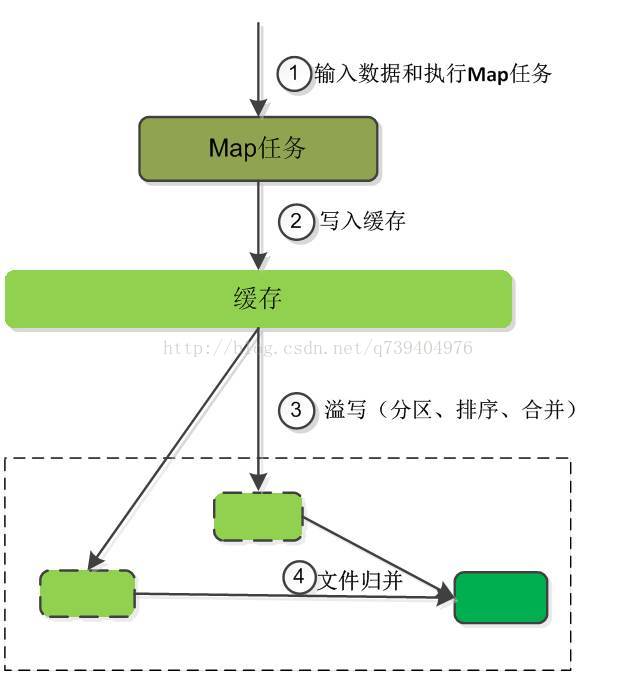
合并(Combine)和归并(Merge)的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>
Reduce端的Shuffle过程:

M a p R e d u c e 作业调度
默认先进先出队列调度模式(FIFO)
– 优先级(very_high、high、normal,low,very low)
static final Comparator<JobSchedulingInfo> FIFO_JOB_QUEUE_COMPARATOR = new
Comparator<JobSchedulingInfo>() {
public int compare(JobSchedulingInfo o1, JobSchedulingInfo o2) {
//比较优先级,若相同则执行下一步
int res = o1.getPriority().compareTo(o2.getPriority());
if (res == 0) {
//比较添加进map任务的时间,若相同则执行下一步
if (o1.getStartTime() < o2.getStartTime()) {
res = -1;
} else {
res = (o1.getStartTime() == o2.getStartTime() ? 0 : 1);
}
}
//最后比较JobID,谁最先创建则谁先执行job任务
if (res == 0) {
res = o1.getJobID().compareTo(o2.getJobID());
}
return res;
}
};















 4182
4182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









