







一、环境包导入
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn.metrics import accuracy_score
import seaborn as sns
import matplotlib
#指定默认字体
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
#解决负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus'] = False
from pyhive import hive
import os
def presto_read_sql_df(sql):
conn=prestodb.dbapi.connect(
host=os.environ['PRESTO_HOST'],
port=os.environ['PRESTO_PORT'],
user=os.environ['JUPYTER_HADOOP_USER'],
password=os.environ['HADOOP_USER_PASSWORD'],
catalog='hive')
cur = conn.cursor()
cur.execute(sql)
query_result = cur.fetchall()
colnames = [part[0] for part in cur.description]
raw = pd.DataFrame(query_result, columns=colnames,dtype=np.float64)
return raw
def hive_read_sql_df(sql):
conn = hive.connect(
host=os.environ['PYHIVE_HOST'],
port=os.environ['PYHIVE_PORT'],
username=os.environ['JUPYTER_HADOOP_USER'],
password=os.environ['HADOOP_USER_PASSWORD'],
auth='LDAP',
configuration={'mapreduce.job.queuename': os.environ['JUPYTER_HADOOP_QUEUE'],
'hive.resultset.use.unique.column.names':'false'})
raw = pd.read_sql_query(sql,conn)
return raw二、数据准备
可以使用SQL直接提取数据,也可以用CSV准备的数据,根据数据量选择合适的方式即可。
# df = hive_read_sql_df("""
# select
# XXXX
# from XXXX
# where dt = '2022-06-30'
# """)
# df.to_csv('file_name.csv',encoding='gbk',sep=',',index = False)data = pd.read_csv('file_name.csv',encoding='gbk')
df = data
df.fillna(0, inplace=True)
#异常数据筛选,可根据自己的需求进行筛选
# df = df[(df['car_age']<10950)&(df['temperature']<50)& (df['iph']< 100 ) ]
df=pd.get_dummies(df) #数据处理 将分类因子转化成0、1值
#抽样5W人,数巨量过大会导致计算分布时无法展示
#df = df.sample(50000) 三、模型构建
# 模型构建参数
# 1、不建议调整
# booster : [default=gbtree] 决定类型 ,gbtree : 树模型 gblinear :线性模型。
# objective :
# binary:logistic 用来二分类
# multi:softmax 用来多分类
# reg:linear 用来回归任务
# silent [default=0]:
# 设为1 则不打印执行信息
# 设为0打印信息
# nthread :控制线程数目
# 2、可根据自身需求调整
# max_depth: 决定树的最大深度,比较重要 常用值4-6 ,深度越深越容易过拟合。
# n_estimators: 构建多少颗数 ,树越多越容易过拟合。
# learning_rate/eta : 学习率 ,范围0-1 。默认值 为0.3 , 常用值0.01-0.2
# subsample: 每次迭代用多少数据集 。
# colsample_bytree: 每次用多少特征 。可以控制过拟合。
# min_child_weight :树的最小权重 ,越小越容易过拟合。
# gamma:如果分裂能够使loss函数减小的值大于gamma,则这个节点才分裂。gamma设置了这个减小的最低阈值。如果gamma设置为0,表示只要使得loss函数减少,就分裂。
# alpha:l1正则,默认为0
# lambda :l2正则,默认为1
y = df.iph
# x = df.drop(['iph'], axis=1) #删除部分无关因子和y
# x = x.drop(['driver_id'],axis=1)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=100)
model = xgb.XGBRegressor (
max_depth=5,
learning_rate=0.1,
n_estimators=200,
silent=0,
objective='reg:linear',
booster='gbtree'
)
model.fit(X_train, y_train)
model.save_model('all_yinzi_50000.model')
四、模型评估
import seaborn as sns
plt.rc("font",family="SimHei",size="10")
plt.rcParams['axes.unicode_minus'] = False
# 对测试集进行预测
y_pred = model.predict(X_test)
# predictions = [round(value) for value in y_pred]
predictions = y_pred
from sklearn import metrics
import numpy
mae = metrics.mean_absolute_error(y_test, predictions)
mse = metrics.mean_squared_error(y_test, predictions)
rmse = numpy.sqrt(metrics.mean_squared_error(y_test, predictions))
r2_square = metrics.r2_score(y_test, predictions)
print('MAE:', mae)
print('MSE:', mse)
print('RMSE:', rmse)
print('R2 Square', r2_square)
print('__________________________________')
#R2 最高值为1 ,越接近1表示拟合程度越好,但要注意过拟合问题五、重要特征展示
# 显示重要特征
# plot_importance(model) #这个根据weight排名
# plt.show()
model.feature_importances_ #这个根据gain排名
# gain
feature_name=pd.DataFrame(x)
feature_info=sorted(dict(zip(feature_name, model.feature_importances_)).items(), key=lambda x:x[1], reverse=True)
feature_info = pd.DataFrame(feature_info,columns=['feature','score'])
# feature_info=feature_info[feature_info['score']>0.01]
plt.figure(figsize = (10 , 20)) #画布尺寸,可根据因子数量进行调整
sns.barplot(feature_info.score, feature_info.feature,palette="Blues_d")
六、因子分布
# !pip install shap==0.34.0 --trusted-host didiyum.sys.xiaojukeji.com
import shap
explainer = shap.TreeExplainer(model, feature_perturbation='tree_path_dependent')
shap_values = explainer.shap_values(X_train)
fig=plt.gcf()
plt.tight_layout()
shap.summary_plot(shap_values, X_train, plot_type='dot', max_display=70,show=False)
plt.tight_layout() 如果能够展现出集中的效果,例如中线(中间的灰线)左右侧颜色分布都比较集中,不存在混杂在一起的情况,则认为这个因子对核心指标的影响相对线性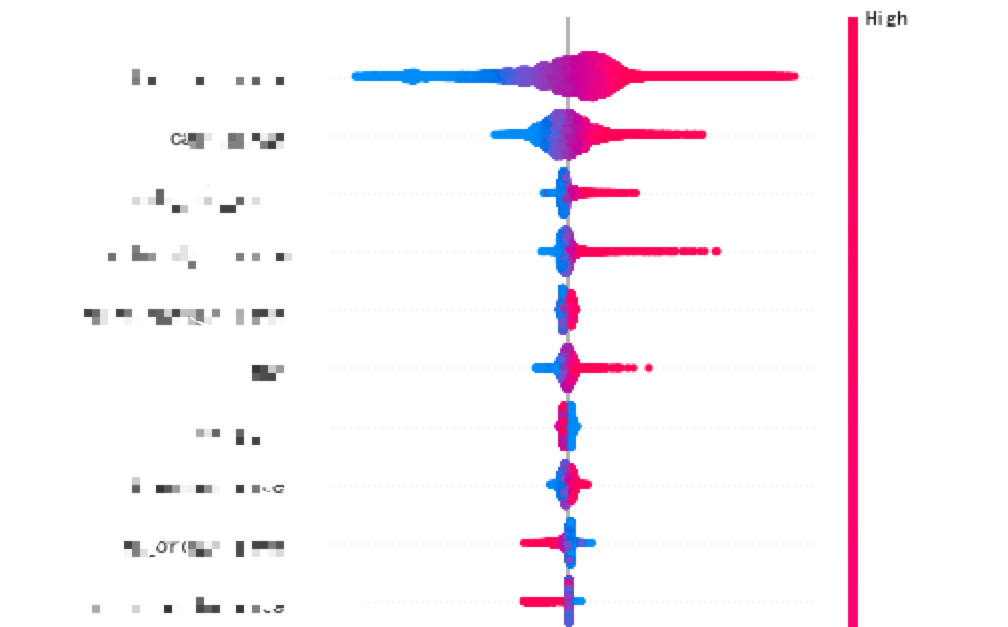
注:粉色->蓝色:值->低 中线左->右:负向->正向
结语:
1、在构建因子时,尽量不要多而全,精简因子选择我们能够有所作为、有抓手的因子,从而确保我们归因后,能够有一定的运营动作,而不是仅仅为了知道到做分析。毕竟分析的尽头是落地。(此处引用阿里人的答案书——没有过程的结果是垃圾,没有结果的过程是放屁)
2、在选择因子时,避免选择结果性指标作为因子,例如,我们发现TPH对IPH的影响最重要,但实际上影响TPH的原因很多,看似找到影响因子,但定位不到问题。那么这个因子就是一个无效因子。

















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











