






Grep 用法
准备test文件,内容如下:

dlf test
dlfthink
www.baidu.com
TEST 123
Dlf's lemon
grep Grep
abc
abc123abc
123dlf123
[www.baidu.com]
1) grep -i "test" test.txt 搜索出含有“test” 字符串(-i:不区分大小)

2) grep -i -n "test" test.txt 搜索出含有“test” 字符串(-i:不区分大小),并打印行号

3) grep -i -n --color "test" test.txt 搜索出含有“test” 字符串(-i:不区分大小),并打印行号,关键字“test”颜色标记(centos7系统默认为grep命令配置了别名,所以不使用—color也能显示颜色)

4) grep -I -c "test" test.txt,打印“test”字符串(不区分大小写)显示的次数
![]()
5) grep -I -o "test" test.txt,打印“test”字符串(不区分大小写),但不打印整行
![]()
test2.txt文件内容如下:

6) grep -A1 “18” test2.txt,打印“18”字符串和它上一行的信息

7) grep -B1 “18” test2.txt,打印“18”字符串和它下一行的信息

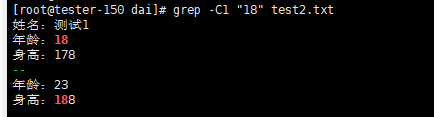
8) grep -C1 “18” test2.txt,打印“18”字符串和它上一行和下一行的信息
9) grep -w "dlf" test.txt,精确匹配出“dlf”字符串的

10) grep -v "dlf" test.txt,匹配出不包含“dlf”字符串的行

11) grep -e 'abc' -e 'dlf' test.txt,同时匹配”abc”和”test”字符串

12) grep -q 静默模式
静默模式下grep不会输入任何信息,无论是否匹配到指定的字符串,都不会输出任何信息,所以配合使用“echo %?”命令,查看命令的执行状态,如果返回值0,证明上一条grep命令匹配到了指定的字符串,如果返回值1,则证明上一条grep命令没有匹配到指定的字符串。

13) grep "^abc" xxx.txt 则搜索xxx.txt文件中abc开头的字符串
grep "abc$" xxx.txt 则搜索xxx.txt文件中abc结尾的字符串
grep 博客园 蒋蒋
几个Perl grep函数的示例
1.统计匹配表达式的列表元素个数
$num_apple=grep/^apple$/i,@fruits;
在标量上下文里,grep返回匹配中的元素个数;在列表上下文里,grep返回匹配中的元素的一个列表。
所以,上述code返回apple单词在@fruits数组中存在的个数。因为$num_apple是个标量,它强迫grep结果位于标量上下文里。
2.从列表里抽取唯一元素
- @unique=grep{++$count{$_}<2}
- qw(abacddefgfhh);
- print"@unique\n";
上述code运行后会返回:abcdefgh 即qw(abacddefgfhh)这个列表里的唯一元素被返回了。为什么会这样呀?让我们看看:
%count是个hash结构,它的key是遍历qw()列表时,逐个抽取的列表元素。++$count{$_}表示$_对应的hash值自增。在这个比较上下文里,++$count{$_}与$count{$_}++的意义是不一样的哦,前者表示在比较之前,就将自身值自增1;后者表示在比较之后,才将自身值自增1。所以,++$count{$_}<2表示将$count{$_}加1,然后与2进行比较。$count{$_}值默认是undef或0。所以当某个元素a第一次被当作hash的关键字时,它自增后对应的hash值就是1,当它第二次当作hash关键字时,对应的hash值就变成2了。变成2后,就不满足比较条件了,所以a不会第2次出现。
所以上述code就能从列表里唯一1次的抽取元素了。
◆抽取列表里精确出现2次的元素
- @crops=qw(my love is china my wife li shan love);
- @duplicates=grep{$count{$_}==2} grep{++$count{$_}>;1}@crops;
- print"@duplicates\n";
运行结果是:my
这里grep了2次哦,顺序是从右至左。首先grep{++$count{$_}>;1}@crops;返回一个列表,列表的结果是@crops里出现次数大于1的元素。 然后再对产生的临时列表进行grep{$count{$_}==2}计算,这里的意思你也该明白了,就是临时列表里,元素出现次数等于2的被返回。
所以上述code就返回rice了,rice出现次数大于1,并且精确等于2,明白了吧?:-)
3.在当前目录里列出文本文件
- @files=grep{-fand-T}glob'*.*';
- print"@filesn";
这个就很容易理解哦。glob返回一个列表,它的内容是当前目录里的任何文件,除了以'.'开头的。{}是个code块,它包含了匹配它后面的列表的条件。这只是grep的另一种用法,其实与grepEXPR,LIST这种用法差不多了。-fand-T匹配列表里的元素,首先它必须是个普通文件,接着它必须是个文本文件。据说这样写效率高点哦,因为-T开销更大,所以在判断-T前,先判断-f了。
4.选择数组元素并消除重复
- @array=qw(To be or not to be that is the question);
- @found_words= grep{$_=~/b|o/i and++$counts{$_}<2;}@array;
- print"@found_words\n";
运行结果是:To be or not to question
{}里的意思就是,对@array里的每个元素,先匹配它是否包含b或o字符(不分大小写),然后每个元素出现的次数,必须小于2(也就是1次啦)。 grep返回一个列表,包含了@array里满足上述2个条件的元素。
5.从二维数组里选择元素,并且x
- #Anarrayofreferencestoanonymousarrays
- @data_points=([5,12],[20,-3],
- [2,2],[13,20]);
- @y_gt_x=grep{$_->;[0]<$_->;[1]}@data_points;
- foreach$xy(@y_gt_x){print"$xy->;[0],$xy->;[1]\n"}
运行结果是: 5,12 13,20
这里,你应该理解匿名数组哦,[]是个匿名数组,它实际上是个数组的引用(类似于C里面的指针)。 @data_points的元素就是匿名数组。例如:
foreach(@data_points){ print$_->;[0];}
这样访问到匿名数组里的第1个元素,把0替换成1就是第2个元素了。
Grep
字符类
字符类的搜索:如果我想要搜寻 test 或 taste 这两个单字时,可以发现到,其实她们有共通的 't?st' 存在~这个时候,我可以这样来搜寻:
[root@www ~]# grep -n 't[ae]st' regular_express.txt
8:I can't finish the test.
9:Oh! The soup taste good.
其实 [] 里面不论有几个字节,他都仅代表某『一个』字节, 所以,上面的例子说明了,我需要的字串是『tast』或『test』两个字串而已!
字符类的反向选择 [^] :如果想要搜索到有 oo 的行,但不想要 oo 前面有 g,如下
[root@www ~]# grep -n '[^g]oo' regular_express.txt
2:apple is my favorite food.
3:Football game is not use feet only.
18:google is the best tools for search keyword. #后面出现了 tool 的 too
19:goooooogle yes! # goooooogle 里面的 oo 前面可能是 o
字符类的连续:假设我 oo 前面不想要有小写字节,所以,我可以这样写 [^abcd....z]oo ,
[root@www ~]# grep -n '[^a-z]oo' regular_express.txt
3:Football game is not use feet only.
当我们在一组集合字节中,如果该字节组是连续的,例如大写英文/小写英文/数字等等, 就可以使用[a-z],[A-Z],[0-9]等方式来书写,那么如果我们的要求字串是数字与英文呢?就将他全部写在一起,变成:[a-zA-Z0-9]。
我们要取得有数字的那一行,就这样:
[root@www ~]# grep -n '[0-9]' regular_express.txt
5:However, this dress is about $ 3183 dollars.
15:You are the best is mean you are the no. 1.
行首与行尾字节 ^ $
行首字符:如果我想要让 the 只在行首列出呢? 这个时候就得要使用定位字节了!
[root@www ~]# grep -n '^the' regular_express.txt
12:the symbol '*' is represented as start.
此时,就只剩下第 12 行,因为只有第 12 行的行首是 the 开头啊~此外, 如果我想要开头是小写字节的那一行就列出呢?可以这样:
[root@www ~]# grep -n '^[a-z]' regular_express.txt
2:apple is my favorite food.
4:this dress doesn't fit me.
10:motorcycle is cheap than car.
12:the symbol '*' is represented as start.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
如果我不想要开头是英文字母,则可以是这样:
[root@www ~]# grep -n '^[^a-zA-Z]' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
21:# I am VBird
^ 符号,在字符类符号(括号[])之内与之外是不同的! 在 [] 内代表『反向选择』,在 [] 之外则代表定位在行首的意义
那如果我想要找出来,行尾结束为小数点 (.) 的那一行:
[root@www ~]# grep -n '\.$' regular_express.txt #转义字符
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
4:this dress doesn't fit me.
10:motorcycle is cheap than car.
11:This window is clear.
12:the symbol '*' is represented as start.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
17:I like dog.
18:google is the best tools for search keyword.
20:go! go! Let's go.
因为小数点具有其他意义,所以必须要使用转义字符(\)来加以解除其特殊意义!
找出空白行: 因为只有行首跟行尾 (^$),所以,这样就可以找出空白行啦!
[root@www ~]# grep -n '^$' regular_express.txt
22:
任意一个字节 . 与重复字节 *
这两个符号在正则表达式的意义如下:
. (小数点):代表『一定有一个任意字节』的意思;
* (星号):代表『重复前一个字符, 0 到无穷多次』的意思,为组合形态
假设我需要找出 g??d 的字串,亦即共有四个字节, 起头是 g 而结束是 d ,我可以这样做:
[root@www ~]# grep -n 'g..d' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
9:Oh! The soup taste good.
16:The world <Happy> is the same with "glad".
如果我想要列出有 oo, ooo, oooo 等等的数据, 也就是说,至少要有两个(含) o 以上,该如何是好?
因为 * 代表的是『重复 0 个或多个前面的 RE 字符』的意义, 因此,『o*』代表的是:『拥有空字节或一个 o 以上的字节』,因此,『 grep -n 'o*' regular_express.txt 』将会把所有的数据都列印出来终端上!
当我们需要『至少两个 o 以上的字串』时,就需要 ooo* ,亦即是:
[root@www ~]# grep -n 'ooo*' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! The soup taste good.
18:google is the best tools for search keyword.
19:goooooogle yes!
如果我想要字串开头与结尾都是 g,但是两个 g 之间仅能存在至少一个 o ,亦即是 gog, goog, gooog.... 等等,那该如何?
[root@www ~]# grep -n 'goo*g' regular_express.txt
18:google is the best tools for search keyword.
19:goooooogle yes!
如果我想要找出 g 开头与 g 结尾的行,当中的字符可有可无
[root@www ~]# grep -n 'g.*g' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
14:The gd software is a library for drafting programs.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
喔! 这个 .* 的 RE 表示任意字符是很常见的.
如果我想要找出『任意数字』的行?因为仅有数字,所以就成为:
[root@www ~]# grep -n '[0-9][0-9]*' regular_express.txt
5:However, this dress is about $ 3183 dollars.
15:You are the best is mean you are the no. 1.
限定连续 RE 字符范围 {}
我们可以利用 . 与 RE 字符及 * 来配置 0 个到无限多个重复字节, 那如果我想要限制一个范围区间内的重复字节数呢?
举例来说,我想要找出两个到五个 o 的连续字串,该如何作?这时候就得要使用到限定范围的字符 {} 了。 但因为 { 与 } 的符号在 shell 是有特殊意义的,因此, 我们必须要使用字符 \ 来让他失去特殊意义才行。 至於 {} 的语法是这样的,假设我要找到两个 o 的字串,可以是:
[root@www ~]# grep -n 'o\{2\}' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! The soup taste good.
18:google is the best tools for search ke
19:goooooogle yes! #oo oo oo 如果是单数,如ooo,只会识别其中前两个。
假设我们要找出 g 后面接 2 到 5 个 o ,然后再接一个 g 的字串,他会是这样:
[root@www ~]# grep -n 'go\{2,5\}g' regular_express.txt
18:google is the best tools for search keyword.
如果我想要的是 2 个 o 以上的 goooo....g 呢?除了可以是 gooo*g ,也可以是:
[root@www ~]# grep -n 'go\{2,\}g' regular_express.txt
18:google is the best tools for search keyword.
19:goooooogle yes!
扩展grep(grep -E 或者 egrep):
使用扩展grep的主要好处是增加了额外的正则表达式元字符集。
打印所有包含NW或EA的行。如果不是使用egrep,而是grep,将不会有结果查出。
# egrep 'NW|EA' testfile
northwest NW Charles Main 3.0 .98 3 34
eastern EA TB Savage 4.4 .84 5 20
对于标准grep,如果在扩展元字符前面加\,grep会自动启用扩展选项-E。
#grep 'NW\|EA' testfile
northwest NW Charles Main 3.0 .98 3 34
eastern EA TB Savage 4.4 .84 5 20
搜索所有包含一个或多个3的行。
# egrep '3+' testfile
# grep -E '3+' testfile
# grep '3\+' testfile
#这3条命令将会
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
northeast NE AM Main Jr. 5.1 .94 3 13
central CT Ann Stephens 5.7 .94 5 13
搜索所有包含0个或1个小数点字符的行。
# egrep '2\.?[0-9]' testfile
# grep -E '2\.?[0-9]' testfile
# grep '2\.\?[0-9]' testfile
#首先含有2字符,其后紧跟着0个或1个点,后面再是0和9之间的数字。
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
eastern EA TB Savage 4.4 .84 5 20
搜索一个或者多个连续的no的行。
# egrep '(no)+' testfile
# grep -E '(no)+' testfile
# grep '\(no\)\+' testfile #3个命令返回相同结果,
northwest NW Charles Main 3.0 .98 3 34
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5
9
grep用法详解:grep与正则表达式
首先要记住的是: 正则表达式与通配符不一样,它们表示的含义并不相同!
正则表达式只是一种表示法,只要工具支持这种表示法,那么该工具就可以处理正则表达式的字符串。vi grep ,awk ,sed 等都支持正则表达式.
1基础正则表达式
grep 工具,以前介绍过。
grep -[acinv] '搜索内容串' filename
-a 以文本文件方式搜索
-c 计算找到的符合行的次数
-i 忽略大小写
-n 顺便输出行号
-v 反向选择,即找 没有搜索字符串的行
其中搜索串可以是正则表达式!
1
搜索有the的行,并输出行号
$grep -n 'the' regular_express.txt
搜索没有the的行,并输出行号
$grep -nv 'the' regular_express.txt
2 利用[]搜索集合字符
[] 表示其中的某一个字符 ,例如[ade] 表示a或d或e
woody@xiaoc:~/tmp$ grep -n 't[ae]st' regular_express.txt
8:I can't finish the test.
9:Oh! the soup taste good!
可以用^符号做[]内的前缀,表示除[]内的字符之外的字符。
比如搜索oo前没有g的字符串所在的行. 使用 '[^g]oo' 作搜索字符串
woody@xiaoc:~/tmp$ grep -n '[^g]oo' regular_express.txt
2:apple is my favorite food.
3:Football game is not use feet only.
18:google is the best tools for search keyword.
19:goooooogle yes!
[] 内可以用范围表示,比如[a-z] 表示小写字母,[0-9] 表示0~9的数字, [A-Z] 则是大写字母们。[a-zA-Z0-9]表示所有数字与英文字符。 当然也可以配合^来排除字符。
搜索包含数字的行
woody@xiaoc:~/tmp$ grep -n '[0-9]' regular_express.txt
5:However ,this dress is about $ 3183 dollars.
15:You are the best is menu you are the no.1.
行首与行尾字符 ^ $.
^ 表示行的开头,$表示行的结尾( 不是字符,是位置)那么‘^$’ 就表示空行,因为只有行首和行尾。
这里^与[]里面使用的^意义不同。它表示^后面的串是在行的开头。
比如搜索the在开头的行
woody@xiaoc:~/tmp$ grep -n '^the' regular_express.txt
12:the symbol '*' is represented as star.
搜索以小写字母开头的行
woody@xiaoc:~/tmp$ grep -n '^[a-z]' regular_express.txt
2:apple is my favorite food.
4:this dress doesn't fit me.
10:motorcycle is cheap than car.
12:the symbol '*' is represented as star.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
woody@xiaoc:~/tmp$
搜索开头不是英文字母的行
woody@xiaoc:~/tmp$ grep -n '^[^a-zA-Z]' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
21:#I am VBird
woody@xiaoc:~/tmp$
$表示它前面的串是在行的结尾,比如 '\.' 表示 . 在一行的结尾
搜索末尾是.的行
woody@xiaoc:~/tmp$ grep -n '\.$' regular_express.txt //. 是正则表达式的特殊符号,所以要用\转义
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
4:this dress doesn't fit me.
5:However ,this dress is about $ 3183 dollars.
6:GNU is free air not free beer.
.....
注意在MS的系统下生成的文本文件,换行会加上一个 ^M 字符。所以最后的字符会是隐藏的^M ,在处理Windows
下面的文本时要特别注意!
可以用cat dos_file | tr -d '\r' > unix_file 来删除^M符号。 ^M==\r
那么'^$' 就表示只有行首行尾的空行拉!
搜索空行
woody@xiaoc:~/tmp$ grep -n '^$' regular_express.txt
22:
23:
woody@xiaoc:~/tmp$
搜索非空行
woody@xiaoc:~/tmp$ grep -vn '^$' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
4:this dress doesn't fit me.
..........
任意一个字符. 与重复字符 *
在bash中*代表通配符,用来代表任意个字符,但是在正则表达式中,他含义不同,*表示有0个或多个 某个字符。
例如 oo*, 表示第一个o一定存在,第二个o可以有一个或多个,也可以没有,因此代表至少一个o.
点. 代表一个任意字符,必须存在。 g??d 可以用 'g..d' 表示。 good ,gxxd ,gabd .....都符合。
woody@xiaoc:~/tmp$ grep -n 'g..d' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
9:Oh! the soup taste good!
16:The world is the same with 'glad'.
woody@xiaoc:~/tmp$
搜索两个o以上的字符串
woody@xiaoc:~/tmp$ grep -n 'ooo*' regular_express.txt //前两个o一定存在,第三个o可没有,也可有多个。
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! the soup taste good!
18:google is the best tools for search keyword.
19:goooooogle yes!
搜索g开头和结尾,中间是至少一个o的字符串,即gog, goog....gooog...等
woody@xiaoc:~/tmp$ grep -n 'goo*g' regular_express.txt
18:google is the best tools for search keyword.
19:goooooogle yes!
搜索g开头和结尾的字符串在的行
woody@xiaoc:~/tmp$ grep -n 'g.*g' regular_express.txt // .*表示 0个或多个任意字符
1:"Open Source" is a good mechanism to develop programs.
14:The gd software is a library for drafting programs.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
限定连续重复字符的范围 { }
. * 只能限制0个或多个, 如果要确切的限制字符重复数量,就用{范围} 。范围是数字用,隔开 2,5 表示2~5个,
2表示2个,2, 表示2到更多个
注意,由于{ }在SHELL中有特殊意义,因此作为正则表达式用的时候要用\转义一下。
搜索包含两个o的字符串的行。
woody@xiaoc:~/tmp$ grep -n 'o\{2\}' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! the soup taste good!
18:google is the best tools for search keyword.
19:goooooogle yes!
搜索g后面跟2~5个o,后面再跟一个g的字符串的行。
woody@xiaoc:~/tmp$ grep -n 'go\{2,5\}g' regular_express.txt
18:google is the best tools for search keyword.
搜索包含g后面跟2个以上o,后面再跟g的行。。
woody@xiaoc:~/tmp$ grep -n 'go\{2,\}g' regular_express.txt
18:google is the best tools for search keyword.
19:goooooogle yes!
注意,相让[]中的^ - 不表现特殊意义,可以放在[]里面内容的后面。
'[^a-z\.!^ -]' 表示没有小写字母,没有. 没有!, 没有空格,没有- 的 串,注意[]里面有个小空格。
另外shell 里面的反向选择为[!range], 正则里面是 [^range]
2扩展正则表达式
扩展正则表达式是对基础正则表达式添加了几个特殊构成的。
它令某些操作更加方便。
比如我们要去除 空白行和行首为 #的行, 会这样用:
woody@xiaoc:~/tmp$ grep -v '^$' regular_express.txt | grep -v '^#'
"Open Source" is a good mechanism to develop programs.
apple is my favorite food.
Football game is not use feet only.
this dress doesn't fit me.
............
然而使用支持扩展正则表达式的 egrep 与扩展特殊符号 | ,会方便许多。
注意grep只支持基础表达式, 而egrep 支持扩展的,其实 egrep 是 grep -E 的别名而已。因此grep -E 支持扩展正则。
那么:
woody@xiaoc:~/tmp$ egrep -v '^$|^#' regular_express.txt
"Open Source" is a good mechanism to develop programs.
apple is my favorite food.
Football game is not use feet only.
this dress doesn't fit me.
....................
这里| 表示或的关系。 即满足 ^$ 或者 ^# 的字符串。
这里列出几个扩展特殊符号:
+,于 . * 作用类似,表示 一个或多个重复字符。
?, 于 . * 作用类似,表示0个或一个字符。
|,表示或关系,比如 'gd|good|dog' 表示有gd,good或dog的串
(),将部分内容合成一个单元组。比如 要搜索 glad 或 good 可以这样 'g(la|oo)d'
()的好处是可以对小组使用 + ? * 等。
比如要搜索A和C开头结尾,中间有至少一个(xyz) 的串,可以这样 : 'A(xyz)+C'
◎grep -- print lines matching a pattern (将符合样式的该行列出)
◎语法: grep [options]
PATTERN [FILE...]
grep用以在file内文中比对相对应的部分,或是当没有指定档案时,
由标准输入中去比对。在预设的情况下,grep会将符合样式的那一行列出。
此外,还有两个程式是grep的变化型,egrep及fgrep。
其中egrep就等同於grep -E ,fgrep等同於grep -F 。
◎参数
1. -A NUM,--after-context=NUM
除了列出符合行之外,并且列出後NUM行。
ex: $ grep -A 1 panda file
(从file中搜寻有panda样式的行,并显示该行的後1行)
2. -a或--text
grep原本是搜寻文字档,若拿二进位的档案作为搜寻的目标,
则会显示如下的讯息: Binary file 二进位档名 matches 然後结束。
若加上-a参数则可将二进位档案视为文字档案搜寻,
相当於--binary-files=text这个参数。
ex: (从二进位档案mv中去搜寻panda样式)
(错误!!!)
$ grep panda mv
Binary file mv matches
(这表示此档案有match之处,详见--binary-files=TYPE )
$
(正确!!!)
$ grep -a panda mv
3. -B NUM,--before-context=NUM
与 -A NUM 相对,但这此参数是显示除符合行之外
并显示在它之前的NUM行。
ex: (从file中搜寻有panda样式的行,并显示该行的前1行)
$ grep -B 1 panda file
4. -C [NUM], -NUM, --context[=NUM]
列出符合行之外并列出上下各NUM行,预设值是2。
ex: (列出file中除包含panda样式的行外并列出其上下2行)
(若要改变预设值,直接改变NUM即可)
$ grep -C[NUM] panda file
5. -b, --byte-offset
列出样式之前的内文总共有多少byte ..
ex: $ grep -b panda file
显示结果类似於:
0:panda
66:pandahuang
123:panda03
6. --binary-files=TYPE
此参数TYPE预设为binary(二进位),若以普通方式搜寻,只有2种结果:
1.若有符合的地方:显示Binary file 二进位档名 matches
2.若没有符合的地方:什麽都没有显示。
若TYPE为without-match,遇到此参数,
grep会认为此二进位档案没有包含任何搜寻样式,与-I 参数相同。
若TPYE为text, grep会将此二进位档视为text档案,与-a 参数相同。
Warning: --binary-files=text 若输出为终端机,可能会产生一些不必要的输出。
7. -c, --count
不显示符合样式行,只显示符合的总行数。
若再加上-v,--invert-match,参数显示不符合的总行数。
8. -d ACTION, --directories=ACTION
若输入的档案是一个资料夹,使用ACTION去处理这个资料夹。
预设ACTION是read(读取),也就是说此资料夹会被视为一般的档案;
若ACTION是skip(略过),资料夹会被grep略过:
若ACTION是recurse(递),grep会去读取资料夹下所有的档案,
此相当於-r 参数。
9. -E, --extended-regexp
采用规则表示式去解释样式。
10. -e PATTERN, --regexp=PATTERN
把样式做为一个partern,通常用在避免partern用-开始。
11. -f FILE, --file=FILE
事先将要搜寻的样式写入到一个档案,一行一个样式。
然後采用档案搜寻。
空的档案表示没有要搜寻的样式,因此也就不会有任何符合。
ex: (newfile为搜寻样式档)
$grep -f newfile file
12. -G, --basic-regexp
将样式视为基本的规则表示式解释。(此为预设)
13. -H, --with-filename
在每个符合样式行前加上符合的档案名称,若有路径会显示路径。
ex: (在file与testfile中搜寻panda样式)
$grep -H panda file ./testfile
file:panda
./testfile:panda
$
14. -h, --no-filename
与-H参数相类似,但在输出时不显示路径。
15. --help
产生简短的help讯息。
16. -I
grep会强制认为此二进位档案没有包含任何搜寻样式,
与--binary-files=without-match参数相同。
ex: $ grep -I panda mv
17. -i, --ignore-case
忽略大小写,包含要搜寻的样式及被搜寻的档案。
ex: $ grep -i panda mv
18. -L, --files-without-match
不显示平常一般的输出结果,反而显示出没有符合的档案名称。
19. -l, --files-with-matches
不显示平常一般的输出结果,只显示符合的档案名称。
20. --mmap
如果可能,使用mmap系统呼叫去读取输入,而不是预设的read系统呼叫。
在某些状况,--mmap 能产生较好的效能。然而,--mmap
如果运作中档案缩短,或I/O 错误发生时,
可能造成未定义的行为(包含core dump),。
21. -n, --line-number
在显示行前,标上行号。
ex: $ grep -n panda file
显示结果相似於下:
行号:符合行的内容
22. -q, --quiet, --silent
不显示任何的一般输出。请参阅-s或--no-messages
23. -r, --recursive
递地,读取每个资料夹下的所有档案,此相当於 -d recsuse 参数。
24. -s, --no-messages
不显示关於不存在或无法读取的错误讯息。
小: 不像GNU grep,传统的grep不符合POSIX.2协定,
因为缺乏-q参数,且他的-s 参数表现像GNU grep的 -q 参数。
Shell Script倾向将传统的grep移植,避开-q及-s参数,
且将输出限制到/dev/null。
POSIX: 定义UNIX及UNIX-like系统需要提供的功能。
25. -V, --version
显示出grep的版本号到标准错误。
当您在回报有关grep的bugs时,grep版本号是必须要包含在内的。
26. -v, --invert-match
显示除搜寻样式行之外的全部。
27. -w, --word-regexp
将搜寻样式视为一个字去搜寻,完全符合该"字"的行才会被列出。
28. -x, --line-regexp
grep参数
1. -c 显示匹配的行数(就是显示有多少行匹配了);
2. -n 显示匹配内容所在文档的行号;
3. -i 匹配时忽略大小写;
4. -s 错误信息不输出;
5. -v 输出不匹配内容;
6. -x 输出完全匹配内容;
7. \ 忽略表达式中字符原有含义;
8. ^ 匹配表达式的开始行;
9. $ 匹配表达式的结束行;
10. \< 从匹配表达式的行开始;
11. \> 到匹配表达式的行结束;
12. [ ] 单个字符(如[A] 即A符合要求);
13. [ - ] 范围;如[A-Z]即A,B,C一直到Z都符合要求;
14. . 所有的单个字符;
15. * 所有字符,长度可以为0
| [精华] Grep 用法 | |
|
Linux grep 命令
Linux grep 命令用于查找文件里符合条件的字符串。
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
语法
grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
参数:
- -a 或 --text : 不要忽略二进制的数据。
- -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
- -B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
- -c 或 --count : 计算符合样式的列数。
- -C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
- -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
- -e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
- -E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。
- -f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
- -F 或 --fixed-regexp : 将样式视为固定字符串的列表。
- -G 或 --basic-regexp : 将样式视为普通的表示法来使用。
- -h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
- -H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
- -i 或 --ignore-case : 忽略字符大小写的差别。
- -l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
- -L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
- -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
- -o 或 --only-matching : 只显示匹配PATTERN 部分。
- -q 或 --quiet或--silent : 不显示任何信息。
- -r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
- -s 或 --no-messages : 不显示错误信息。
- -v 或 --invert-match : 显示不包含匹配文本的所有行。
- -V 或 --version : 显示版本信息。
- -w 或 --word-regexp : 只显示全字符合的列。
- -x --line-regexp : 只显示全列符合的列。
- -y : 此参数的效果和指定"-i"参数相同。
实例
1、在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令:
grep test *file
结果如下所示:
$ grep test test* #查找前缀有“test”的文件包含“test”字符串的文件
testfile1:This a Linux testfile! #列出testfile1 文件中包含test字符的行
testfile_2:This is a linux testfile! #列出testfile_2 文件中包含test字符的行
testfile_2:Linux test #列出testfile_2 文件中包含test字符的行
2、以递归的方式查找符合条件的文件。例如,查找指定目录/etc/acpi 及其子目录(如果存在子目录的话)下所有文件中包含字符串"update"的文件,并打印出该字符串所在行的内容,使用的命令为:
grep -r update /etc/acpi
输出结果如下:
$ grep -r update /etc/acpi #以递归的方式查找“etc/acpi”
#下包含“update”的文件
/etc/acpi/ac.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.)
Rather than
/etc/acpi/resume.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of
IO.) Rather than
/etc/acpi/events/thinkpad-cmos:action=/usr/sbin/thinkpad-keys--update
3、反向查找。前面各个例子是查找并打印出符合条件的行,通过"-v"参数可以打印出不符合条件行的内容。
查找文件名中包含 test 的文件中不包含test 的行,此时,使用的命令为:
grep -v test *test*
结果如下所示:
$ grep-v test* #查找文件名中包含test 的文件中不包含test 的行
testfile1:helLinux!
testfile1:Linis a free Unix-type operating system.
testfile1:Lin
testfile_1:HELLO LINUX!
testfile_1:LINUX IS A FREE UNIX-TYPE OPTERATING SYSTEM.
testfile_1:THIS IS A LINUX TESTFILE!
testfile_2:HELLO LINUX!
testfile_2:Linux is a free unix-type opterating system.
2 篇笔记 写笔记
- free-coder
sun***1@126.com
82
场景: 系统报警显示了时间,但是日志文件太大无法直接 cat 查看。(查询含有特定文本的文件,并拿到这些文本所在的行)
解决:
grep -n '2019-10-24 00:01:11' *.log
查看符合条件的日志条目。
free-coder
sun***1@126.com
2年前 (2019-10-23)
- XRG
233***0962@qq.com
130
Linux 里利用 grep 和 find 命令查找文件内容
从文件内容查找匹配指定字符串的行:
$ grep "被查找的字符串" 文件名
例子:在当前目录里第一级文件夹中寻找包含指定字符串的 .in 文件
grep "thermcontact" /.in
从文件内容查找与正则表达式匹配的行:
$ grep –e "正则表达式" 文件名
查找时不区分大小写:
$ grep –i "被查找的字符串" 文件名
查找匹配的行数:
$ grep -c "被查找的字符串" 文件名
从文件内容查找不匹配指定字符串的行:
$ grep –v "被查找的字符串" 文件名
从根目录开始查找所有扩展名为 .log 的文本文件,并找出包含 "ERROR" 的行:
$ find / -type f -name "*.log" | xargs grep "ERROR"
例子:从当前目录开始查找所有扩展名为 .in 的文本文件,并找出包含 "thermcontact" 的行:
find . -name "*.in" | xargs grep "thermcontact"
XRG
233***0962@qq.com
简介
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
命令格式:grep [option] pattern file
grep的常用选项:
-V: 打印grep的版本号
-E: 解释PATTERN作为扩展正则表达式,也就相当于使用egrep。 或操作
-F : 解释PATTERN作为固定字符串的列表,由换行符分隔,其中任何一个都要匹配。也就相当于使用fgrep。
-G: 将范本样式视为普通的表示法来使用。这是默认值。加不加都是使用grep。
匹配控制选项:
-e : 使用PATTERN作为模式。这可以用于指定多个搜索模式,或保护以连字符( - )开头的图案。指定字符串做为查找文件内容的样式。
-f : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-i : 搜索时候忽略大小写
-v: 反转匹配,选择没有被匹配到的内容。
-w:匹配整词,精确地单词,单词的两边必须是非字符符号(即不能是字母数字或下划线)
-x:仅选择与整行完全匹配的匹配项。精确匹配整行内容(包括行首行尾那些看不到的空格内容都要完全匹配)
-y:此参数的效果和指定“-i”参数相同。
一般输出控制选项:
-c: 抑制正常输出;而是为每个输入文件打印匹配线的计数。
--color [= WHEN]:让关键字高亮显示,如--color=auto
-L:列出文件内容不符合指定的范本样式的文件名称
-l : 列出文件内容符合指定的范本样式的文件名称。
-m num:当匹配内容的行数达到num行后,grep停止搜索,并输出停止前搜索到的匹配内容
-o: 只输出匹配的具体字符串,匹配行中其他内容不会输出
-q:安静模式,不会有任何输出内容,查找到匹配内容会返回0,未查找到匹配内容就返回非0
-s:不会输出查找过程中出现的任何错误消息,-q和-s选项因为与其他系统的grep有兼容问题,shell脚本应该避免使用-q和-s,并且应该将标准和错误输出重定向到/dev/null 代替。
输出线前缀控制:
-b:输出每一个匹配行(或匹配的字符串)时在其前附加上偏移量(从文件第一个字符到该匹配内容之间的字节数)
-H:在每一个匹配行之前加上文件名一起输出(针对于查找单个文件),当查找多个文件时默认就会输出文件名
-h:禁止输出上的文件名的前缀。无论查找几个文件都不会在匹配内容前输出文件名
--label = LABEL:显示实际来自标准输入的输入作为来自文件LABEL的输入。这是特别在实现zgrep等工具时非常有用,例如gzip -cd foo.gz | grep --label = foo -H的东西。看到 也是-H选项。
-n:输出匹配内容的同时输出其所在行号。
-T:初始标签确保实际行内容的第一个字符位于制表位上,以便对齐标签看起来很正常。在匹配信息和其前的附加信息之间加入tab以使格式整齐。
上下文线控制选项:
-A num:匹配到搜索到的行以及该行下面的num行
-B num:匹配到搜索到的行以及该行上面的num行
-C num:匹配到搜索到的行以及上下各num行
文件和目录选择选项:
-a: 处理二进制文件,就像它是文本;这相当于--binary-files = text选项。不忽略二进制的数据。
--binary-files = TYPE:如果文件的前几个字节指示文件包含二进制数据,则假定该文件为类型TYPE。默认情况下,TYPE是二进制的,grep通常输出一行消息二进制文件匹配,或者如果没有匹配则没有消息。如果TYPE不匹配,grep假定二进制文件不匹配;这相当于-I选项。如果TYPE是文本,则grep处理a二进制文件,如果它是文本;这相当于-a选项。警告:grep --binary-files = text可能会输出二进制的垃圾,如果输出是一个终端和如果可能有讨厌的副作用终端驱动程序将其中的一些解释为命令。
-D:如果输入文件是设备,FIFO或套接字,请使用ACTION处理。默认情况下,读取ACTION,这意味着设备被读取,就像它们是普通文件一样。如果跳过ACTION,设备为 默默地跳过。
-d: 如果输入文件是目录,请使用ACTION处理它。默认情况下,ACTION是读的,这意味着目录被读取,就像它们是普通文件一样。如果跳过ACTION,目录将静默跳过。如果ACTION是recurse,grep将递归读取每个目录下的所有文件;这是相当于-r选项。
--exclude=GLOB:跳过基本名称与GLOB匹配的文件(使用通配符匹配)。文件名glob可以使用*,?和[...]作为通配符,和\引用通配符或反斜杠字符。搜索其文件名和GLOB通配符相匹配的文件的内容来查找匹配使用方法:grep -H --exclude=c* "old" ./* c*是通配文件名的通配符./* 指定需要先通配文件名的文件的范围,必须要给*,不然就匹配不出内容,(如果不给*,带上-r选项也可以匹配)
--exclude-from = FILE:在文件中编写通配方案,grep将不会到匹配方案中文件名的文件去查找匹配内容
--exclude-dir = DIR:匹配一个目录下的很多内容同时还要让一些子目录不接受匹配,就使用此选项。
--include = GLOB:仅搜索其基本名称与GLOB匹配的文件(使用--exclude下所述的通配符匹配)。
-R ,-r :以递归方式读取每个目录下的所有文件; 这相当于-d recurse选项。
其他选项:
--line-buffered: 在输出上使用行缓冲。这可能会导致性能损失。
--mmap:启用mmap系统调用代替read系统调用
-U:将文件视为二进制。
-z:将输入视为一组行,每一行由一个零字节(ASCII NUL字符)而不是a终止新队。与-Z或--null选项一样,此选项可以与排序-z等命令一起使用来处理任意文件名。
简述
-a --text #不要忽略二进制的数据。 将 binary 文件以 text 文件的方式搜寻数据
-A<显示行数> --after-context=<显示行数> #除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b --byte-offset #在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> --before-context=<显示行数> #除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count #计算符合样式的行数。
-C<显示行数> --context=<显示行数>或-<显示行数> #除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> --directories=<动作> #当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> #指定字符串做为查找文件内容的样式。
-E --extended-regexp #将样式为延伸的普通表示法来使用。
-f<规则文件> --file=<规则文件> #指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F --fixed-regexp #将样式视为固定字符串的列表。
-G --basic-regexp #将样式视为普通的表示法来使用。
-h --no-filename #在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H --with-filename #在显示符合样式的那一行之前,表示该行所属的文件名称。
-i --ignore-case #忽略字符大小写的差别。
-l --file-with-matches #列出文件内容符合指定的样式的文件名称。
-L --files-without-match #列出文件内容不符合指定的样式的文件名称。
-n --line-number #在显示符合样式的那一行之前,标示出该行的列数编号。
-q --quiet或--silent #不显示任何信息。
-r --recursive #此参数的效果和指定“-d recurse”参数相同。
-s --no-messages #不显示错误信息。
-v --revert-match #显示不包含匹配文本的所有行。
-V --version #显示版本信息。
-w --word-regexp #只显示全字符合的列。
-x --line-regexp #只显示全列符合的列。
-y #此参数的效果和指定“-i”参数相同。
--color=auto :可以将找到的关键词部分加上颜色的显示
使用实例:
一、常用用法
grep -i pattern files :不区分大小写地搜索。默认情况区分大小写,
grep -l pattern files :只列出匹配的文件名,
grep -L pattern files :列出不匹配的文件名,
grep -w pattern files :只匹配整个单词,而不是字符串的一部分(如匹配‘magic’,而不是‘magical’),
grep -C number pattern files :匹配的上下文分别显示[number]行,
grep pattern1 | pattern2 files :显示匹配 pattern1 或 pattern2 的行,
grep pattern1 files | grep pattern2 :显示既匹配 pattern1 又匹配 pattern2 的行。
这里还有些用于搜索的特殊符号:
< 和 > 分别标注单词的开始与结尾。
例如:
grep man * 会匹配 ‘Batman’、‘manic’、‘man’等,
grep \'<man\' * 匹配‘manic’和‘man’,但不是‘Batman’,
grep \'<man>\' 只匹配‘man’,而不是‘Batman’或‘manic’等其他的字符串。
\'^\':指匹配的字符串在行首,
\'$\':指匹配的字符串在行尾,
如果您不习惯命令行参数,可以试试图形界面的‘grep’,如 reXgrep 。这个软件提供 AND、OR、NOT 等语法,还有漂亮的按钮 :-) 。如果您只是需要更清楚的输出,不妨试试 fungrep 。
.grep 搜索字符串
命令格式:
grep string filename
寻找字串的方法很多,比如说我想找所有以M开头的行.此时必须引进pattern的观
念.以下是一些简单的□例,以及说明:
^M 以M开头的行,^表示开始的意思
M$ 以M结尾的行,$表示结束的意思
^[0-9] 以数字开始的行,[]内可列举字母
^[124ab] 以1,2,4,a,或b开头的行
^b.503 句点表示任一字母
* 星号表示0个以上的字母(可以没有)
+ 加号表示1个以上的字母
. 斜线可以去掉特殊意义
<eg> cat passwd | grep ^b 列出大学部有申请帐号者名单
cat passwd | grep ^s 列出交换学生申请帐号者名单
cat passwd | grep \'^b.503\' 列出电机系各年级...
grep \'^.\' myfile.txt 列出所有以句点开头的行
1、查找指定进程
命令:ps -ef|grep java
2、查找指定进程个数
命令:ps -ef|grep -c java
或ps -ef|grep java -c
3、从文件中读取关键词进行搜索,默认是显示的是行
命令1:cat test.txt | grep -f test2.txt
命令2(显示行号):cat test.txt | grep -nf test2.txt
作用:输出test.txt文件中含有从test2.txt文件中读取出的关键词的内容行,可用于按指定关键词(放到一个文件中)搜索日志文件。
另一种用法:将多个文件之间相同的行输出来
# cd /etc/sysconfig/network-scripts/
# grep "IPADDR" ifcfg-eth0 ifcfg-lo #默认不加参数指定过滤关键字,外加多个文件,只是将多个文件里面有匹配的行输出
ifcfg-eth0:IPADDR=192.168.1.108
ifcfg-lo:IPADDR=127.0.0.1
# grep -f ifcfg-eth0 ifcfg-lo #grep -f 文件1 文件2 ,会将多个文件之间相同的行输出出来
ONBOOT=yes
-o:只显示被模式匹配到的字符串,而不是整个行
命令:grep -o "you" ab.log
# grep "root" /etc/passwd #先看下正常的过滤,会将整个一行过滤出来
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
# grep -o "root" /etc/passwd #加o之后的操作,只过滤关键字出来
root
root
root
root
# grep -o "root:.*0" /etc/passwd #加上正则表达式,这样才是正确的用法,不用输出一整行,只是输出一小段
root:x:0:0
# grep -o "root" -b /etc/passwd
-b和-o一般是配合使用的,一行中字符串的字符是从该行的第一个字符开始计算,起始值为0。这里左边的数字就是此关键字在此文件中的起始位置,第一个root出现在0位置,然后字符字母有一个算一个,你就一个个的向右数吧,下一个root出现在11位置以此类推。
0:root
11:root
17:root
414:root
4、从文件中查找关键词,忽略大小写,默认情况区分大小写
命令1:grep 'linux' test.txt
命令2(从多个文件中查找):grep 'linux' test.txt test2.txt
多文件时,输出查询到的信息内容行时,会把文件的命名在行最前面输出并且加上":"作为标示符
命令3(忽略大小写):grep -i 'linux' test.txt
命令:find . -name ".log" | grep -i error | grep -vi "info"
1)使用find -name 来列出所有log文件,重定向给grep
2)使用grep -i 来查找包含error的行
3)使用grep -vi 来查找不包含info的行
5、grep不显示本身
命令:
ps aux|grep \[s]sh
ps aux | grep ssh | grep -v "grep" #不包含grep ssh这条命令
grep -v root /etc/passwd | grep -v nologin #将/etc/passwd,将没有出现 root 和nologin的行取出来
6、-r 递归查找子目录
查找当前目录及其子目录下面包含匹配字符的文件
# grep ‘ab’ * #在当前目录搜索带'ab'行的文件
# grep -r ‘ab’ * #在当前目录及其子目录下搜索'ab'行的文件
# grep -l -r ‘ab’ * #在当前目录及其子目录下搜索'ab'行的文件,但是不显示匹配的行,只显示匹配的文件
# grep -nr BLOG* . # 查找子目录,匹配后输出行号,这里的点表示当前目录
# grep -lr BLOG* . #查找子目录,匹配后只输出文件名
查询不包含某个目录
#grep -R --exclude-dir=node_modules 'some pattern' /path/to/search #不包含txt目录
7、列出关键字所在行的前几行与后几行也一起显示
-A -B -C
很多时候,我们并关心匹配行而是关心匹配行的上下文。这时候-A -B -C就有用了
-A n 后n行,A记忆为(After)
-B n 前n行,B记忆为(Before)
-C n 前n行,后n行,C记忆为(Center)
[root@www ~]# dmesg | grep -n -A3 -B2 --color=auto 'eth'
245-PCI: setting IRQ 10 as level-triggered
246-ACPI: PCI Interrupt 0000:00:0e.0[A] -> Link [LNKB] ...
247:eth0: RealTek RTL8139 at 0xee846000, 00:90:cc:a6:34:84, IRQ 10
248:eth0: Identified 8139 chip type 'RTL-8139C'
249-input: PC Speaker as /class/input/input2
250-ACPI: PCI Interrupt 0000:00:01.4[B] -> Link [LNKB] ...
251-hdb: ATAPI 48X DVD-ROM DVD-R-RAM CD-R/RW drive, 2048kB Cache, UDMA(66)
# 如上所示,你会发现关键字 247 所在的前两行及 248 后三行也都被显示出来!
8、--line-buffered 打开buffering 模式
有一个文件是动态的,它不断地添加信息到文件的尾部,而你想要输出包含某些信息的行。即持续的grep一个动态的流
9、e与E区别
grep想同时过滤多个条件或操作
错误写法:
# netstat -an|grep "ESTABLISHED|WAIT" #默认grep不支持多条件匹配
正确写法:
# netstat -an|grep -E "ESTABLISHED|WAIT" #加上-E 多条件用""包起来,然后多条件之间用|管道符分开
tcp 0 52 192.168.1.108:22 192.168.1.104:54127 ESTABLISHED
# ps -aux|grep -e udevd -e master|awk {'print $(NF-1)'}|sort|uniq #而-e呢不用""包起来,-e 指定一个匹配条件
/sbin/udevd
/usr/bin/salt-master
grep -E '123|abc' filename // 找出文件(filename)中包含123或者包含abc的行
egrep '123|abc' filename // 用egrep同样可以实现
awk '/123|abc/' filename // awk 的实现方式
与操作
grep pattern1 files | grep pattern2 :显示既匹配 pattern1 又匹配 pattern2 的行。
10、-c 统计行数
# grep -i "abc" test.txt|wc -l #不分大小写。test.txt里面包含abc过滤条件的为2行
2
# grep -yc "abc" test.txt #-c呢,就是不显示行的内容,直接显示有几行
2
# cat /etc/passwd|wc -l
55
# grep -c "^.*$" /etc/passwd #那么我们除了wc -l用来统一一个文件有多少行以外,又多了一种统计文件多少行的方法
55
11、 -m的使用
# cat test2.txt #这是测试文件
abc 1
abc 2
abc 3
abc 4
abc 5
# grep -m 3 "abc" test2.txt #只匹配到了第三行就退出了
abc 1
abc 2
abc 3
二、与正则表达式结合
grep的规则表达式:
\ 反义字符:如"\"\""表示匹配""
[ - ] 匹配一个范围,[0-9a-zA-Z]匹配所有数字和字母
* 所有字符,长度可为0
+ 前面的字符出现了一次或者多次
^ #匹配行的开始 如:'^grep'匹配所有以grep开头的行。
$ #匹配行的结束 如:'grep$'匹配所有以grep结尾的行。
. #匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* #匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表任意字符。
[] #匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) #标记匹配字符,如'\(love\)',love被标记为1。
\< #到匹配正则表达式的行开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> #到匹配正则表达式的行结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} #重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} #重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b #单词锁定符,如: '\bgrep\b'只匹配grep。
POSIX字符:
为了在不同国家的字符编码中保持一至,POSIX(The Portable Operating System Interface)增加了特殊的字符类,如[:alnum:]是[A-Za-z0-9]的另一个写法。要把它们放到[]号内才能成为正则表达式,如[A- Za-z0-9]或[[:alnum:]]。在linux下的grep除fgrep外,都支持POSIX的字符类。
[:alnum:] #文字数字字符
[:alpha:] #文字字符
[:digit:] #数字字符
[:graph:] #非空字符(非空格、控制字符)
[:lower:] #小写字符
[:cntrl:] #控制字符
[:print:] #非空字符(包括空格)
[:punct:] #标点符号
[:space:] #所有空白字符(新行,空格,制表符)
[:upper:] #大写字符
[:xdigit:] #十六进制数字(0-9,a-f,A-F)
例:通过管道过滤ls -l输出的内容,只显示以a开头的行。
首与行尾字节 ^ $,^ 符号,在字符类符号(括号[])之内与之外是不同的! 在 [] 内代表『反向选择』,在 [] 之外则代表定位在行首的意义!
$ ls -l | grep \'^a\'
$ ls -l | grep ^a
$ ls -l | grep ^[^a] #输出非a开头的行,反向选择
$ grep -n '^$' express.txt #找出空白行,因为只有行首跟行尾 (^$)
例:显示所有以d开头的文件中包含test的行。
$ grep \'test\' d*
例:输出以hat结尾的行内容
$ cat test.txt |grep hat$
例:显示在aa,bb,cc文件中匹配test的行。
$ grep \'test\' aa bb cc
例:显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
在一组集合字节中,如果该字节组是连续的,例如大写英文/小写英文/数字等等,就可以使用[a-z],[A-Z],[0-9]等方式来书写,那么如果我们的要求字串是数字与英文呢?就将他全部写在一起,变成:[a-zA-Z0-9]。
$ grep \'[a-z]{5}\' aa
$ grep -n '[0-9]' regular_express.txt #取得有数字的那一行
$ grep -n '^[a-z]' regular_express.txt #只输出开头是小写字母的那一行
$ grep -n '^[^a-zA-Z]' regular_express.txt #不输出开头是英文的
$ grep -n '\.$' regular_express.txt #只输出行尾结束为小数点 (.) 的那一行
注意:小数点具有其他意义,所以必须要使用转义字符(\)来加以解除其特殊意义!
例:显示包含ed或者at字符的内容行
命令:cat test.txt |grep -E "ed|at"
例:如果west被匹配,则es就被存储到内存中,并标记为1,然后搜索任意个字符(.*),这些字符后面紧跟着另外一个es(1),找到就显示该行。如果用egrep或grep -E,就不用""号进行转义,直接写成\'w(es)t.*1\'就可以了。
$ grep \'w(es)t.*1\' aa
例:显示当前目录下面以.txt 结尾的文件中的所有包含每个字符串至少有7个连续小写字符的字符串的行
命令:grep '[a-z]\{7\}' *.txt
例:查询IP地址、邮箱、手机号
这里用到了-o和-P命令
man grep查看
-o, --only-matching:
Show only the part of a matching line that matches PATTERN.
-P, --perl-regexp:
Interpret PATTERN as a Perl regular expression.
也就是说-o,只显示匹配行中匹配正则表达式的那部分,-P,作为Perl正则匹配
192.168.0.1
abc@163.com
匹配ABC类IP地址即 1.0.0.1---223.255.255.254
命令(IP):grep -oP "([0-9]{1,3}\.){3}[0-9]{1,3}" file.txt
或grep -E --color "\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-1][0-9]|22[0-3])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\.([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\.([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])\>" file.txt
邮箱是任意长度数字字母@任意长度数字字母
命令(邮箱):grep -oP "[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+" file.txt
手机号码是1[3|4|5|8]后面接9位数字的
命令(手机号):grep -E "\<1[3|4|5|8][0-9]{9}\>" file.txt
例:任意一个字节 . 与重复字节 *
. (小数点):代表『一定有一个任意字节』的意思;
* (星号):代表『重复前一个字符, 0 到无穷多次』的意思,为组合形态
$ grep -n '[0-9][0-9]*' regular_express.txt #找出『任意数字』的行
$ grep -n 'g.*g' regular_express.txt #找出以g行首与行尾的行,当中的字符可有可无
这个 .* 的 RE 表示任意字符是很常见的.
例:限定连续 RE 字符范围 {}
利用 . 与 RE 字符及 * 来配置 0 个到无限多个重复字节
打算找出两个到五个 o 的连续字串,该如何作?这时候就得要使用到限定范围的字符 {} 了。 但因为 { 与 } 的符号在 shell 是有特殊意义的,因此, 我们必须要使用字符 \ 来让他失去特殊意义才行。
$ grep -n 'o\{2\}' regular_express.txt
$ grep -n 'go\{2,5\}g' regular_express.txt #要找出 g 后面接 2 到 5 个 o ,然后再接一个 g 的字串
$ grep -n 'go\{2,\}g' regular_express.txt #想要的是 2 个 o 以上的 goooo....g 呢?除了可以是 gooo*g
————————————————
版权声明:本文为CSDN博主「llljjlj」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/llljjlj/article/details/89810340
作为linux中最为常用的三大文本(awk,sed,grep)处理工具之一,掌握好其用法是很有必要的。
首先谈一下grep命令的常用格式为:grep [选项] ”模式“ [文件]
grep家族总共有三个:grep,egrep,fgrep。
常用选项:
-E :开启扩展(Extend)的正则表达式。
-i :忽略大小写(ignore case)。
-v :反过来(invert),只打印没有匹配的,而匹配的反而不打印。
-n :显示行号
-w :被匹配的文本只能是单词,而不能是单词中的某一部分,如文本中有liker,而我搜寻的只是like,就可以使用-w选项来避免匹配liker
-c :显示总共有多少行被匹配到了,而不是显示被匹配到的内容,注意如果同时使用-cv选项是显示有多少行没有被匹配到。
-o :只显示被模式匹配到的字符串。
--color :将匹配到的内容以颜色高亮显示。
-A n:显示匹配到的字符串所在的行及其后n行,after
-B n:显示匹配到的字符串所在的行及其前n行,before
-C n:显示匹配到的字符串所在的行及其前后各n行,context


模式部分:
1、直接输入要匹配的字符串,这个可以用fgrep(fast grep)代替来提高查找速度,比如我要匹配一下hello.c文件中printf的个数:fgrep -c "printf" hello.c
2、使用基本正则表达式,下面谈关于基本正则表达式的使用:
匹配字符:
. :任意一个字符。
[abc] :表示匹配一个字符,这个字符必须是abc中的一个。
[a-zA-Z] :表示匹配一个字符,这个字符必须是a-z或A-Z这52个字母中的一个。
[^123] :匹配一个字符,这个字符是除了1、2、3以外的所有字符。
对于一些常用的字符集,系统做了定义:
[A-Za-z] 等价于 [[:alpha:]]
[0-9] 等价于 [[:digit:]]
[A-Za-z0-9] 等价于 [[:alnum:]]
tab,space 等空白字符 [[:space:]]
[A-Z] 等价于 [[:upper:]]
[a-z] 等价于 [[:lower:]]
标点符号 [[:punct:]]

匹配次数:
\{m,n\} :匹配其前面出现的字符至少m次,至多n次。
\? :匹配其前面出现的内容0次或1次,等价于\{0,1\}。
* :匹配其前面出现的内容任意次,等价于\{0,\},所以 ".*" 表述任意字符任意次,即无论什么内容全部匹配。

位置锚定:
^ :锚定行首
$ :锚定行尾。技巧:"^$"用于匹配空白行。
\b或\<:锚定单词的词首。如"\blike"不会匹配alike,但是会匹配liker
\b或\>:锚定单词的词尾。如"\blike\b"不会匹配alike和liker,只会匹配like
\B :与\b作用相反。


分组及引用:
\(string\) :将string作为一个整体方便后面引用
\1 :引用第1个左括号及其对应的右括号所匹配的内容。
\2 :引用第2个左括号及其对应的右括号所匹配的内容。
\n :引用第n个左括号及其对应的右括号所匹配的内容。

3、扩展的(Extend)正则表达式(注意要使用扩展的正则表达式要加-E选项,或者直接使用egrep):
匹配字符:这部分和基本正则表达式一样
匹配次数:
* :和基本正则表达式一样
? :基本正则表达式是\?,二这里没有\。
{m,n} :相比基本正则表达式也是没有了\。
+ :匹配其前面的字符至少一次,相当于{1,}。
位置锚定:和基本正则表达式一样。
分组及引用:
(string) :相比基本正则表达式也是没有了\。
\1 :引用部分和基本正则表达式一样。
\n :引用部分和基本正则表达式一样。
或者:
a|b :匹配a或b,注意a是指 | 的左边的整体,b也同理。比如 C|cat 表示的是 C或cat,而不是Cat或cat,如果要表示Cat或cat,则应该写为 (C|c)at 。记住(string)除了用于引用还用于分组。
注1:默认情况下,正则表达式的匹配工作在贪婪模式下,也就是说它会尽可能长地去匹配,比如某一行有字符串 abacb,如果搜索内容为 "a.*b" 那么会直接匹配 abacb这个串,而不会只匹配ab或acb。
注2:所有的正则字符,如 [ 、* 、( 等,若要搜索 * ,而不是想把 * 解释为重复先前字符任意次,可以使用 \* 来转义。
下面用一个练习来结束本次grep的学习:
在网络配置文件 /etc/sysconfig/network-scripts/ifcfg-ens33 中检索出所有的 IP
1、检索出 0-255的范围

2、由0-255的数字组合成IP

3、简化

Shell—正则表达式(grep命令、sed工具)
前言
正则表达式对于系统管理员来说是非常重要的,熟练运用正则表达式可使工作变得更加简单、方便。
一、正则表达式概述
正则表达式定义
正则表达式,又称正规表达式、常规表达式
使用字符串来描述、匹配一系列符合某个规则的字符串
简单来说,是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。
正则表达式组成
普通字符:大小写字母、数字、标点符号及一些其他符号
元字符:在正则表达式中具有特殊意义的专用字符
正则表达式的用途
正则表达式对于系统管理员来说是非常重要的,系统运行过程中会产生大量的信息,这些信息有些是非常重要的,有些则仅是告知的信息。身为系统管理员如果直接看这么多的信息数据,无法快速定位到重要的信息,如“用户账号登录失败”“服务启动失败”等信息。这时可以通过正则表达式快速提取“有问题”的信息。如此一来,可以将运维工作变得更加简单、方便。
正则表达式分类
基础正则表达式
扩展正则表达式
Linux中文本处理工具
支持基础正则表达式:grep;sed
支持扩展正则表达式:egrep;awk
基础正则表达式元字符
基础正则表达式是常用的正则表达式部分
除了普通字符外,常见到以下元字符
- ■ \ :转义字符,\!、 \n等 #让特殊意义的元字符作普通字符使用
- ■ ^ :匹配字符串开始的位置
- 例: ^a、 ^the、 ^#
- ■ $ :匹配字符串结束的位置
- 例: word$
- ■ . :匹配除\n之外的任意的一个字符
- 例: go.d、 g..d
- ■ * :匹配前面子表达式0次或者多次
- 例: goo*d、 go.*d
- ■ [list] :匹配list列表中的一个字符
- 例: go[ola]d 、[abc]、 [a-z]、 [a-z0-9]
- ■ [^list] :匹配任意不在list列表中的一个字符
- 例: [^a-z]、 [^0-9]、 [^A-Z0-9]
- ■ \{n,m\} :匹配前面的子表达式n到m次,有\{n\}、 \{n,\}、\{n,m\}三种格式
- 例: go\{2\}d、 go\{2,3\}d、 go\{2,\}d
- 注意:“o{1,}” 等价于 “o+” ;“o{0,}” 则等价于 “o*”
二、grep 命令
2.1 grep的使用规则:
- -n:表示显示行号
- -i :表示不区分大小写
- -v:表示反向过滤
- [ ]:查找集合字符
2.2 用法示例
- grep -n 'the' test.txt #文件检索出带‘the’的行并显示行号
- grep -vn 'the' test.txt #文件反向检索出不带‘the’的行并显示行号
- grep -n 'sh[oi]rt' test.txt #文件检索出带‘short’或‘shirt‘的行并显示行号
- grep -n 'oo' test.txt #文件检索出至少带连续oo的行并显示行号
- grep -n 'o\{2\}' test.txt #文件检索出至少带连续oo的行并显示行号
- grep -n 'o\{2,\}' test.txt #文件检索出至少带连续oo的行并显示行号
- grep -n '[^w]oo' test.txt #文件检索出连续oo前面不带w的行并显示行号
- grep -n '^[^w]oo' test.txt #文件检索出除w外,任意*oo开头的行并显示行号
- grep -n ' [^a-z]oo ' test.txt #文件检索出连续oo前面不是小写字母的行并显示行号
- grep -n '[0-9]' test.txt #文件检索出包含数字的行并显示行号
- grep -n '[^0-9]' test.txt #文件检索出不包含纯数字的行并显示行号,非纯数字也会匹配
- grep -n '[^#]' test.txt #文件检索出不包含#的行并显示行号
- grep -n '^the' test.txt #文件检索出以‘the’开头的行并显示行号
- grep -n ‘^[a-z] ' test.txt #文件检索出以小写字母开头的行并显示行号
- grep -n ‘^[A-Z] ' test.txt #文件检索出以大写字母开头的行并显示行号
- grep -n '^[^a-zA-Z]' test.txt #文件检索出不以字母开头的行并显示行号
- grep -n '\.$' test.txt #文件检索出以 . 号结尾的行并显示行号
- grep -n '^$' test.txt #文件检索出空行并显示行号
- grep -n 'w..d' test.txt #文件检索出带有w开头,d结尾,中间两个任意字符的行并显示行号
- grep -n 'ooo*' test.txt #文件检索出带有连续oo或两个0以上的行并显示行号
- grep -n 'oo*' test.txt #文件检索出带有o或一个0以上的行并显示行号
- grep -n 'w.*d' test.txt #文件检索出带有w开头,d结尾,中间任意字符也可中间什么也没有的行并显示行号
- grep -n '[0-9][0-9]*' test .txt #文件检索出带有数字的行并显示行号
三、sed 工具
sed(StreamEDitor)
一个强大而简单的文本解析转换工具,可以读取文本,并根据指定的条件对文本内容进行编辑(删除、替换、添加、移动等),最后输出所有行或者仅输出处理的某些行。
3.1 sed 工具使用规则
sed的工作流程
主要包括读取、执行和显示三个过程
读取: sed从输入流(文件、管道、标准输入)中读取一-行内容并存储到临时的缓冲区中(又称模式空间,pattern space)
执行: 默认情况下,所有的sed命令都在模式空间中顺序地执行,除非指定了行的地址,否则sed命令将会在所有的行上依次执行。
显示: 发送修改后的内容到输出流。在发送数据后,模式空间将会被清空。在所有的文件内容都被处理完成之前,上述过程将重复执行,直至所有内容被处理完。
注意:默认情况下所有的sed命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,除非是用重定向存储输出。
sed命令常见用法
- sed [选项] ‘操作’ 参数
- sed [选项] -f scriptfile 参数
常见的sed命令选项
- -e script: 指定sed编辑命令
- -f scriptfile: 指定的文件中是sed编辑命令
- -h或–help: 显示帮助
- -n、–quiet或silent:表示仅显示处理后的结果。
- -i: 直接编辑文本文件
常见sed命令的操作
- a: 增加,在当前行下面增加一行指定内容。
- c: 替换,将选定行替换为指定内容。
- d: 删除,删除选定的行。
- i: 插入,在选定行上面插入一行指定内容。
- p: 打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以ASCII码输出。其通常与“-n”选项一起使用。
- s: 替换,替换指定字符。
- y: 字符转换。
- p:n #奇数行
- n:p #偶数行
3.2 用法示例
1、输出符合条件的文本(p表示正常输出)
nl test.txt | sed -n ‘p’ #输出test.txt内容,nl是显示行号和内容,为的是输出结果带上行号
- nl test.txt | sed -n '3p' #输出test.txt内容第三行带行号
- nl test.txt | sed -n '2,5p' #输出test.txt内容二到五行带行号
- nl test.txt | sed -n 'p:n' #输出test.txt内容奇数行带行号,要先删除空格
- nl test.txt | sed -n 'n:p' #输出test.txt内容偶数行带行号,要先删除空格
- nl test.txt | sed -n '1,5{p;n}' #输出test.txt内容奇数行1~5行带行号
- nl test.txt | sed -n '1,10{n;p}' #输出test.txt内容偶数行1~10行带行号
- nl test.txt l sed -n '10,${n; p}' #输出test.txt内容10行到最后一行的偶数行带行号
- sed -n '/the/p' test.txt #输出test.txt带the的内容
- grep -n 'the' test.txt #文件检索出带‘the’的行并显示行号
- nl test.txt | sed -n '4,/the/p' #输出test.txt内容4行以后带‘the’的行带行号
- sed -n '/the/=' test.txt #输出带‘the’的行的行号
- sed -n '/^PI/p' test.txt #查找以‘PI’开头的行输出
- sed -n '/[0-9]$/p' test.txt #查找以数字结尾的行输出
- grep 'wood' test.txt #查找带‘wood’的行输出
- sed -n '/\<wood\>/p' test.txt #输出包含‘wood’的行,\< \>代表单词边界
2、删除符合条件的文本 (d) #只删除输出流,不删除源文件
nl 命令用于计算文件的行数和显示内容
- nl test.txt | sed '3d' #删除文本第三行
- nl test.txt | sed '3,5d' #删除文本第三到第五行
- nl test.txt l sed -n '/cross/p' #查找带‘cross’的行输出带行号
- nl test.txt l sed '/cross/d' #删除带‘cross’的行
- nl test.txt l sed '/cross/!d' #!取反,保留带‘cross’的行
- sed '/^[a-z]/d' test.txt | nl #删除以小写字母开头的行,结果显示行号
- sed '/^[a-z]/d' test.txt #删除以小写字母开头的行
- sed -n '/\.$/d' test.txt #删除以 . 号结尾的行
- sed 'p' test.txt #所有内容输出
- sed '/^$/d' test. txt #删除空行
- sed '/.$/d' test.txt #删除任意字符结尾的行,等于全删
3、替换符合条件的文本
使用 sed 命令进行替换操作时需要用到 s (字符串替换);c (整行/整块替换);y (字符转换) 命令选项
- sed 's/the/THE/' test.txt #将每行中的第一个the替换为THE
- sed 's/1/L/2' test.txt #将每行中的第2个1替换为L
- sed 's/the/THE/g' test.txt #将文件中的所有the替换为THE
- sed 's/o//g' test.txt #将文件中的所有o删除(替换为空串)
- sed 's/^/#' test.txt #在每行行首插入#号
- sed '/the/s/^/#/' test.txt #在包含the 的每行行首插入#号
- sed 's/$/EOF/' test.txt #在每行行尾插入字符串 EOF
- sed '3,5s/the/THE/g' test.txt #将第3~5 行中的所有the替换为 THE
- sed '/the/s/o/0/g'test.txt #将包含the的所有行中的o都替换为O
4、迁移符合条件的文本
在使用sed 命令迁移符合条件的文本时,常用到以下参数:
- H:复制到剪贴板;
- g、G:将剪贴板中的数据覆盖/追加至指定行
- w :保存为文件
- r :读取指定文件
- a:追加指定内容。
- sed '/the/{H; d};$G' test.txt #将包含the 的行迁移至文件末尾,{;}用于多个操作
- sed '1,5 {H; d};17G' test.txt #将第1~5 行内容转移至第17行后
- sed '/the/w out.file' test.txt #将包含the 的行另存为文件 out.file
- sed '/the/r /etc/hostname' test.txt #将文件/etc/hostname 的内容添加到包含 the 的每行以后
- sed '3aNew' test.txt #在第3行后插入一个新行,内容为New
- sed '/the/aNew' test.txt #在包含the的每行后插入一个新行,内容为New
- sed '3aNew1\nNew2' test.txt #在第3行后插入多行内容,中间的\n表示换行
- 注:\n和\r的区别:
- \n:换行符 是另起一新行
- \r :回车符 光标回到一旧行的开头;
5、使用脚本编辑文件
使用sed脚本将多个编辑指令存放到文件中(每行一条编辑指令),通过“-f”选项来调用。
- [root@client2 ~]# vi opt.list #建立一个文件
- 5H #文件内是sed的操作
- 5d
- 16G
- [root@client2 ~]# sed -f opt.list test.txt #对test.txt进行操作
6、sed直接操作文件示例
编写一个脚本,用来调整vsftpd 服务配置,要求禁止匿名用户,但允许本地用户
- [root@server2 ~]# useradd dada
- [root@server2 ~]# passwd dada
- [root@server2 ~]# useradd xiaoxiao
- [root@server2 ~]# passwd xiaoxiao
- [root@server2 ~]# vi ftp.sh
- #!/bin/bash
- A=vsftpd
- FTP=/etc/vsftpd/vsftpd.conf
- yum -y install $A
- sed -i -e '/local_enable/s/NO/YES/g' $FTP
- sed -i -e '/write_enable/s/NO/YES/g' $FTP
- sed -i -e 's/^#chroot_local_user=YES/chroot_local_user=YES/g' $FTP
- sed -i '$aallow_writeable_chroot=YES' $FTP
- sed -i -e '/listen/s/NO/YES/g' $FTP
- sed -i -e '/listen_ipv6/s/YES/NO/g' $FTP
- systemctl start $A
- netstat -anpt | grep $A
- [root@server2 ~]# chmod +x ftp.sh
- [root@server2 ~]# ./ftp.sh
客户机上安装ftp进行访问
- [root@server1 ~]# yum -y install ftp
- [root@server1 ~]# ftp 20.0.0.11
- Name (20.0.0.11:root): dada
- ftp> exit
- [root@server1 ~]# ftp 20.0.0.11
- Name (20.0.0.11:root): xiaoxiao
- ftp> exit
echo -n 和echo -e 参数意义
echo -n 不换行输出
$echo -n "123"
$echo "456"
- 1
- 2
最终输出 123456而不是123456- 1
- 2
- 3
- 4
- 5
- 6
echo -e 处理特殊字符
若字符串中出现以下字符,则特别加以处理,而不会将它当成一般文字输出:
\a 发出警告声;
\b 删除前一个字符;
\c 最后不加上换行符号;
\f 换行但光标仍旧停留在原来的位置;
\n 换行且光标移至行首;
\r 光标移至行首,但不换行;
\t 插入tab;
\v 与\f相同;
\ 插入\字符;
\nnn 插入nnn(八进制)所代表的ASCII字符;
$echo -e "a\bdddd"
dddd- 1
- 2
$echo -e "a\adddd" //输出同时会发出报警声音
adddd- 1
- 2
$echo -e "a\ndddd" //自动换行
adddd朱双引博客















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}