









shared-nothing:
数据以某种方式分区并分布在一组机器上,这意味着每台机器对其拥有的数据具有唯一的访问权限,也是有唯一的责任。因此数据时完全隔离的,每个节点对其特定子集具有完全权限。
shared-disk:
与shared-nothing相比,shared-disk的所有数据都可以冲所有集群节点访问。任何机器都可以读取或写入希望的任何数据部分。
如图:

理解writing的权衡
在shared-disk体系结构中保留数据时,可以对任何节点执行写入操作。如果节点1和节点2都尝试编写元组,那么为了确保与其他节点的一致性,管理系统必须使用基于磁盘的锁,或传达其意图将元组与集群中的其他节点锁定。这两种方法都提供可伸缩行问题。添加更多节点会增加锁定的争用,或者增加必须找到锁定协议的节点数。
进一步解释这一点,如下图:
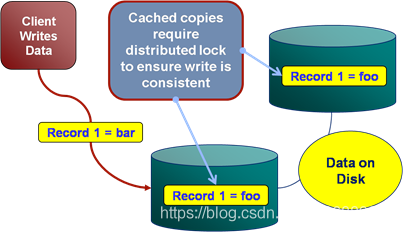
shared-disk集群数据库包含PK=1和data=foo的记录。为了提高效率,两个节点都在内存中缓存了记录1的本地副本。然后客户端尝试更新记录1,以便foo变为bar。为了以一致的方式执行此操作,DBMS必须对可能具有高速缓存记录1的所有节点进行分布式锁定。当增加集群节点数量时,此类分布式锁定会变得越来越慢,因此会阻碍其可扩展性writing过程。
另一种确定锁定在磁盘上的机制很少在实践中完成,因为缓存对性能至关重要。
然而在shared-nothing不受到相同的分布式锁问题,,假设客户端被定向到正确的节点(也就是说客户端写入A,在图1中指示在节点1处写入),则shared-nothing都不会收到相同的分布式锁定问题的影响可以直接流到磁盘,并在内存中指定任何锁定中介。这是因为只有一台机器拥有任何单一数据的所有权,因此根据定义,只需要一个锁。
因此,在不增加锁定数据项的开销的情况下,无需共享就可以冲写入角度进行线性扩展,因为每个节点对其拥有的数据负全部责任。
但是,对于跨多节点上的数据事务性写入(即分布式两阶段提交),shared-nothing仍然必须执行分布式锁定。这些在可伸缩性上并不像上面的shared-disk缓存问题那么大,因为他们只跨越事务中涉及的节点(与跨越所有节点的缓存情况相对应),但他们同事增加了可伸缩性限制(与shared-disk相比,可能非常慢)。
因此,如果可以对数据进行分片并避免跨越不同分片的事务,那么对于需要高吞吐量写入的系统来说,无需共享即可,但是这样做的诀窍时找到正确的分区策略。例如,可以为在线银行系统分区数据,以便用户账户的所有信息都在同一台机器上,如果可以以避免分布式事务的方式对数据集进行分区,那么至少对于基于键的读写来说,线性可伸缩性就唾手可得了。
对于,shared-disk的计数器也可以使用分区。仅仅因为磁盘时共享的,并不意味着不能使用服务于不同分区的不同界定啊对数据进行逻辑分区。假设可以建立自己的体系结构,以便将写请求路由到正确的机器上,因为这总策略将减少正在发生的锁(或block)传递的数量(正式优化oracle rac等数据的方式)。
shared-disk可以实现子啊啊shared-nothing模式下配置。但区别仅在于数据的物理位置。shared-disk始终以某种方式链接到网络,而不是本地连接。因此虽然远程磁盘可以提供相对较高的吞吐量和良好的随机IO性能,通常成本较高。
shared-disk架构时写限制,其中多个写节点必须围绕集群协调他们的锁。
shared-nothing机构时写限制,其中写入跨越多个分区,需要分布式两阶段提交。
数据检索
shared-disk的缺陷:
1、资源匮乏,最明显的时SAN/NAS驱动上的磁盘争用。shared-disk意味着:所有计算机共享相同的磁盘阵列,并在某种程度上共享相同的互连。幸运的是,通过分区可以缓解大型shared-disk系统中的磁盘争用。共享磁盘子系统中的数据通常按其使用模式进行划分(通常将表移动到后备磁盘阵列的不同部分)。
2、缓存效率低的问题。shared-disk系统中的每台计算机都可能涉及整个数据集(因此需要缓存)。这降低了高速缓存的效率,因为高速缓存未命中的可能行更大。而shared-nothing每个机器只需要缓存它自己拥有的数据子集,因此缓存更加有效。
shared-nothing的缺陷:
如果查询是自给自足的,则SN工作得非常好 - 如果每个节点都可以完成处理的“部分”而不需要来自任何其他节点的数据。但是,不可避免地会出现这样的用例,即来自多个节点的数据必须以某种方式组合在一起或以某种方式连接。其含义通常是,可能不包括在最终结果中的数据从一台机器运送到另一台机器。这种在机器之间传输数据以“加入”的需求会对整体查询性能产生重大影响。
所以现实是需要数据传输的查询数量将取决于用例和分区策略。因此,许多无共享解决方案建议使用快速10GE网络。
并发性
许多键值存储使用分片和SN来提供非常高的并发。这是通过将用户请求通过分片键路由到具有所需数据的单台机器上来实现的。结果时存储在大型并发用户群中提供极高水兵的读写吞吐量。这种模式通过NOSQL在大型web应用程序中使用。
必须注意的是:此模式的可伸缩性仅适用于密钥访问。不适用于shared-nothing系统中的一般处理。任何未明确使用主键的请求都必须广播到所有计算机或分区。对不考虑主键的问题的可伸缩性提出了限制。
因此,重要重申:对于基于密钥的访问,shared-nothing只能时线性可扩展的。二级索引的使用总是导致每个节点都被查阅。这限制了可伸缩性,当然旧可以服务的并发请求数而言。这是许多分布式键值存储坚持非常简单的KV存储方式的原因之一。
shared-nothing减少了每台机器存储的数据量,因此总数据量可以更高,或者相反,随着每个查询的平均数据集减少,每个查询将更快。这就是SN为大数据系统(HBase、Map Reduce、cassandra等)所青睐
随着集群的扩展,shared-disk体系结构中的读取可能会遇到资源不足问题和效率较低的缓存。shared-nothing架构更大规模的潜力,但是这可能会收到必须击中所有机器的查询障碍,如果必须跨机器发送非结果数据集,会影响查询速度。
出自:http://www.benstopford.com/2009/11/24/understanding-the-shared-nothing-architecture/














 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









