










毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
1、项目介绍
技术栈:
python语言、Django框架、MySQL数据库、requests爬虫技术、汽车之家二手车
2、项目界面
(1)全国各地车辆数据分析

(2)车辆品牌数据统计
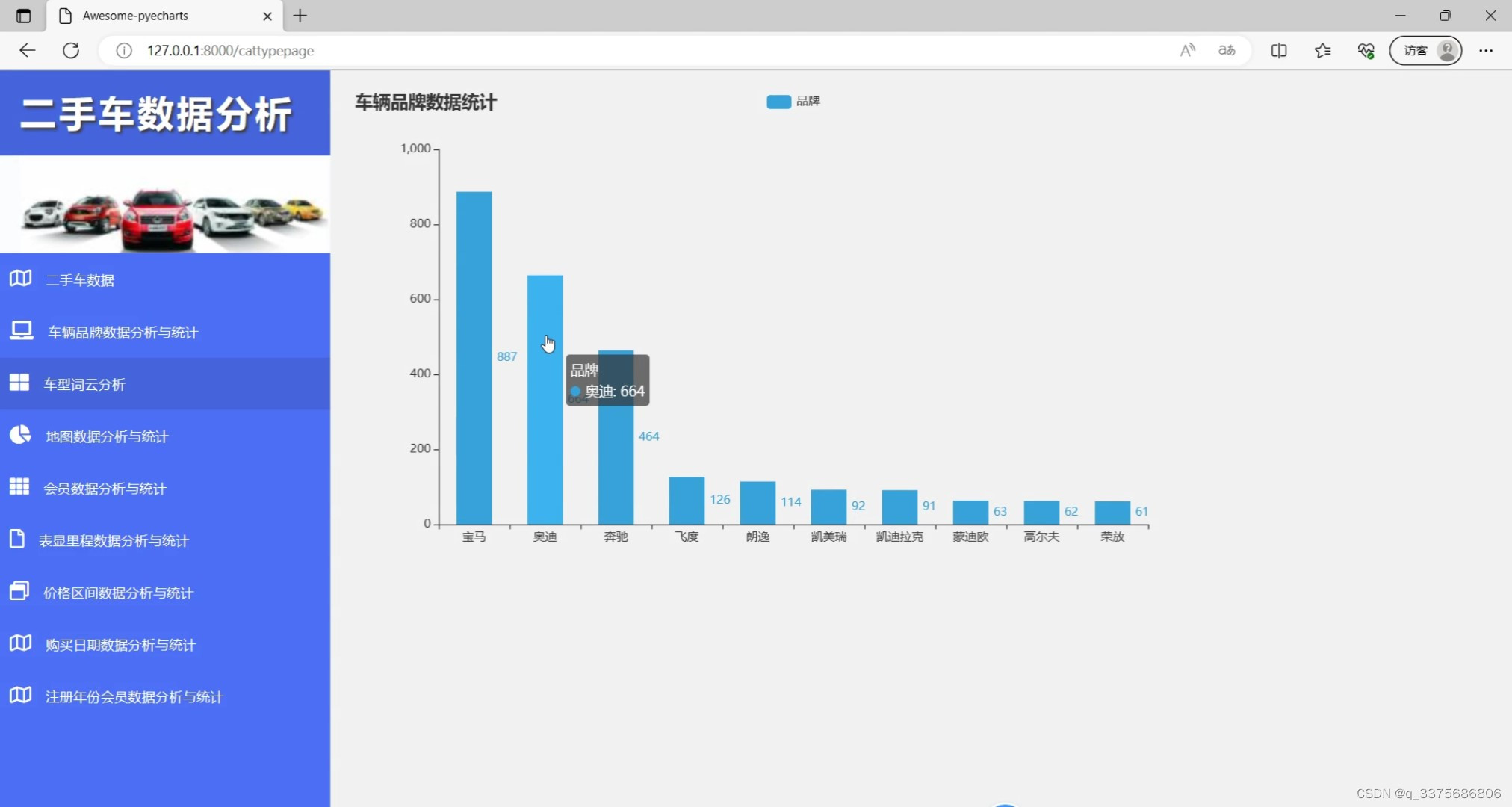
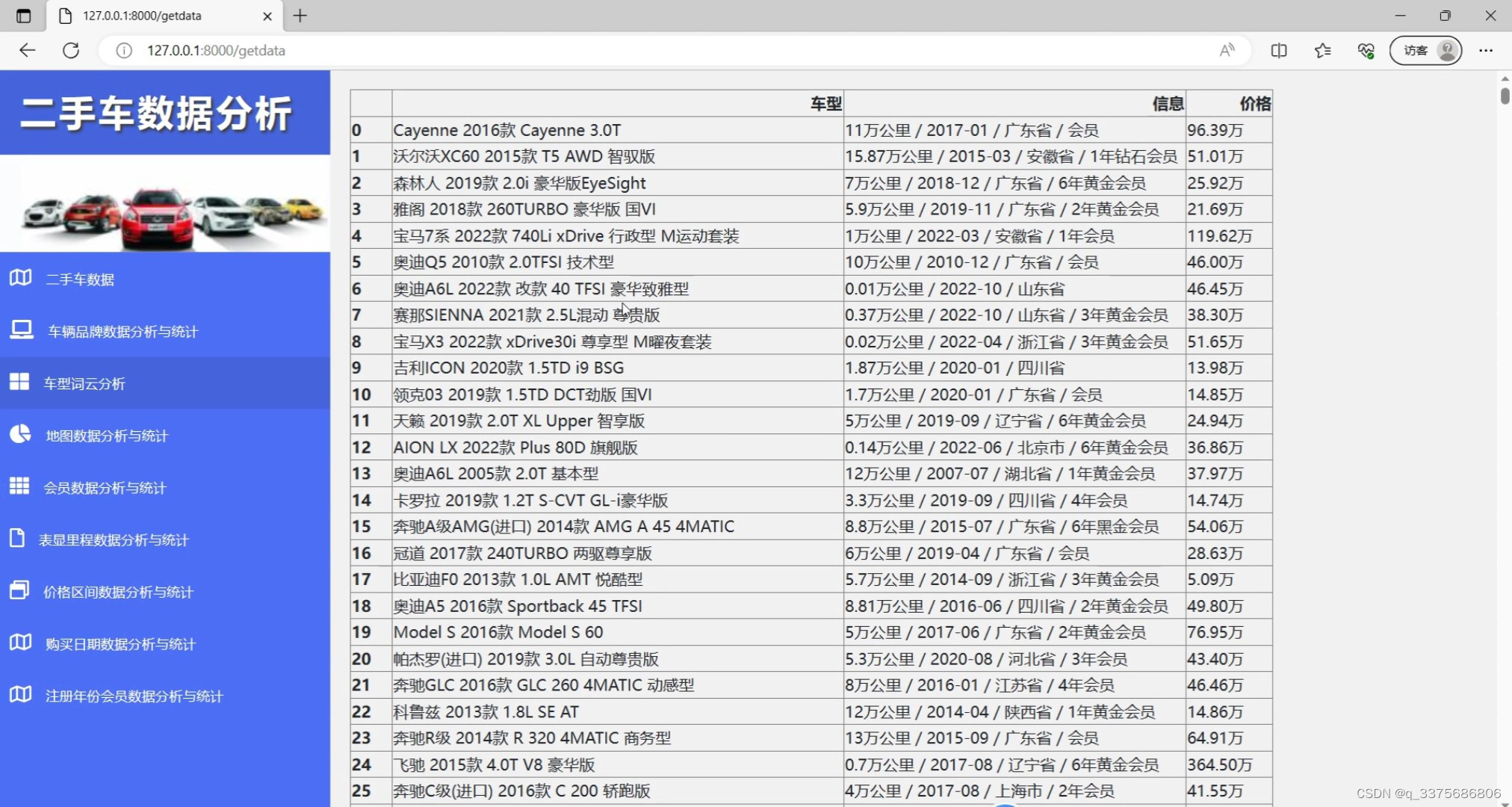
(3)汽车数据
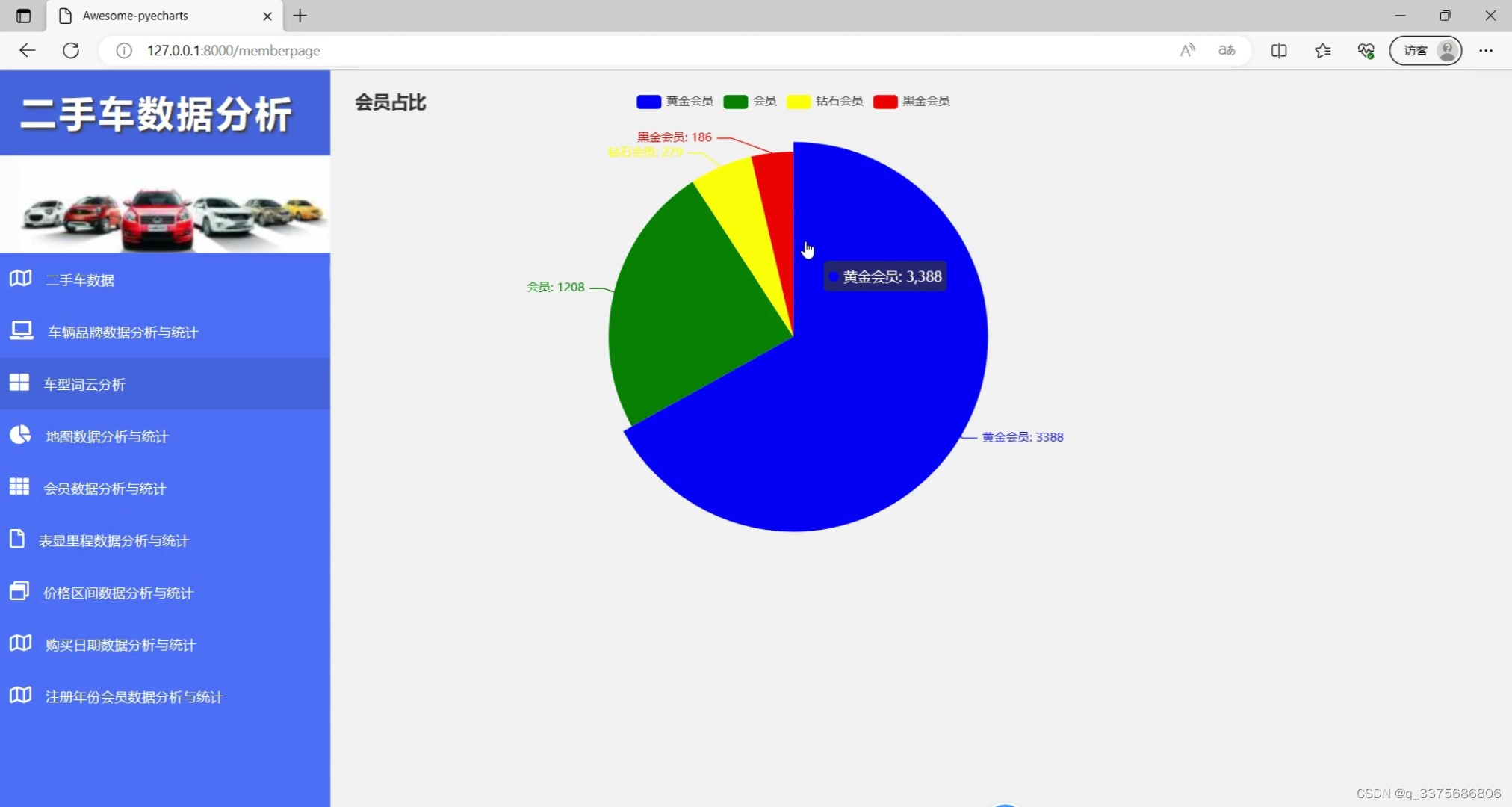
(4)会员占比
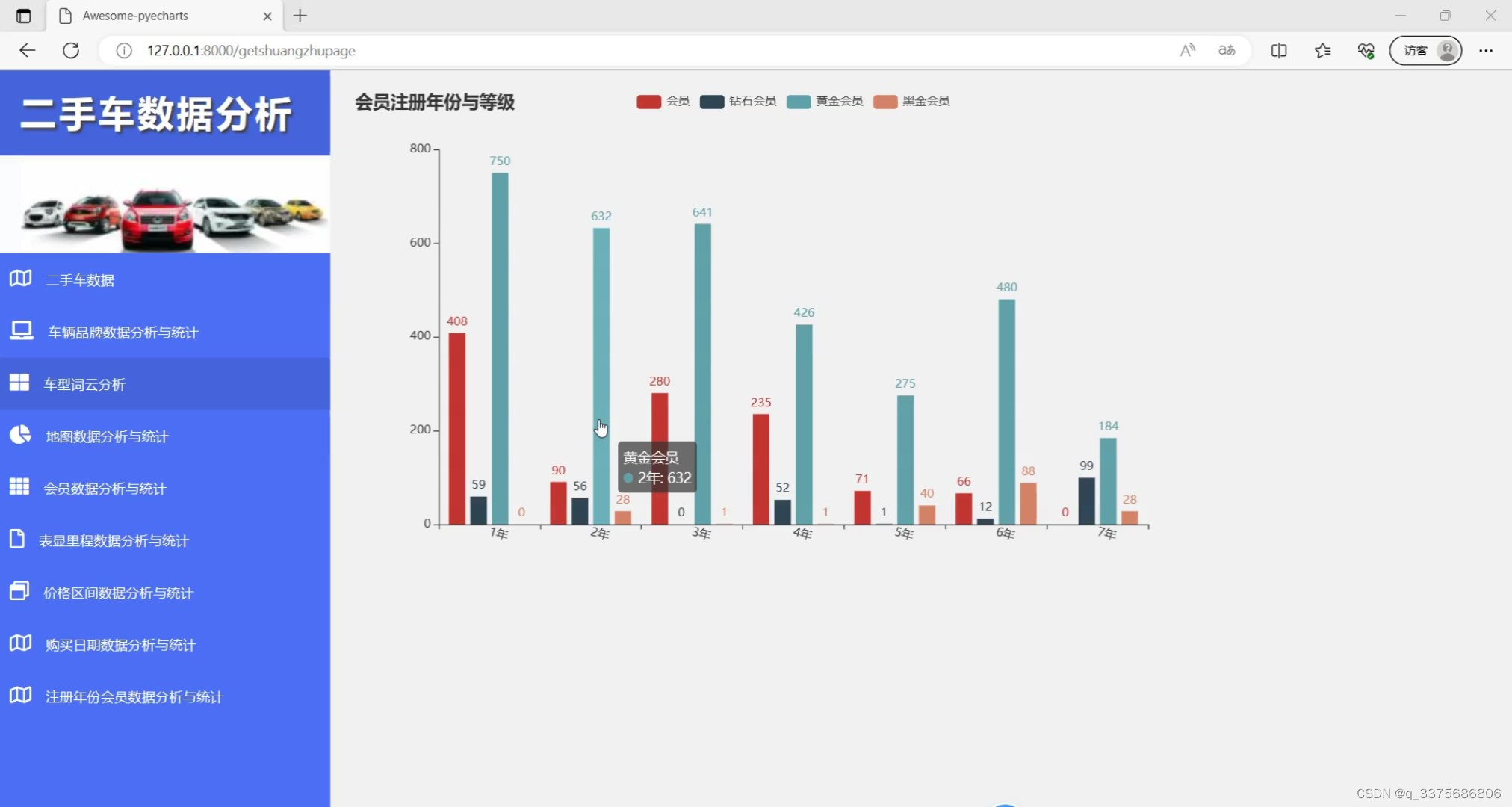
(5)会员注册年份与等级
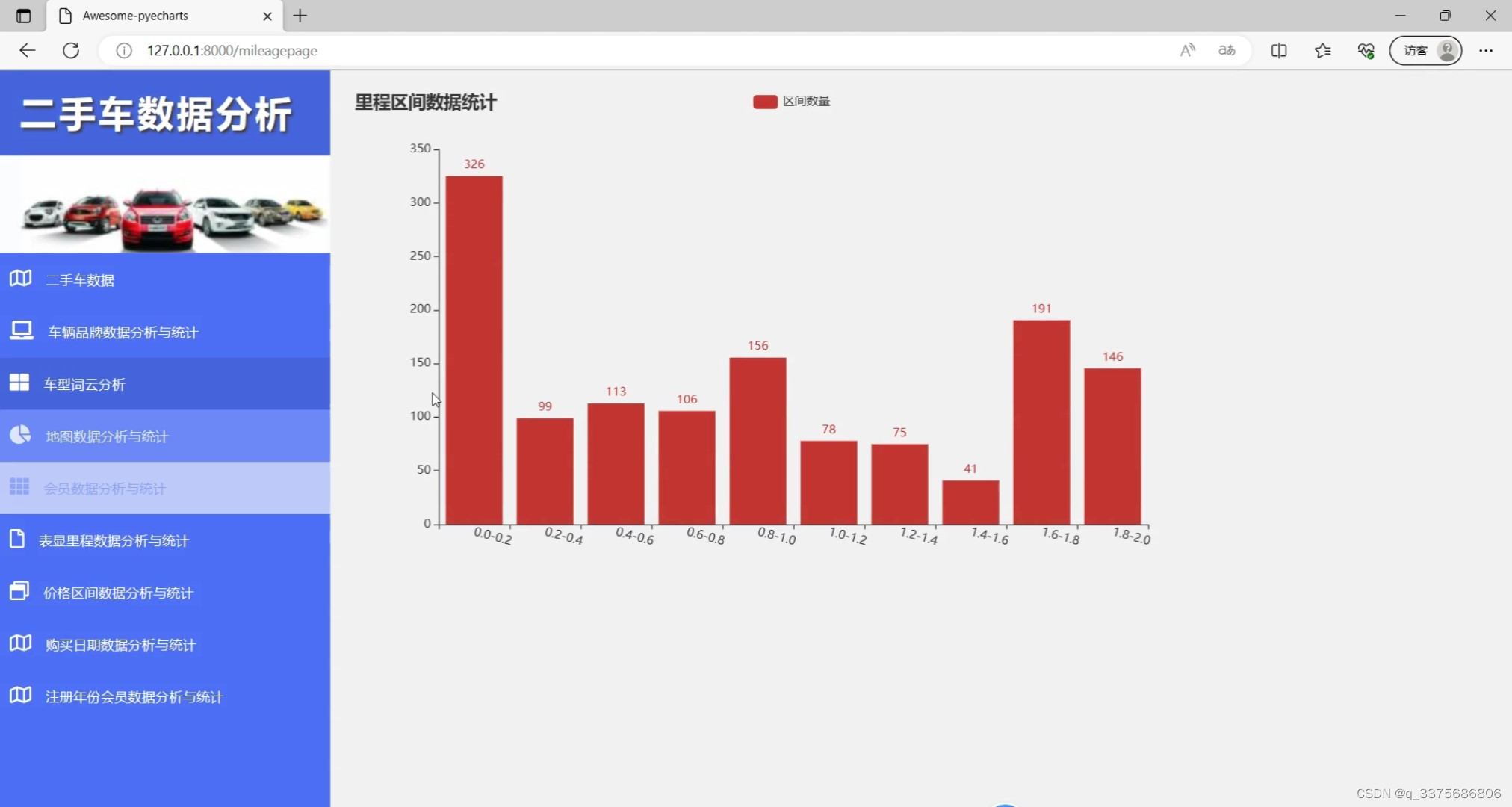
(6)里程区间数据统计
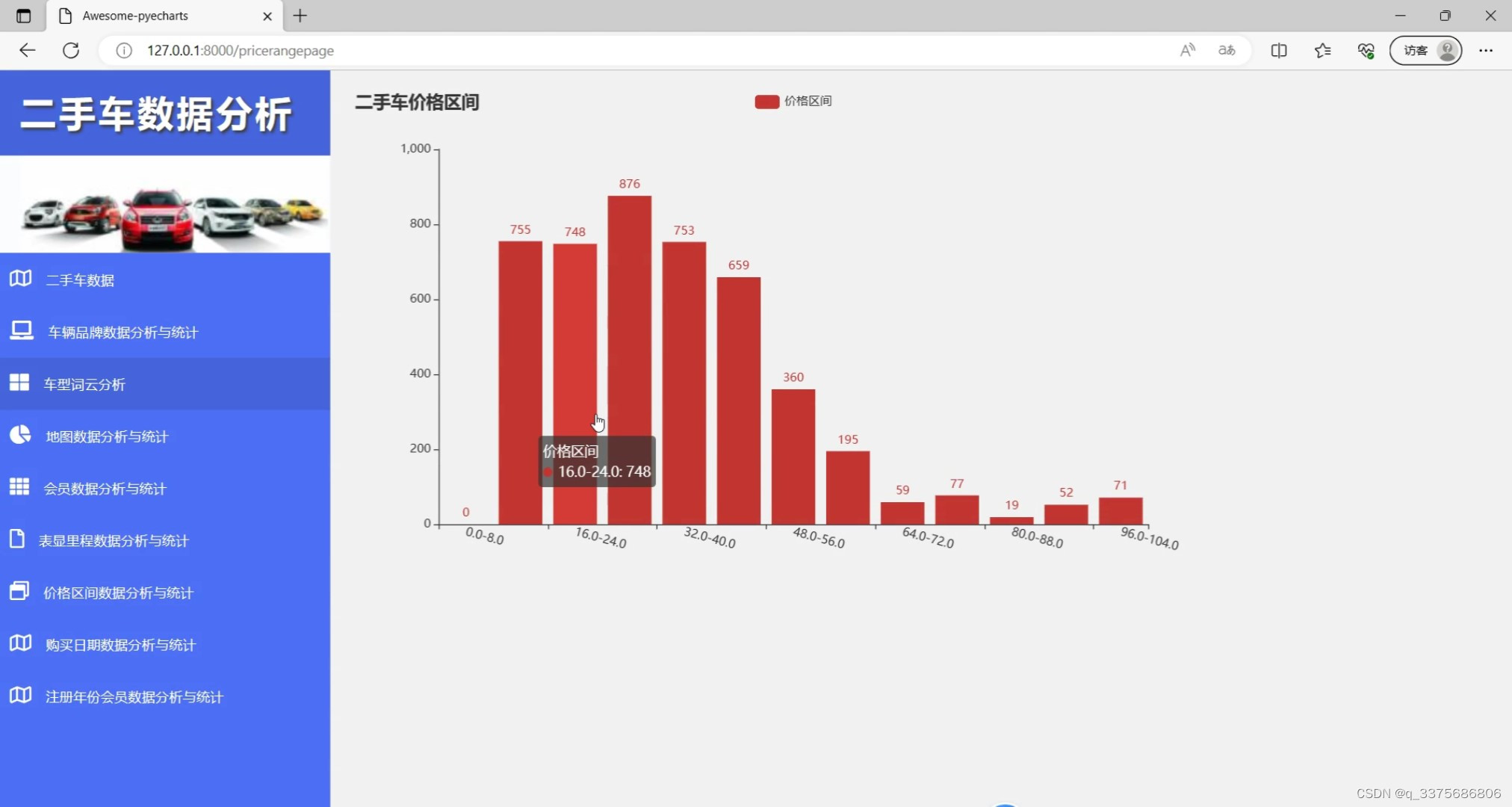
(7)二手车价格区间
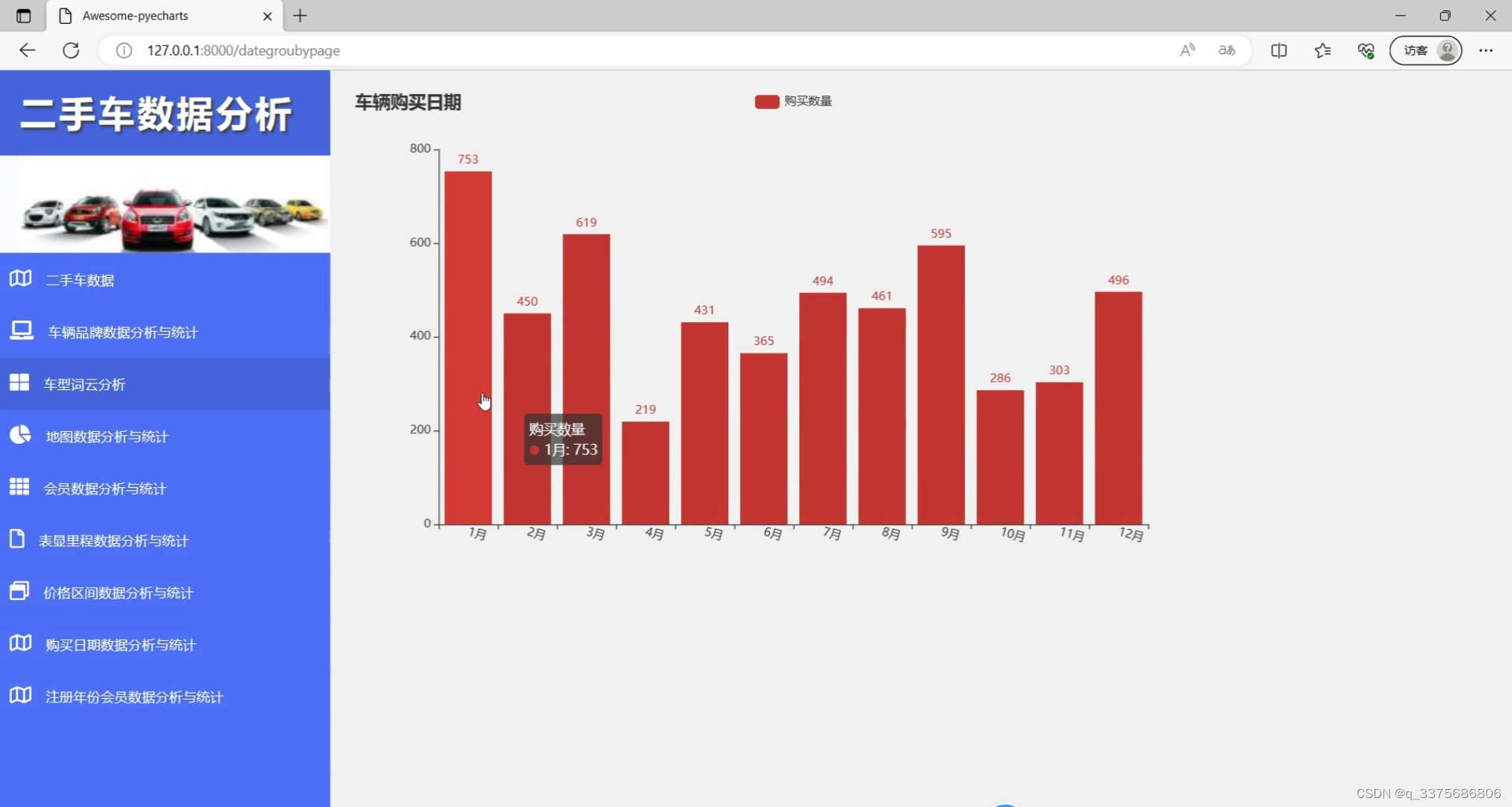
(8)车辆购买日期
(9)数据采集
3、项目说明
我们开发了一个基于Django框架、MySQL数据库、requests爬虫技术的二手车数据采集分析可视化系统,用于从汽车之家网站获取二手车数据并进行分析和可视化展示。
这个系统的主要功能包括:
-
数据采集:使用requests爬虫技术,从汽车之家网站抓取二手车的相关信息,包括车型、价格、里程、上牌时间等。
-
数据存储:将抓取到的二手车数据存储到MySQL数据库中,以便后续的分析和查询。
-
数据分析:基于存储的数据,进行一些统计和分析,如不同车型的平均价格、里程的分布等。
-
数据可视化:将分析结果以图表的形式展示出来,方便用户直观地了解二手车市场的情况。比如,可以通过柱状图展示不同车型的平均价格,通过折线图展示不同里程区间的二手车数量等。
这个系统的优势在于使用了Django框架,可以快速搭建起一个稳定、高效的Web应用。MySQL数据库提供了可靠的数据存储和查询能力,可以处理大量的二手车数据。而使用requests爬虫技术,我们可以定期从汽车之家网站更新数据,保证数据的及时性和完整性。
总之,我们的二手车数据采集分析可视化系统可以帮助用户获取最新的二手车信息,并通过分析和可视化展示帮助用户更好地了解二手车市场。
4、部分代码
import pandas as pd
import matplotlib.pyplot as plt
from io import StringIO
from django.shortcuts import render
from django.http import HttpResponse
import os
from django.views.generic import View
import pandas as pd
import operator
from functools import reduce
from getchart import *
import numpy as np
fileName='data.csv'
def shuju(request):
data = pd.read_csv(r'data.csv')
data = data.dropna()
price = data['价格']
model = data['车型'].reset_index(drop=True)
info = data['信息'].reset_index(drop=True)
data_totle = []
for i in range(len(data)):
data_totle.append({'price': data['价格'].values[i],
'model': data['车型'].values[i],
'info': data['信息'].values[i]}
)
return render(request, 'shuju.html', {'data_totle':data_totle})
def tupian(request):
# 解决中文问题 matplotlib.pypolt不支持中文
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号显示
plt.rcParams['axes.unicode_minus'] = False
print(os.getcwd())
data = pd.read_csv(r'data.csv')
data = data.dropna()
def return_graph(data):
# 清空图像
price = data['价格'].str.extract('(\d+.\d+)',).astype('float').values
a = 0
b = 0
c = 0
d = 0
for ii in price:
if ii >=50:
a += 1
elif 30 <= ii <50:
b += 1
elif 10 <= ii <30:
c += 1
else:
d += 1
data_totle = [a, b, c, d]
model = data['车型'].reset_index(drop=True)
info = data['信息'].reset_index(drop=True)
price_list = []
mode_list = []
for i in range(110, len(data)):
print(price[i][0])
print(model[i])
price_list.append(float(price[i][0]))
mode_list.append(model[i])
print('1112')
print('aaa')
fig = plt.figure()
plt.pie(data_totle, autopct='%1.1f%%', labels=['豪车', '高等车', '中等车', '低价车'])
img_stringio = StringIO()
fig.savefig(img_stringio, format='svg')
img_stringio.seek(0)
data = img_stringio.getvalue()
return data
plt.clf()
plt.title("车辆类型占比")
graph = return_graph(data)
context = {}
context['myechart'] = graph # 这个graph其实是一段包含了html,css的xml格式数据
return render(request, "template.html", context=context)
# def shouye(request):
# return render(request, 'shouye.html', locals())
# 词云页面
def ciyunpage(request):
data=pd.read_csv(fileName)
print(data.columns)
车型=data.车型
# print(type(车型))
车型词云=车型.str.split(' ').tolist()
车型词云=pd.Series(reduce(operator.add, 车型词云)).value_counts().to_dict()
# print([(key,value) for key,value in 车型词云.items()])
ciyundata=[(key,value) for key,value in 车型词云.items()]
myecharts=getciyun(ciyundata).render_embed()
context={
'myechart':myecharts
}
return render(request, "template.html", context=context)
# 车型数据
def cattypepage(request):
data=pd.read_csv(fileName)
车型=data.车型.str.split(' ').apply(lambda x:x[0])
# print(车型)
车型=车型.str.extract('([\u4e00-\u9fa5]+)')
车型.dropna(inplace=True)
车型=车型.value_counts()[:10]
data=[]
for key,value in 车型.items():
data.append(
{"value": value, "percent": key[0]}
)
myecharts=getchex(data).render_embed()
context={
'myechart':myecharts
}
return render(request, "template.html", context=context)
# return HttpResponse('车型数据')
# 地图页面
def mappage(request):
myecharts=getmap(None).render_embed()
context={
'myechart':myecharts
}
return render(request, "template.html", context=context)
# return HttpResponse('地图页面')
# 会员数据
def memberpage(request):
data=pd.read_csv(fileName)
datasplit=data.信息.str.split('/').apply(lambda x:pd.Series(x))
datasplit.columns=['表显里程','上牌时间','车辆所在地','会员']
def isList(x):
if type(x) is list:
return x[-1]
会员=datasplit.会员.str.split('年').apply(isList).value_counts().to_dict()
data=[]
for key,value in 会员.items():
data.append([key,value])
print(data)
myecharts=getmemberpage(data).render_embed()
context={
'myechart':myecharts
}
return render(request, "template.html", context=context)
# return HttpResponse('会员数据')
# 表显里程
def mileagepage(request):
data=pd.read_csv(fileName)
# print(data.columns)
# print(data.信息)
datasplit=data.信息.str.split('/').apply(lambda x:pd.Series(x))
# print(type(datasplit))
datasplit.columns=['表显里程','上牌时间','车辆所在地','会员']
# 获得表显里程 原始数据
表显里程=datasplit.表显里程
# 去除表显里程的单位
表显里程=表显里程.str.replace('万公里','').astype(float)
# bins = [i for i in range(0,100,1)]
setp=0.2
bins =[round(num,1) for num in np.arange(0,50,setp)]
# print(bins)
labels=[f'{round(num,1)}-{round(num+setp,1)}' for num in np.arange(0,50,setp)]
labels.remove(labels[-1])
# print(len(bins))
# print(len(labels))
df=datasplit.groupby(pd.cut(表显里程, bins=bins, labels=labels)).size().reset_index(name='count')[:10]
# print(df)
fw=list(df.to_dict()['表显里程'].values())
# print(len(fw))
count=list(df.to_dict()['count'].values())
# print(len(count))
data={
'fw':fw,
'count':count
}
# getmileage(data)
myecharts=getmileage(data).render_embed()
context={
'myechart':myecharts
}
return render(request, "template.html", context=context)
# return HttpResponse('表显里程')
# 价格区间数据
def pricerangepage(request):
data=pd.read_csv(fileName)
print(data.columns)
data=data[~data.价格.isnull()]
# data.价格=data.价格.replace(to_replace='NoneType', value=np.nan)
# data.价格=data.价格.dropna(inplace=True)
# print('data[data.车型.str.contains("总裁 2014款 3.0T 美规版")].价格.isnull()')
# print(data[data.车型.str.contains("总裁 2014款 3.0T 美规版")].价格.isnull())
价格=data.价格.str.replace('万','').str.strip()
价格=价格[(~价格.str.contains('已降'))&(价格.str.len())].astype(float)
# 价格=价格[(~价格.str.contains('已降'))&(价格.str.len())]
# print(价格)
# 价格分段参数 10 一个区间差
setp=8
# # 最高价
hm=max(价格)
print(f'hm:{hm}')
hm+=setp
bins =[round(num,1) for num in np.arange(0,hm,setp)]
print(bins)
labels=[f'{round(num,1)}-{round(num+setp,1)}' for num in np.arange(0,hm,setp)]
labels.remove(labels[-1])
print(len(bins))
print(len(labels))
print(labels)
df=价格.groupby(pd.cut(价格, bins=bins, labels=labels)).size().reset_index(name='count')
data={
'fw':list(df.to_dict()['价格'].values()),
'count':list(df.to_dict()['count'].values())
}
myecharts=getjiage(data).render_embed()
context={
'myechart':myecharts
}
return render(request, "template.html", context=context)
# return HttpResponse('价格区间数据')
# 原来的饼图
def piechartpage(request):
return HttpResponse('原来的饼图')
# 日期分组
def dategroubypage(request):
data=pd.read_csv(fileName)
# print(data.columns)
datasplit=data.信息.str.split('/').apply(lambda x:pd.Series(x))
# print(type(datasplit))
datasplit.columns=['表显里程','上牌时间','车辆所在地','会员']
上牌时间=datasplit.上牌时间
datedata=[]
for i in 上牌时间:
if '0' in i:
datedata.append(i)
datedata=pd.Series(datedata)
上牌时间=pd.to_datetime(datedata)
上牌时间.index=pd.to_datetime(datedata)
print(上牌时间)
data={
'month':[],
'count':[]
}
for i in 上牌时间.groupby(lambda x:x.month):
data['month'].append(f'{i[0]}月')
data['count'].append(len(i[1]))
print(f'{i[0]}月=={len(i[1])}辆')
myecharts=getdategrouby(data).render_embed()
context={
'myechart':myecharts
}
return render(request, "template.html", context=context)
# return HttpResponse('日期分组')
def getshuangzhupage(request):
data=pd.read_csv(fileName)
myecharts=getshuangzhu(data).render_embed()
context={
'myechart':myecharts
}
return render(request, "template.html", context=context)
def getdata(request):
data=pd.read_csv(fileName)
print(type(data))
data.style.set_properties(**{'text-align':'center'})
context={
'myechart':data.to_html()
}
return render(request, "template.html", context=context)
源码获取:
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

















 1864
1864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









