




博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:
python语言、Django框架、机器学习、线性回归预测算法、Echarts可视化
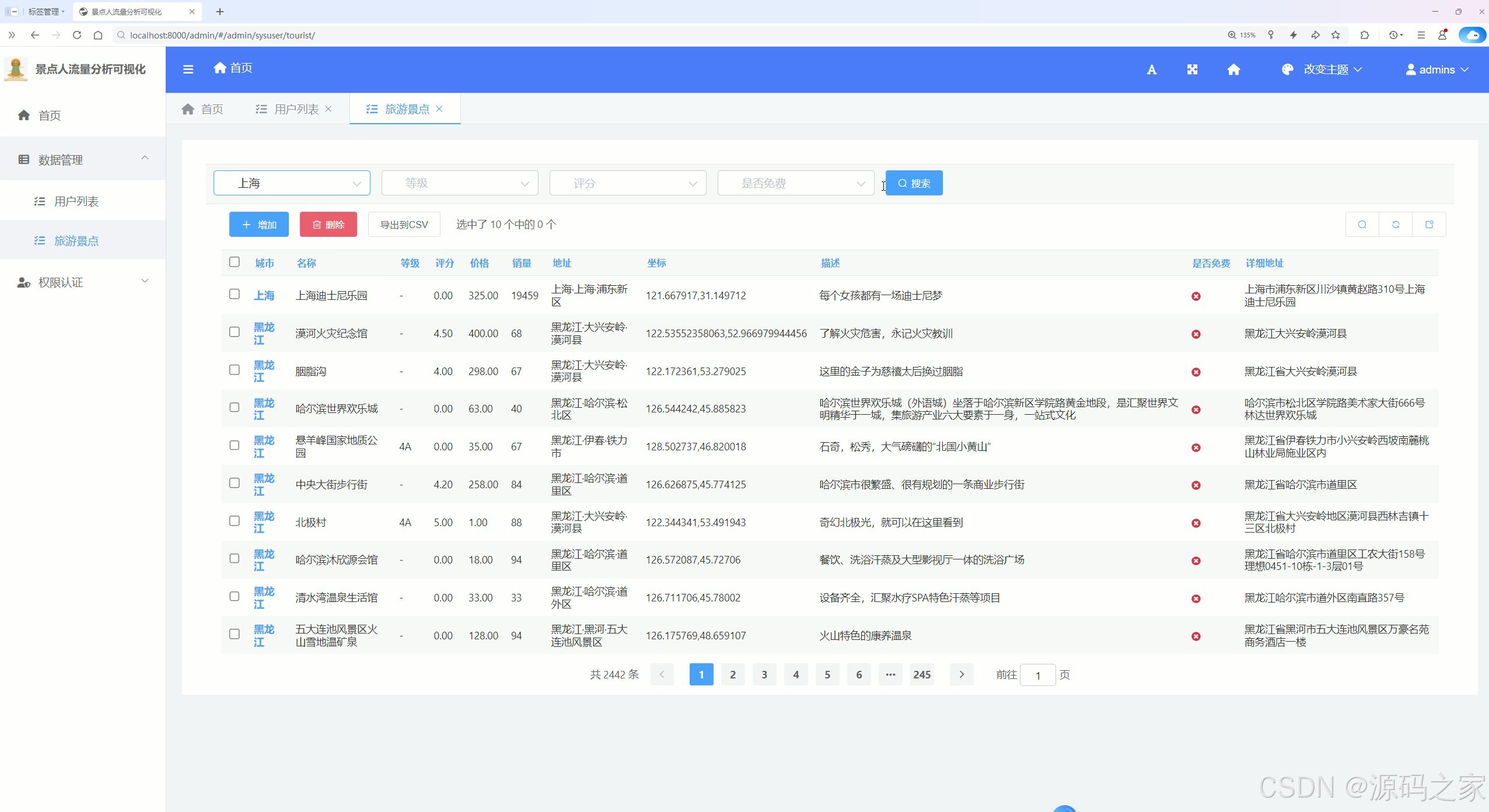
2、项目界面
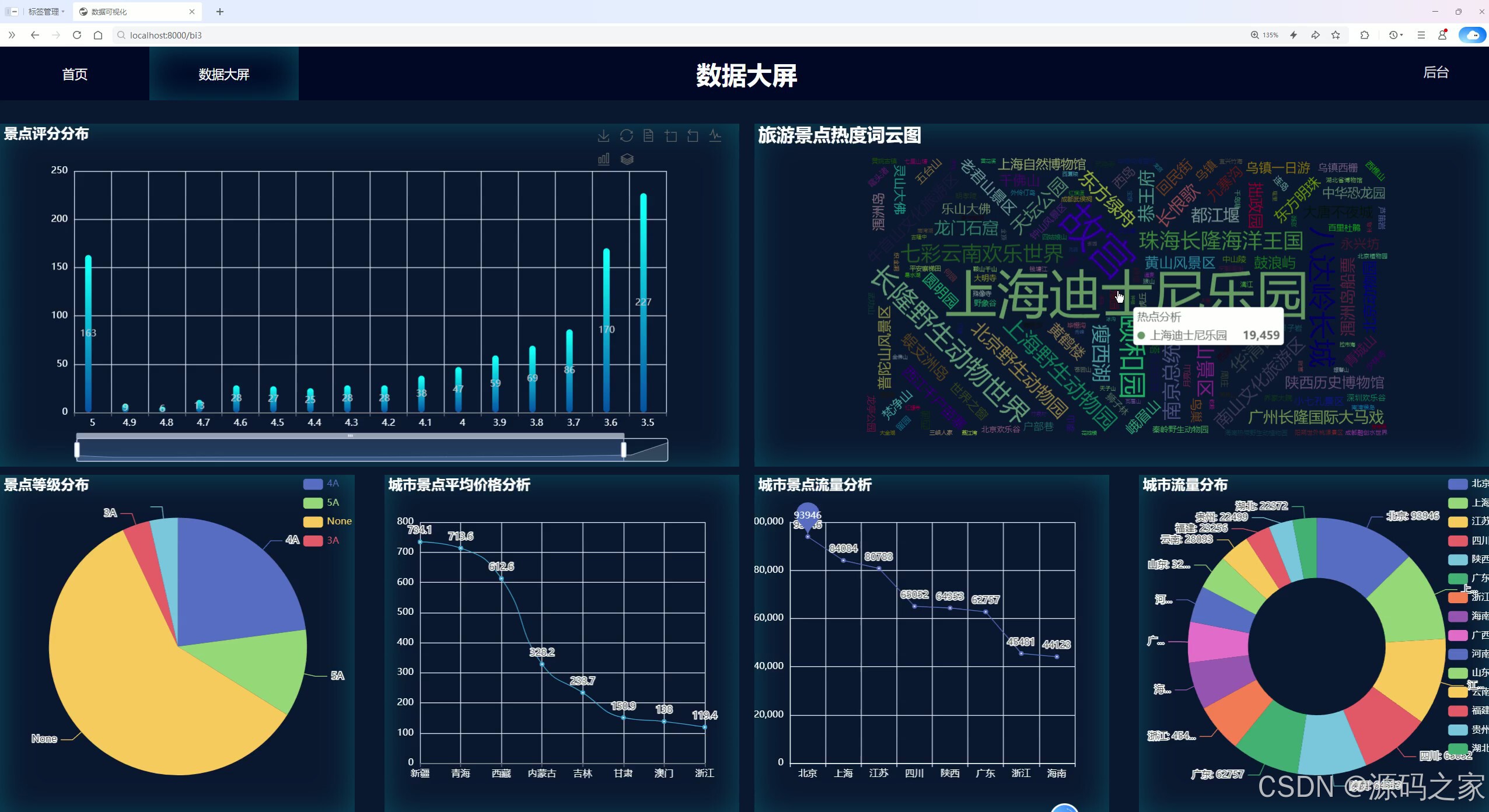
(1)数据分析大屏
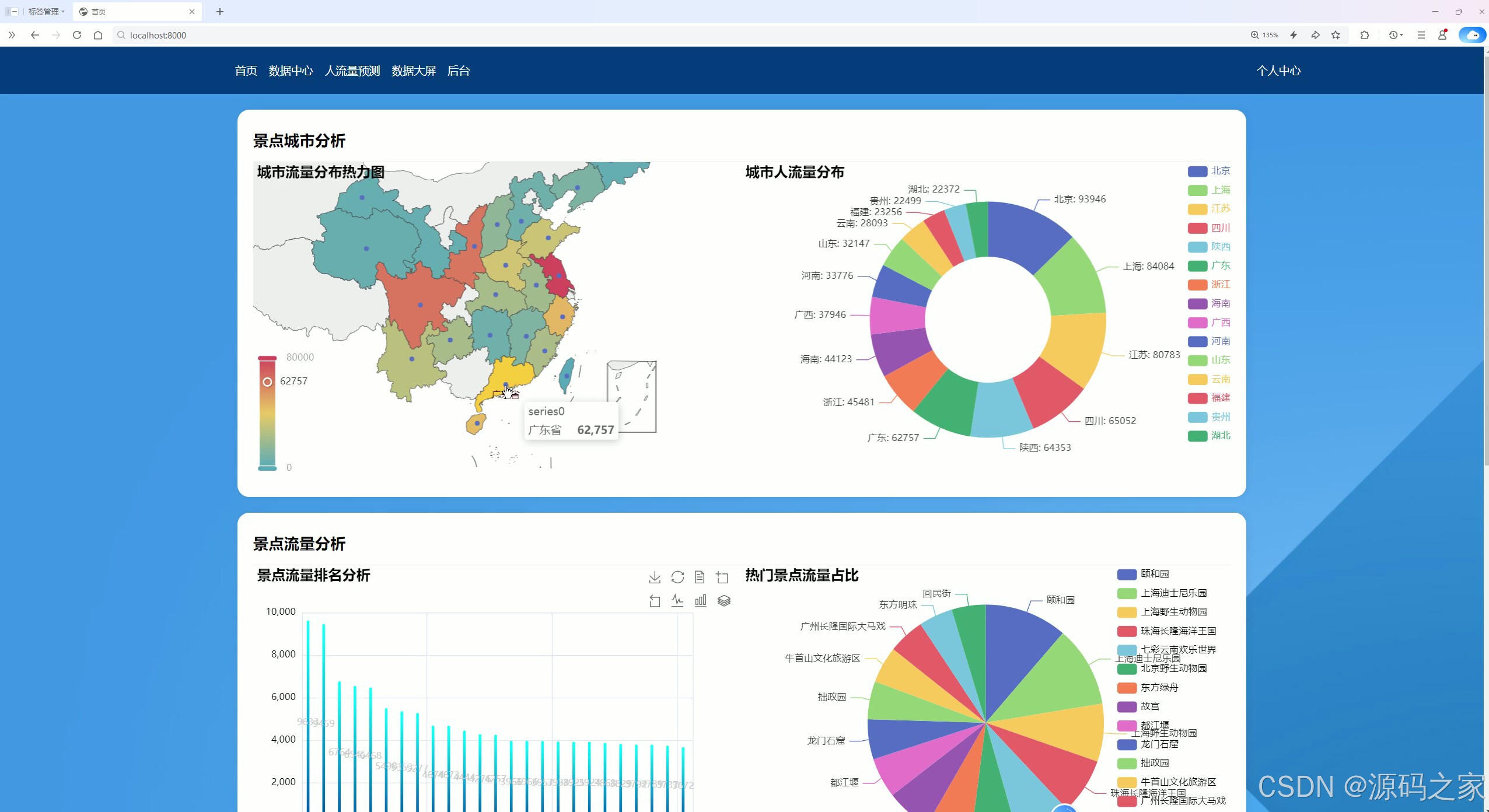
(2)数据分析1
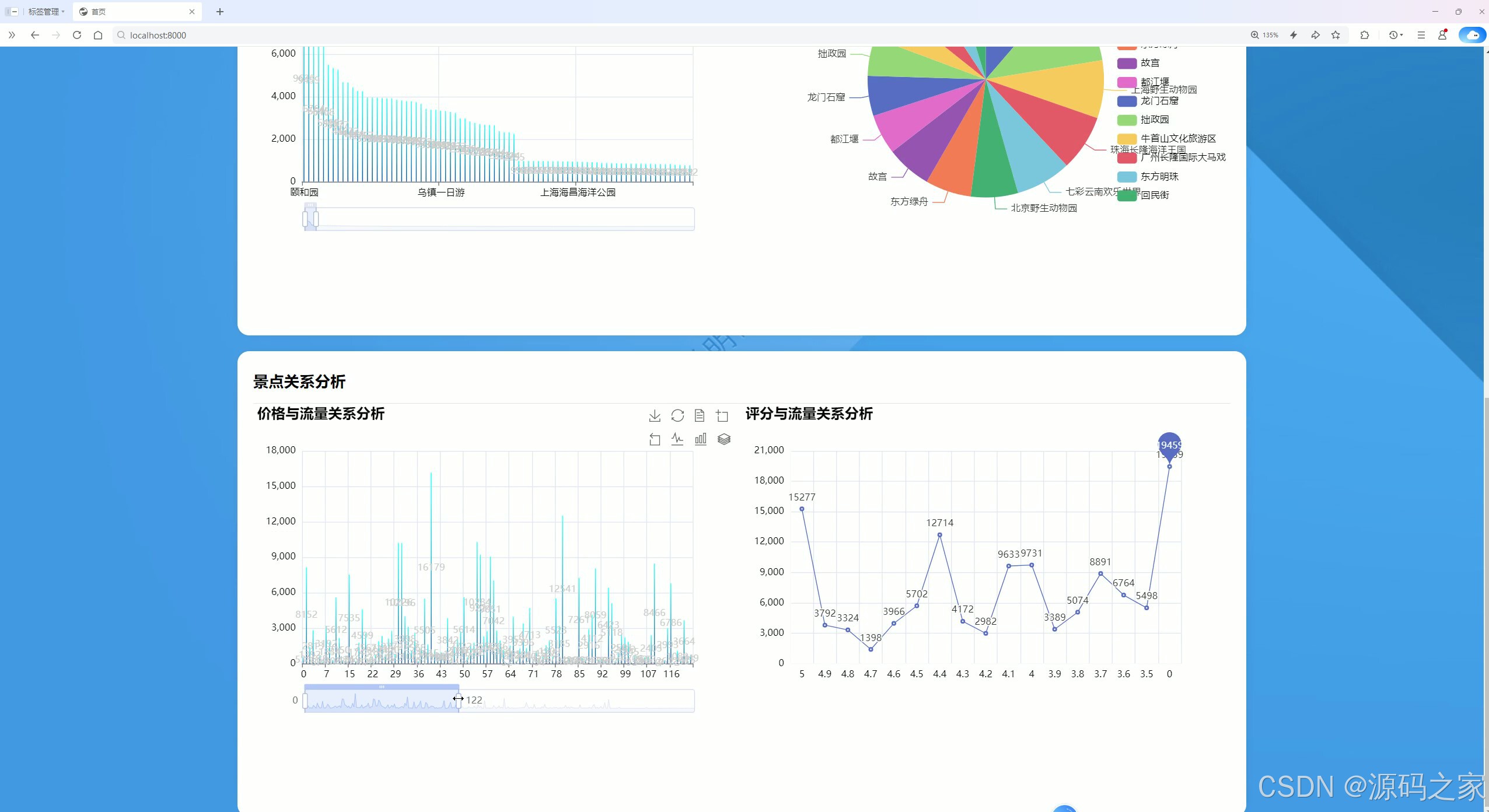
(3)数据分析2
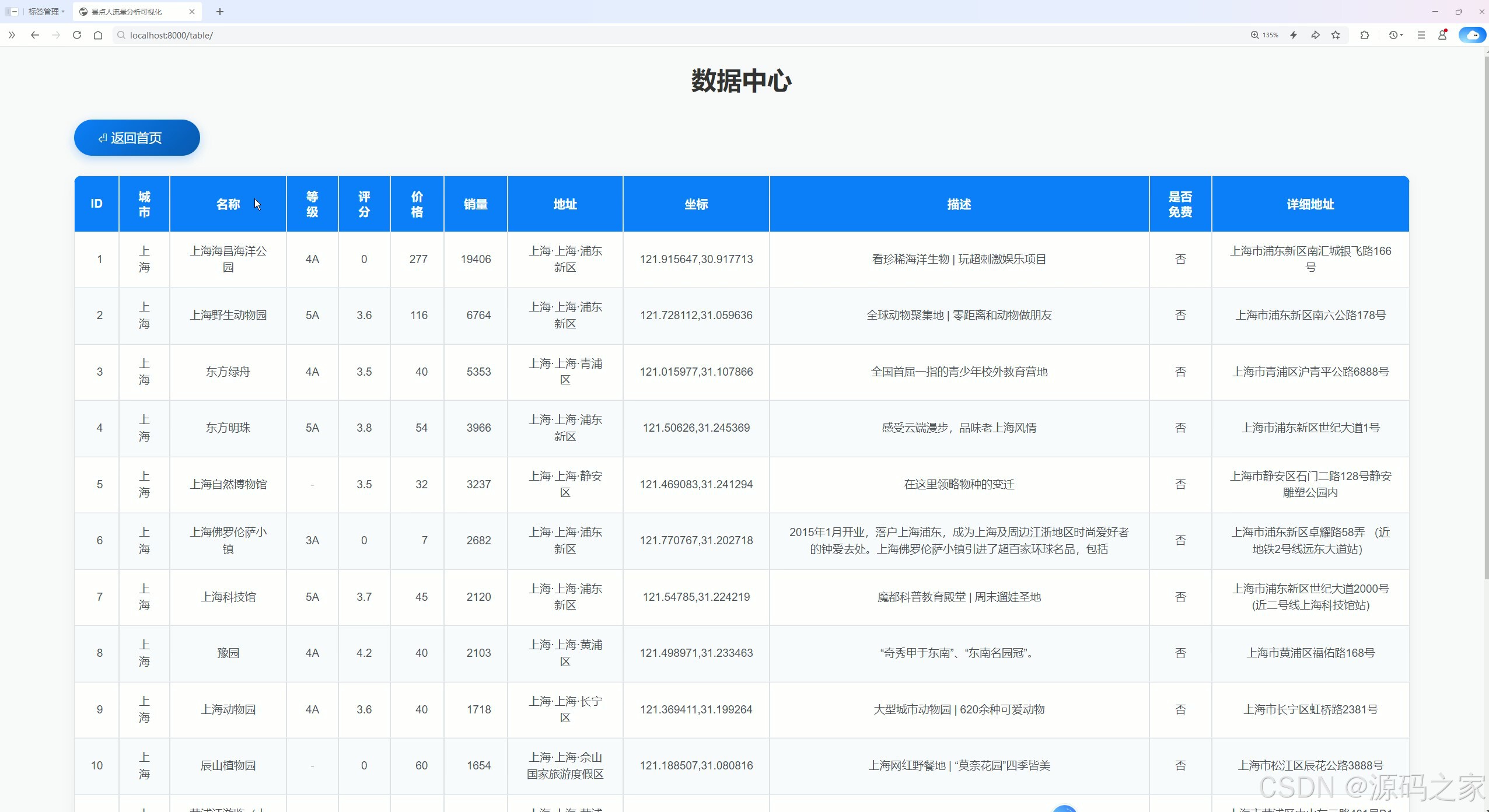
(4)数据中心
(5)人流量预测
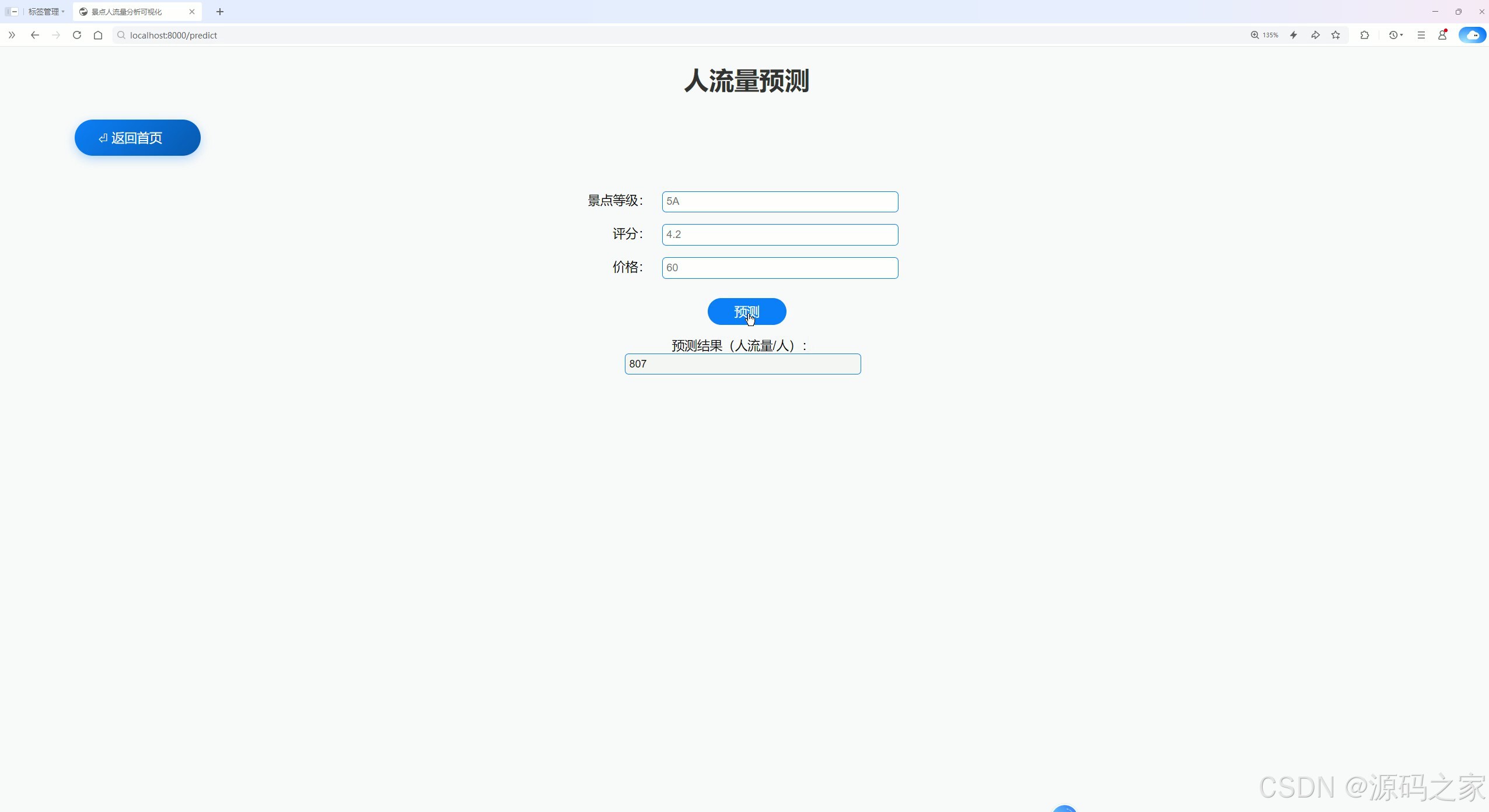
(6)人流量预测2
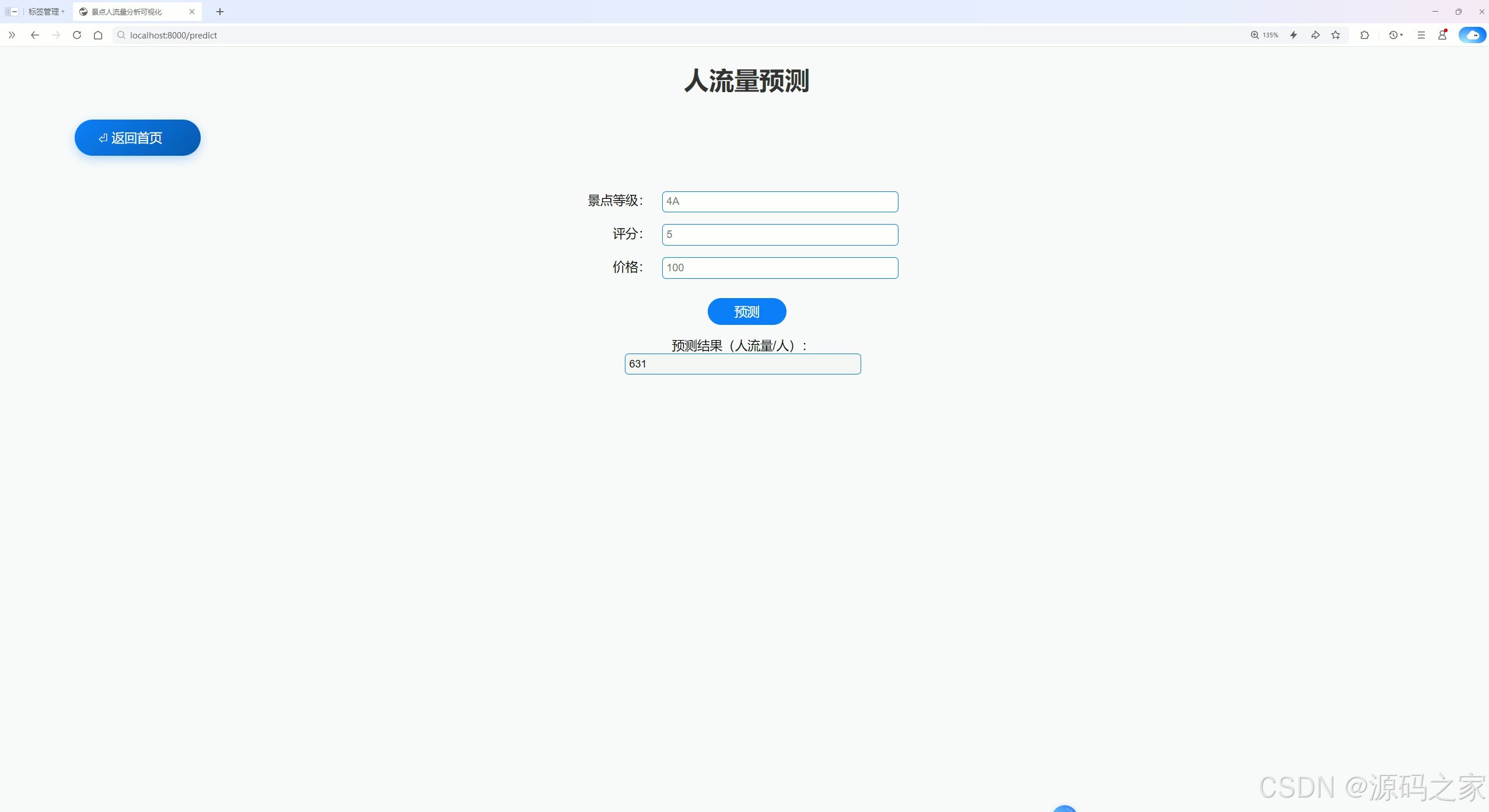
(7)个人中心
(8)注册登录
(9)后台管理
3、项目说明
一、预测
sysuser/views.py
算法:线性回归(Linear Regression)
原理:基于Scikit-learn库的LinearRegression类实现,适用于通过连续型特征(评分、价格)和编码后的分类特征(景点等级),预测连续型目标(人流量)。
核心流程:
- 数据获取与预处理:从tourist数据库表读取数据,删除冗余的describe列;填充景点等级(level)空值为“0A”,将评分(score)、价格(price)、人流量(sales)转为数值型,删除缺失值。
- 分类特征编码:用LabelEncoder将“0A”“1A”等文本型等级(level)转为数值,适配模型输入。
- 数据拆分与标准化:选level“score”“price”为特征(X)、sales为人流量目标(y);按8:2拆分训练/测试集,用StandardScaler标准化特征,消除量纲影响。
- 模型训练:用训练集拟合线性回归模型,学习特征与人流量的线性关系。
- 模型评估:通过均方误差(MSE)、均方根误差(RMSE)评估模型在测试集上的预测误差。
- 用户输入预测:接收前端传入的等级、评分、价格,重复编码/标准化处理后,用训练好的模型预测人流量,结果取整后返回页面。
摘要
随着信息技术的发展,大数据已成为推动各行各业转型升级的重要力量。在旅游业中,大数据的应用能够帮助管理者更好地理解游客行为模式,预测人流趋势,从而制定科学的管理策略。景点人流量作为反映旅游热度的重要指标,其有效分析与管理对于缓解拥堵、提升服务质量具有重要意义。
当前,国内外已有不少学者和机构对景点人流量分析进行了广泛研究,主要集中在数据采集、模型构建与预测分析等方面。然而,现有研究多侧重于单一数据源或传统统计方法,难以全面反映大数据时代的复杂性和动态性。因此,如何充分利用大数据技术,整合多源数据,实现更加精准、高效的人流量分析,成为当前研究的热点和难点。
本文基于大数据技术,提出了一种综合性的景点人流量分析系统。该系统通过集成多源数据,运用先进的数据挖掘与机器学习算法,实现对景点人流量的实时监测、历史分析与未来预测。同时,本文还针对系统的性能、强壮性、逻辑性和安全性进行了全面测试与优化,确保了系统的稳定性和可靠性。本研究为旅游业的人流量管理提供了新思路和新方法,具有较高的理论价值和实践意义。
关键词:大数据,景点人流量,分析系统,数据挖掘,机器学习
4、核心代码
def predict(request):
if request.method == 'POST':
# 从数据库读取数据到csv
import pandas as pd
from sqlalchemy import create_engine
import pymysql
from project.settings import DATABASE_NAME, DATABASE_USER, DATABASE_PSW, DATABASE_PORT, \
DATABASE_HOST
db_host = DATABASE_HOST
db_username = DATABASE_USER
db_password = DATABASE_PSW
db_port = DATABASE_PORT
db_name = DATABASE_NAME
conn = pymysql.connect(host=db_host, user=db_username, password=db_password, db=db_name, port=db_port)
engine = create_engine(f'mysql+pymysql://{db_username}:{db_password}@{db_host}:{db_port}/{db_name}')
# 从数据库读取数据到 DataFrame
read_data = pd.read_sql('tourist', con=engine)
data = read_data.copy()
data.drop(['describe'], axis=1, inplace=True)
data['level'] = data['level'].fillna('0A')
data['score'] = data['score'].astype(float)
def convert_to_numeric(series):
return pd.to_numeric(series, errors='coerce')
data['score'] = convert_to_numeric(data['score'])
data['price'] = convert_to_numeric(data['price'])
data['sales'] = convert_to_numeric(data['sales'])
data.dropna(inplace=True)
#导包
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 编码分类变量
label_encoder = LabelEncoder()
data['level'] = label_encoder.fit_transform(data['level'].astype(str))
# 特征选择
features = ['level', 'score', 'price']
X = data[features]
y = data['sales']
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 模型训练 (线性回归)
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 模型评估
mse = mean_squared_error(y_test, y_pred) / 1000000
rmse = mse ** 0.5
r2 = r2_score(y_test, y_pred)
print(f'均方误差 (MSE): {mse}')
print(f'均方根误差 (RMSE): {rmse}')
# print(f'R²: {r2}')
level = request.POST.get('level')
price = request.POST.get('price')
score = request.POST.get('score')
try:
# 创建一个 DataFrame 来存放单条数据
new_data = pd.DataFrame({
'level': [level], # 替换为实际的 level
'score': [score], # 替换为实际的 score
'price': [price] # 替换为实际的 price
})
new_data['level'] = label_encoder.transform(new_data['level'])
# 特征选择
features = ['level', 'score', 'price']
X_new = new_data[features]
# 标准化
X_new = scaler.transform(X_new)
# 预测
y_pred = model.predict(X_new)
y_pred = round(y_pred[0])
print(f'预测人流量: {y_pred}')
return render(request, 'html/predict.html', locals())
except Exception as e:
print(e)
y_pred = '错误:'+str(e)
return render(request, 'html/predict.html', locals())
else:
return render(request, 'html/predict.html', locals())
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻


















 9035
9035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









