










毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
NBA球员数据分析及预测系统
技术栈
Python语言、Flask框架、requests爬虫、statsmodels中的ARIMA时间序列预测算法、Echarts可视化
NBA球员数据分析及预测系统是一个基于Python语言和Flask框架构建的综合性平台,旨在帮助篮球爱好者、教练和球队管理者深入分析和预测NBA球员的表现。该系统结合了requests爬虫、statsmodels中的ARIMA时间序列预测算法以及Echarts可视化技术,为用户提供了丰富的数据分析和预测功能。
2、项目界面
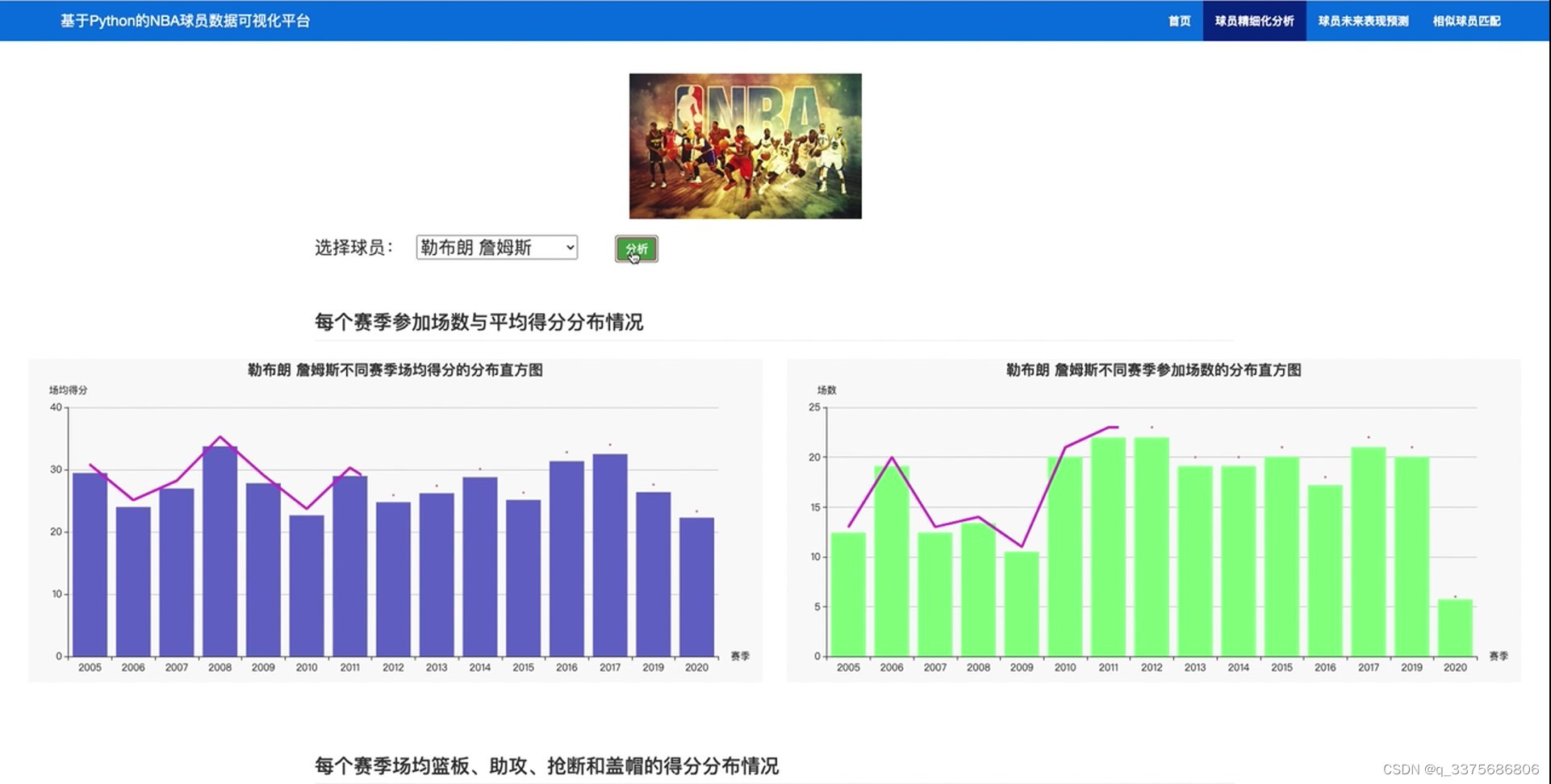
(1) 球员数据分析1----每个赛季参加场数与平均得分分布情况
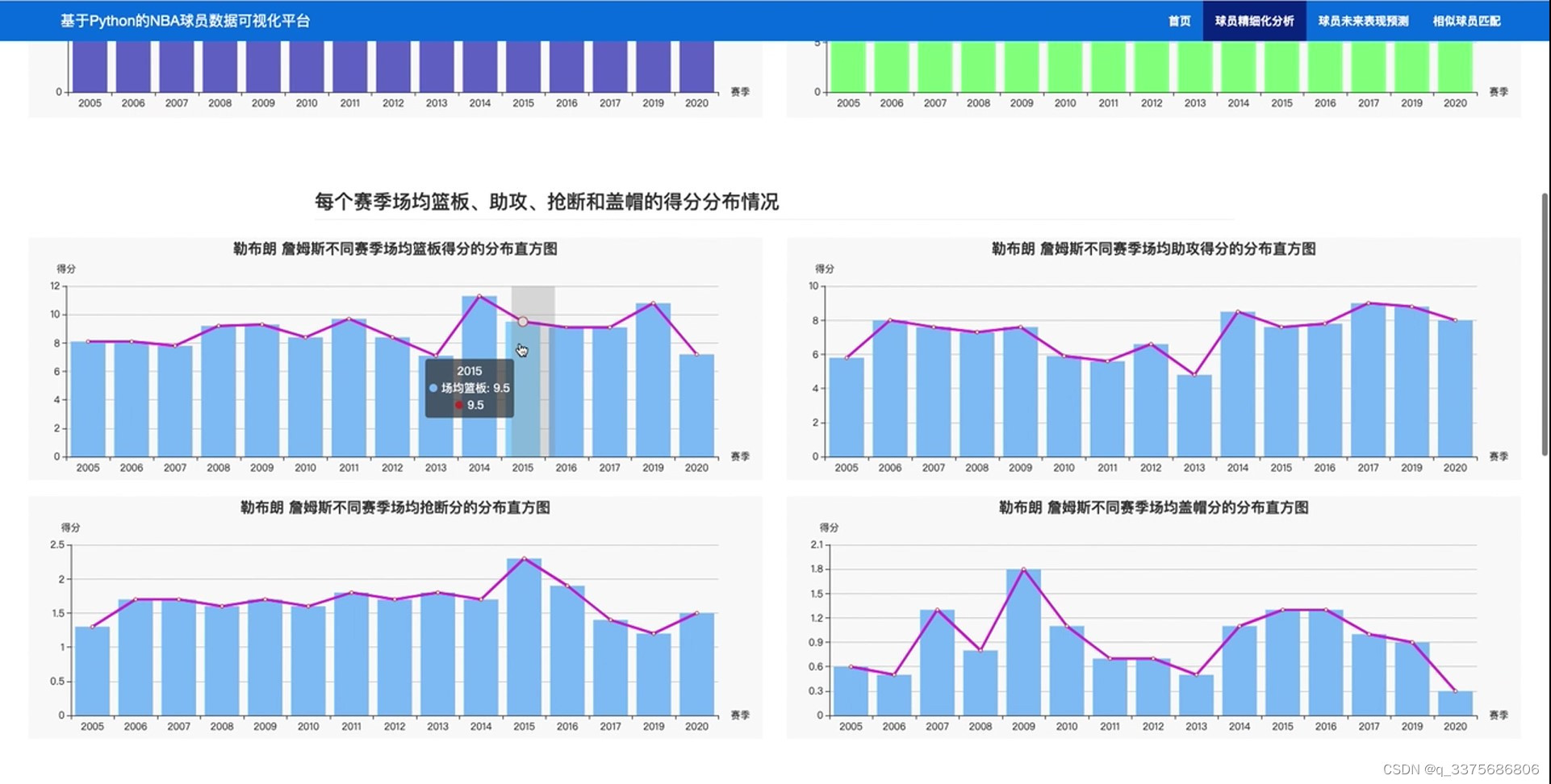
(2)球员数据分析2----每个赛季场均篮板、助攻、抢断和盖帽的得分分布情况
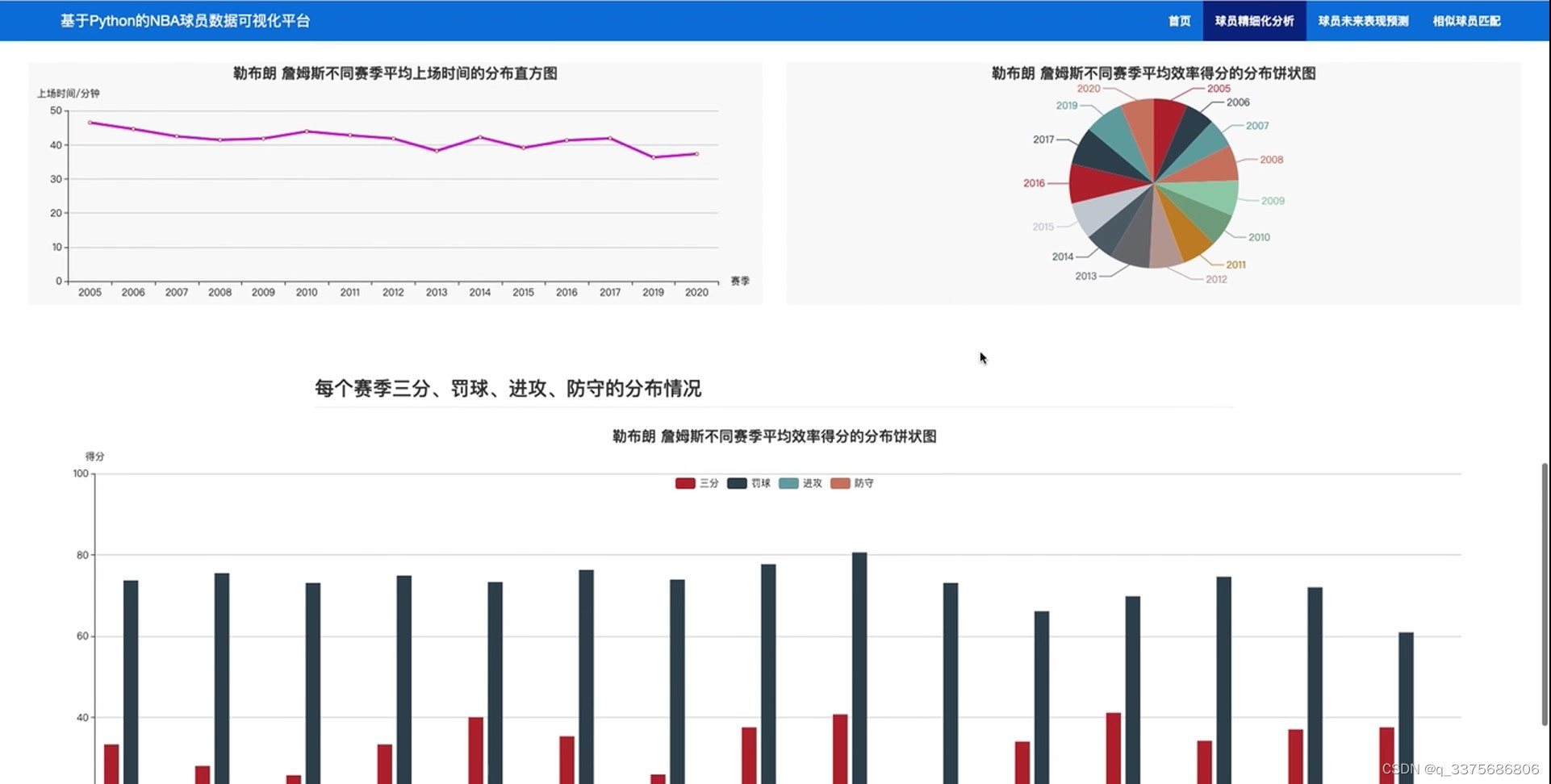
(3)球员数据分析3----每个赛季三分、罚球、进攻、防守的分布情况
(4)首页----注册登录
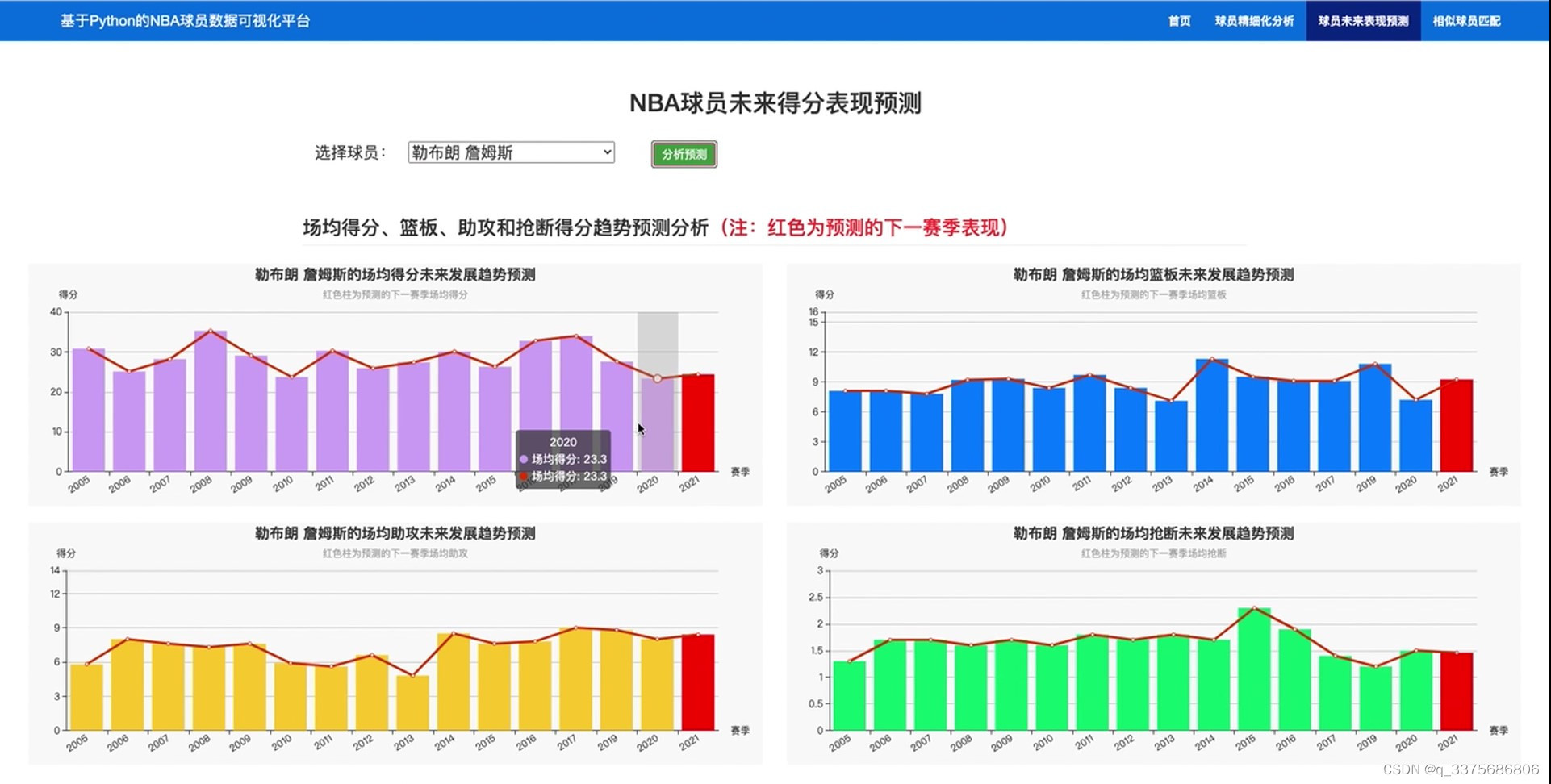
(5)NBA球员未来得分表现预测----时间序列预测算法
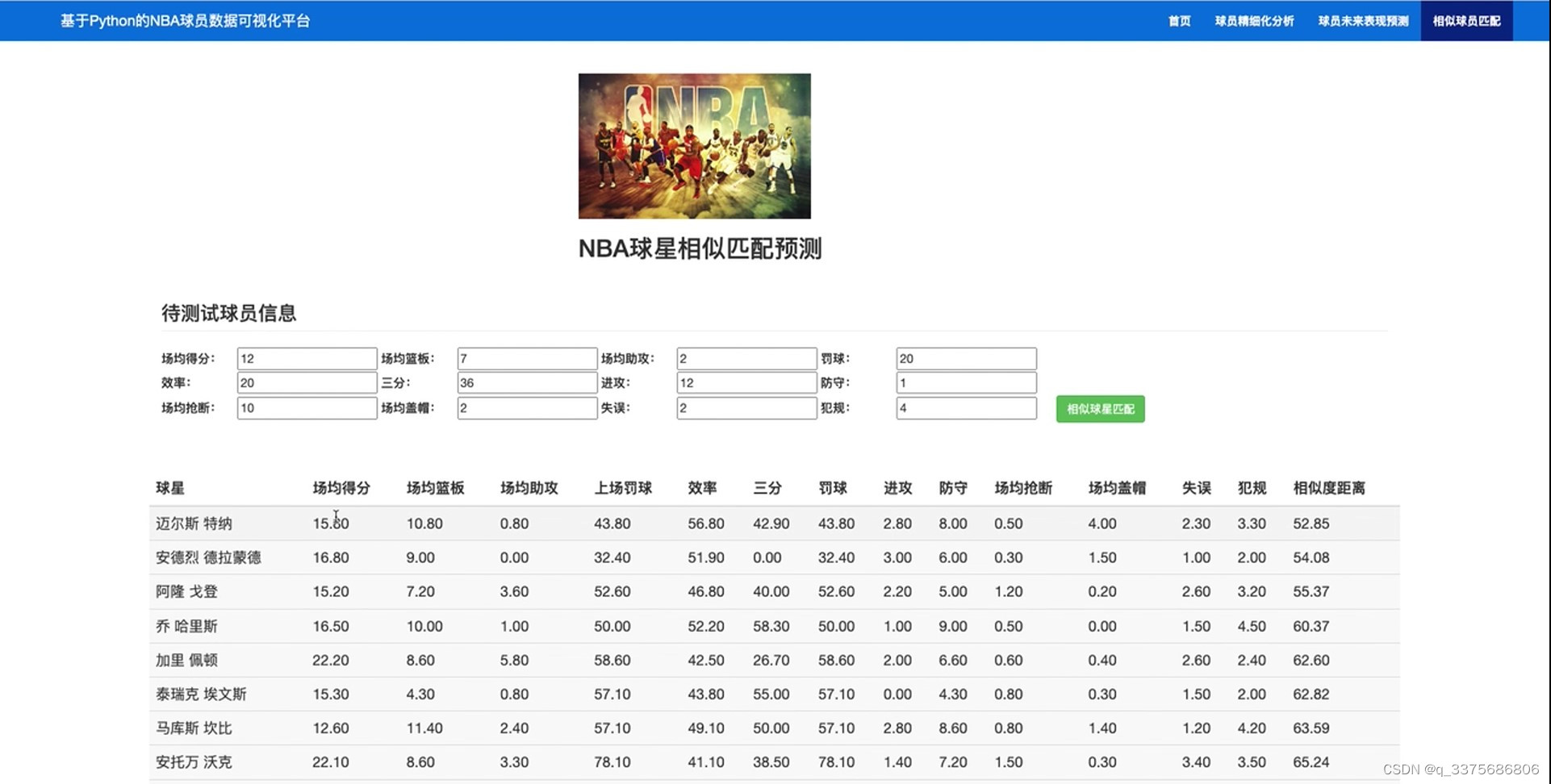
(6)NBA球星相似匹配预测
3、项目说明
NBA球员数据分析及预测系统是一个基于Python语言和Flask框架构建的综合性平台,旨在帮助篮球爱好者、教练和球队管理者深入分析和预测NBA球员的表现。该系统结合了requests爬虫、statsmodels中的ARIMA时间序列预测算法以及Echarts可视化技术,为用户提供了丰富的数据分析和预测功能。
首先,系统具备强大的数据收集和处理能力。通过使用requests爬虫,系统能够自动从NBA官方网站或其他可靠数据源抓取球员的详细数据,包括赛季参加场数、平均得分、场均篮板、助攻、抢断、盖帽、三分命中率、罚球命中率以及进攻和防守效率等关键指标。这些数据为后续的数据分析和预测提供了坚实的基础。
在数据分析方面,系统提供了三个主要的功能模块。第一个模块专注于球员每个赛季的参加场数与平均得分的分布情况,帮助用户了解球员的出勤率和得分能力。第二个模块分析了球员每个赛季在篮板、助攻、抢断和盖帽等关键数据上的得分分布情况,揭示了球员在比赛中的全面表现。第三个模块则关注于球员在三分、罚球、进攻和防守等方面的数据,帮助用户更全面地评估球员的投篮技巧和攻防能力。
除了数据分析功能外,系统还具备强大的预测能力。通过集成statsmodels中的ARIMA时间序列预测算法,系统能够对NBA球员未来的得分表现进行预测。这种预测能力不仅有助于球队管理者制定更加科学的球员选拔和培训计划,还能帮助篮球爱好者更准确地预测比赛结果。
此外,系统还提供了NBA球星相似匹配预测功能。通过对比不同球员在各项关键数据上的表现,系统能够找出与特定球员相似的其他球员,从而为用户提供更加个性化的推荐和参考。
在界面设计方面,系统采用了简洁明了的风格,结合Bootstrap框架的响应式设计,使得用户能够在各种设备上获得良好的使用体验。同时,系统还提供了丰富的可视化图表,如柱状图、折线图和饼图等,帮助用户更加直观地了解和分析数据。
总之,NBA球员数据分析及预测系统是一个功能强大、易于使用的综合性平台。它不仅能够帮助用户深入了解NBA球员的表现和潜力,还能提供准确的预测和个性化的推荐。无论是篮球爱好者还是球队管理者,都能在这个系统中找到有价值的信息和支持。
4、核心代码
#!/usr/bin/python
# coding=utf-8
import json
import sqlite3
import time
import numpy as np
import pandas as pd
from flask import Flask, render_template, jsonify, request
from statsmodels.tsa.arima.model import ARIMA
app = Flask(__name__)
app.debug = True
login_name = None
all_players = []
with open('nab_player.json', 'r', encoding='utf8') as f:
for line in f:
player = json.loads(line.strip())
info = {
'姓名': player['playerProfile']['displayName'],
'赛季': player['season'],
"排名": player['rank'],
"球队": player['teamProfile']['name'],
"场数": player['statAverage']['games'],
"先发": player['statAverage']['gamesStarted'],
"场均得分": player['statAverage']['pointsPg'],
"场均篮板": player['statAverage']['rebsPg'],
"场均助攻": player['statAverage']['assistsPg'],
"分钟": player['statAverage']['minsPg'],
"效率": player['statAverage']['fgpct'],
"三分": player['statAverage']['tppct'],
"罚球": player['statAverage']['ftpct'],
"进攻": player['statAverage']['offRebsPg'],
"防守": player['statAverage']['defRebsPg'],
"场均抢断": player['statAverage']['stealsPg'],
"场均盖帽": player['statAverage']['blocksPg'],
"失误": player['statAverage']['turnoversPg'],
"犯规": player['statAverage']['foulsPg']
}
all_players.append(info)
all_players = pd.DataFrame(all_players, )
all_players = all_players.sort_values(by='赛季', ascending=False)
print(all_players)
# --------------------- html render ---------------------
@app.route('/')
def index():
return render_template('index.html')
@app.route('/player_basic_analysis')
def player_basic_analysis():
return render_template('player_basic_analysis.html')
@app.route('/player_predict')
def player_predict():
return render_template('player_predict.html')
@app.route('/similar_player_predict')
def similar_player_predict():
return render_template('similar_player_predict.html')
# ------------------ ajax restful api -------------------
@app.route('/check_login')
def check_login():
"""判断用户是否登录"""
return jsonify({'username': login_name, 'login': login_name is not None})
@app.route('/register/<name>/<password>')
def register(name, password):
conn = sqlite3.connect('user_info.db')
cursor = conn.cursor()
check_sql = "SELECT * FROM sqlite_master where type='table' and name='user'"
cursor.execute(check_sql)
results = cursor.fetchall()
# 数据库表不存在
if len(results) == 0:
# 创建数据库表
sql = """
CREATE TABLE user(
name CHAR(256),
password CHAR(256)
);
"""
cursor.execute(sql)
conn.commit()
print('创建数据库表成功!')
sql = "INSERT INTO user (name, password) VALUES (?,?);"
cursor.executemany(sql, [(name, password)])
conn.commit()
return jsonify({'info': '用户注册成功!', 'status': 'ok'})
@app.route('/login/<name>/<password>')
def login(name, password):
global login_name
conn = sqlite3.connect('user_info.db')
cursor = conn.cursor()
check_sql = "SELECT * FROM sqlite_master where type='table' and name='user'"
cursor.execute(check_sql)
results = cursor.fetchall()
# 数据库表不存在
if len(results) == 0:
# 创建数据库表
sql = """
CREATE TABLE user(
name CHAR(256),
password CHAR(256)
);
"""
cursor.execute(sql)
conn.commit()
print('创建数据库表成功!')
sql = "select * from user where name='{}' and password='{}'".format(name, password)
cursor.execute(sql)
results = cursor.fetchall()
login_name = name
if len(results) > 0:
return jsonify({'info': name + '用户登录成功!', 'status': 'ok'})
else:
return jsonify({'info': '当前用户不存在!', 'status': 'error'})
@app.route('/get_all_players/<predict>')
def get_all_players(predict):
"""获取所有球员名称"""
if predict == 'predict':
max_season = all_players['赛季'].max()
print(max_season)
dis_count = all_players[all_players['赛季'] == max_season]['姓名'].value_counts()
else:
dis_count = all_players['姓名'].value_counts()
players = list(dis_count.keys())
return jsonify(players)
@app.route('/player_statistic/<player>')
def player_statistic(player):
df = all_players[all_players['姓名'] == player]
return jsonify({
'赛季': df['赛季'].values.tolist(),
'场均得分': df['场均得分'].values.tolist(),
'场数': df['场数'].values.tolist(),
"场均篮板": df['场均篮板'].values.tolist(),
"场均助攻": df['场均助攻'].values.tolist(),
"场均抢断": df['场均抢断'].values.tolist(),
"场均盖帽": df['场均盖帽'].values.tolist(),
"分钟": df['分钟'].values.tolist(),
"效率": df['效率'].values.tolist(),
"三分": df['三分'].values.tolist(),
"罚球": df['罚球'].values.tolist(),
"进攻": df['进攻'].values.tolist(),
"防守": df['防守'].values.tolist(),
})
def arima_model_train_eval(history):
# 构造 ARIMA 模型
model = ARIMA(history, order=(1, 1, 0))
# 基于历史数据训练
model_fit = model.fit()
# 预测下一个时间步的值
output = model_fit.forecast()
yhat = output[0]
return yhat
@app.route('/future_predict/<player>')
def future_predict(player):
time.sleep(1)
df = all_players[all_players['姓名'] == player]
# 赛季
saijis = df['赛季'].values.tolist()
saijis.append(saijis[-1] + 1)
try:
# 场均得分
scores = df['场均得分'].values.tolist()
predict_score = arima_model_train_eval(scores)
scores.append(predict_score)
# 场均篮板
lanbans = df['场均篮板'].values.tolist()
predict_lanban = arima_model_train_eval(lanbans)
lanbans.append(predict_lanban)
# 场均助攻
zhugongs = df['场均助攻'].values.tolist()
predict_zhugong = arima_model_train_eval(zhugongs)
zhugongs.append(predict_zhugong)
# 场均抢断
jiangduans = df['场均抢断'].values.tolist()
predict_jiangduan = arima_model_train_eval(jiangduans)
jiangduans.append(predict_jiangduan)
except Exception:
return jsonify({'success': False, 'message': f'该球员赛季数据过少({len(saijis)}),无法构建时序模型进行预测。'})
return jsonify({
'success': True,
'赛季': saijis,
'场均得分': scores,
'场均篮板': lanbans,
'场均助攻': zhugongs,
'场均抢断': jiangduans,
})
player_group = {k: table for k, table in all_players.groupby('姓名')}
print(all_players.columns.values.tolist())
print(all_players)
def cal_euclidean_distance(x, y):
""""计算两个特征向量的欧氏距离"""
dist = np.sqrt(np.sum(np.square(x - y))) # 注意:np.array 类型的数据可以直接进行向量、矩阵加减运算。np.square 是对每个元素求平均~~~~
return dist
@app.route('/predict_similar_players')
def predict_similar_players():
"""构建机器学习算法,利用历年赛季球员得分表现、进攻防守、年龄、身高、体重等信息,对该球员与NBA某球星进行匹配预测。"""
columns = ['场均得分', '场均篮板', '场均助攻', '罚球', '效率', '三分', '罚球', '进攻', '防守', '场均抢断', '场均盖帽', '失误', '犯规']
test_player_feature = []
for c in columns:
v = request.args.get(c)
test_player_feature.append(float(v))
player_distance = {}
print('待测试球员特征向量:', test_player_feature)
test_player_feature = np.array(test_player_feature)
for player in player_group:
player_df = player_group[player][columns]
player_feature = player_df.mean(axis=0).values
print(player, player_feature)
# 计算待测试球员与 NBA 球星特征向量的距离
dist = cal_euclidean_distance(test_player_feature, player_feature)
player_distance[player] = dist
# 按照相似距离就行排序
player_distance = sorted(player_distance.items(), key=lambda x: x[1])
print(player_distance)
# 选择相似度 TOP5 的NBA球星数据
similar_players = []
for player_dist in player_distance:
player, dist = player_dist
# 球星姓名
row = [player]
# 特征值
feat = player_group[player][columns].values.tolist()[0]
row.extend(feat)
# 相似度得分
row.append(dist)
similar_players.append(row)
return jsonify(similar_players[:10])
if __name__ == "__main__":
app.run(host='127.0.0.1')
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

















 3773
3773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









