



博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
- 技术栈:Python语言、Flask框架、MySQL数据库、requests爬虫、Echarts可视化大屏、推荐算法(Surprise库KNNWithZScore)、HTML、机器学习集成学习(Stacking模型融合决策树/Lasso/随机森林/GDBT(梯度提升树)4个算法)
- 这个项目的研究背景:数字化时代视频内容消费爆炸式增长,用户面临海量电影“选择困难”,传统推荐机制泛化性差、精准度低,难以匹配个性化偏好;同时电影行业缺乏可靠的票房预测工具,依赖经验判断导致内容创作与营销策略盲目,且电影数据(信息、评论、票房)分散,人工采集分析效率低,这些痛点制约用户体验与行业精细化发展。
- 这个项目的研究意义:技术层面,通过Stacking模型融合4个算法提升票房预测精度,KNNWithZScore算法优化推荐效果,requests爬虫解决数据分散问题,Echarts降低数据理解门槛;用户层面,提供个性化推荐、直观可视化及便捷信息查询,减少选片时间;行业层面,为电影行业提供受众需求洞察与票房预测参考,助力内容创作与营销精细化,推动行业数据驱动发展。
2、项目界面
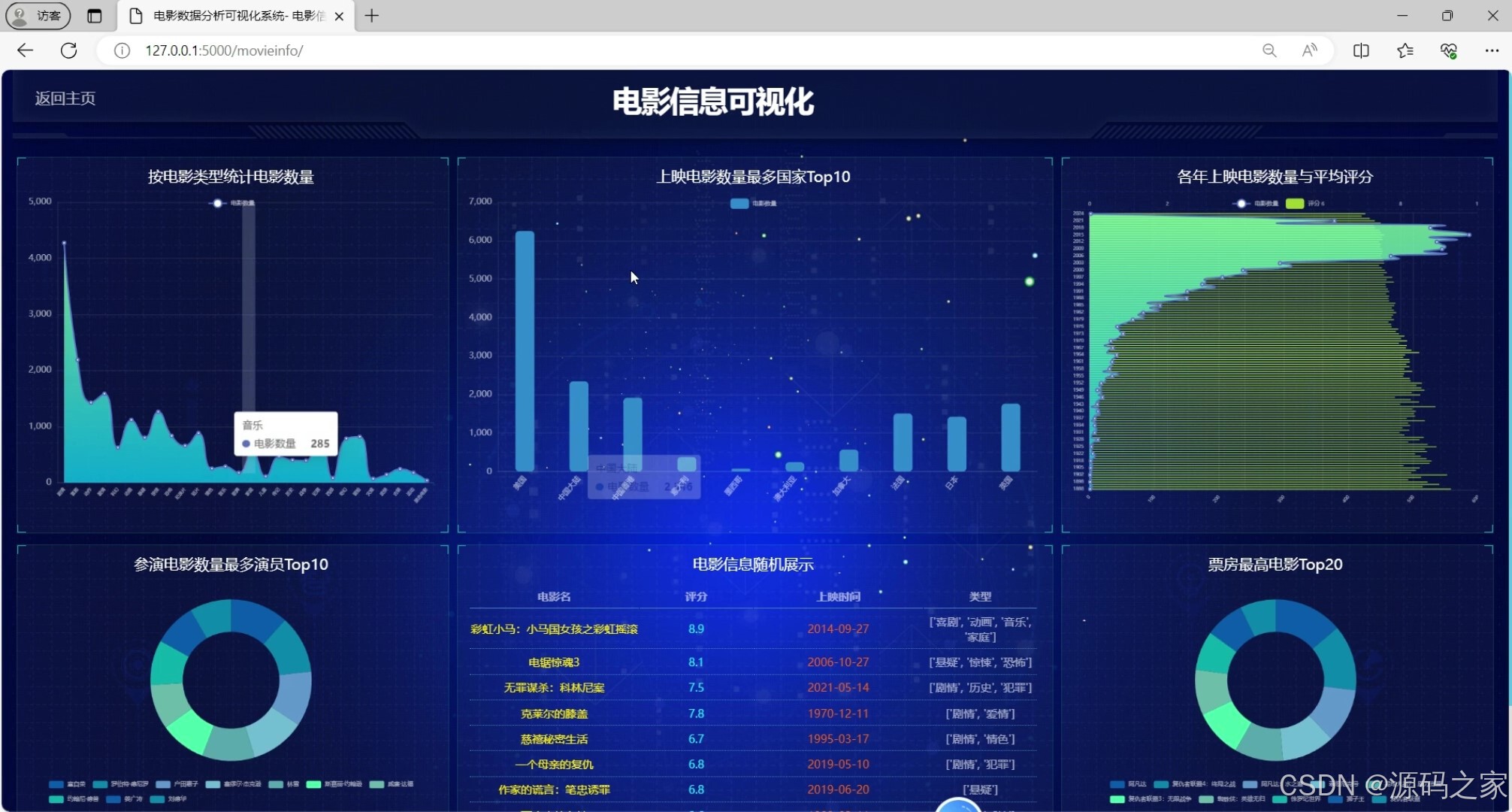
(1)电影数据可视化大屏
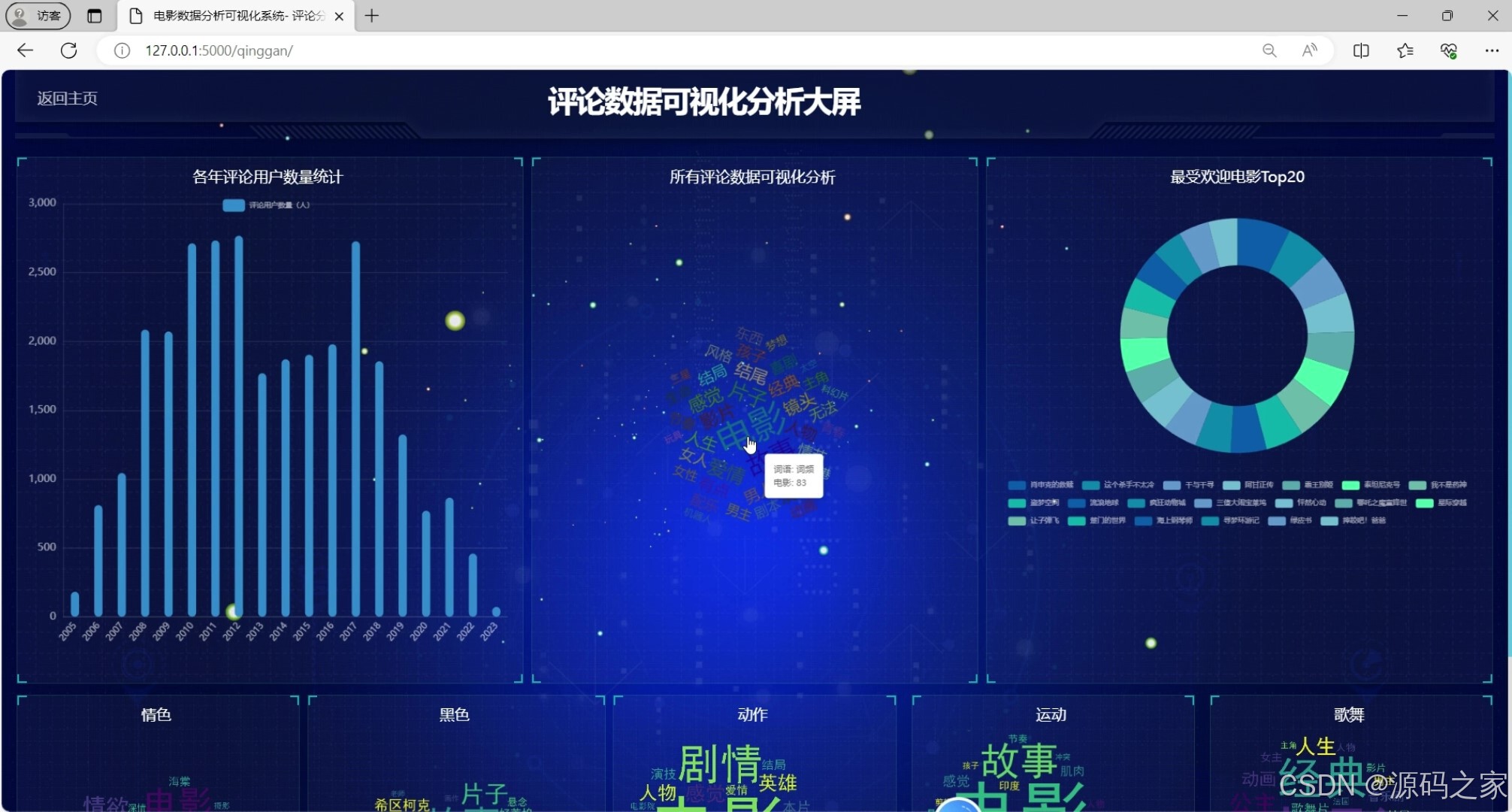
(2)电影评论数据可视化分析大屏
(3)电影数据

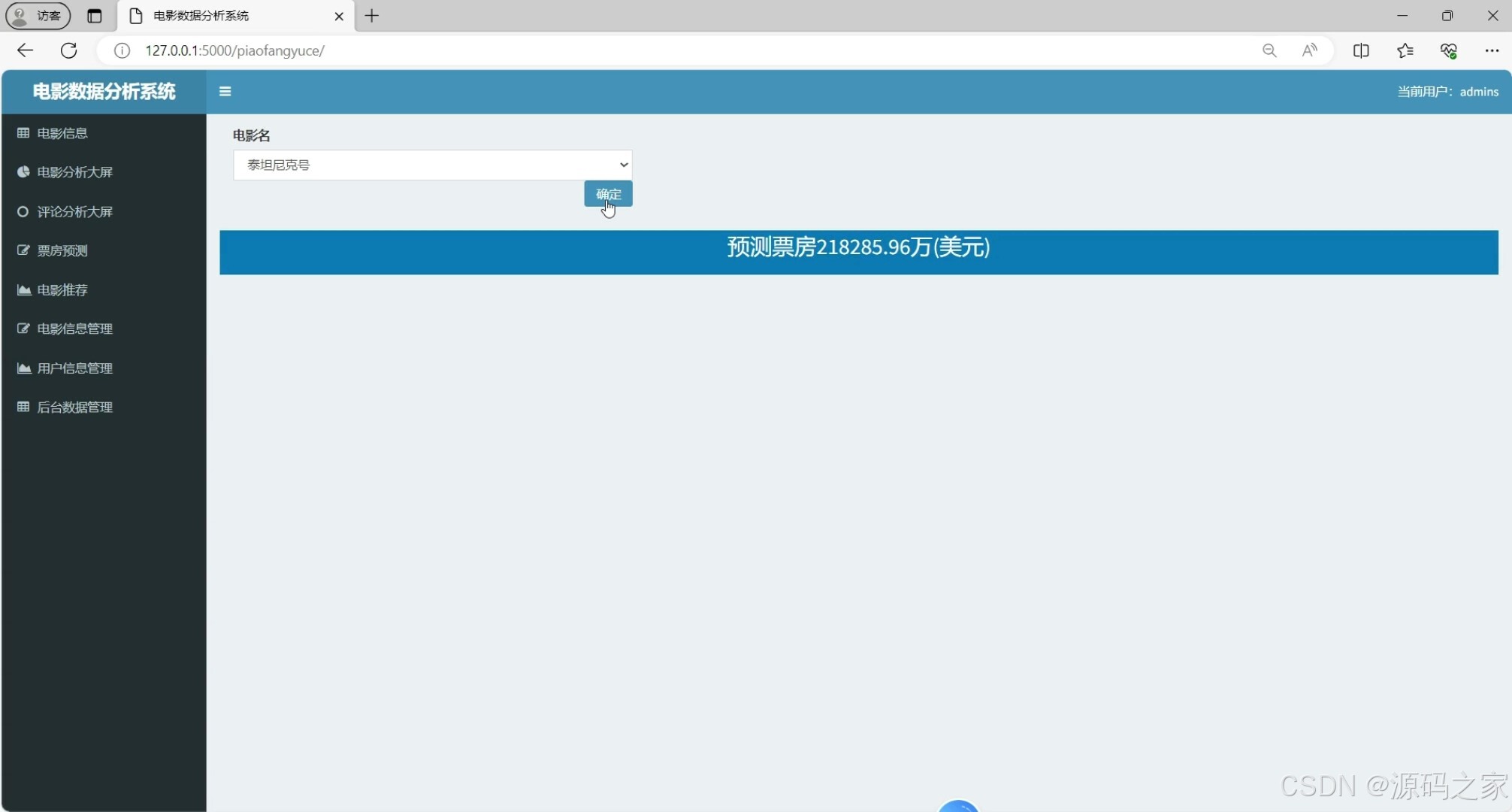
(4)电影票房预测
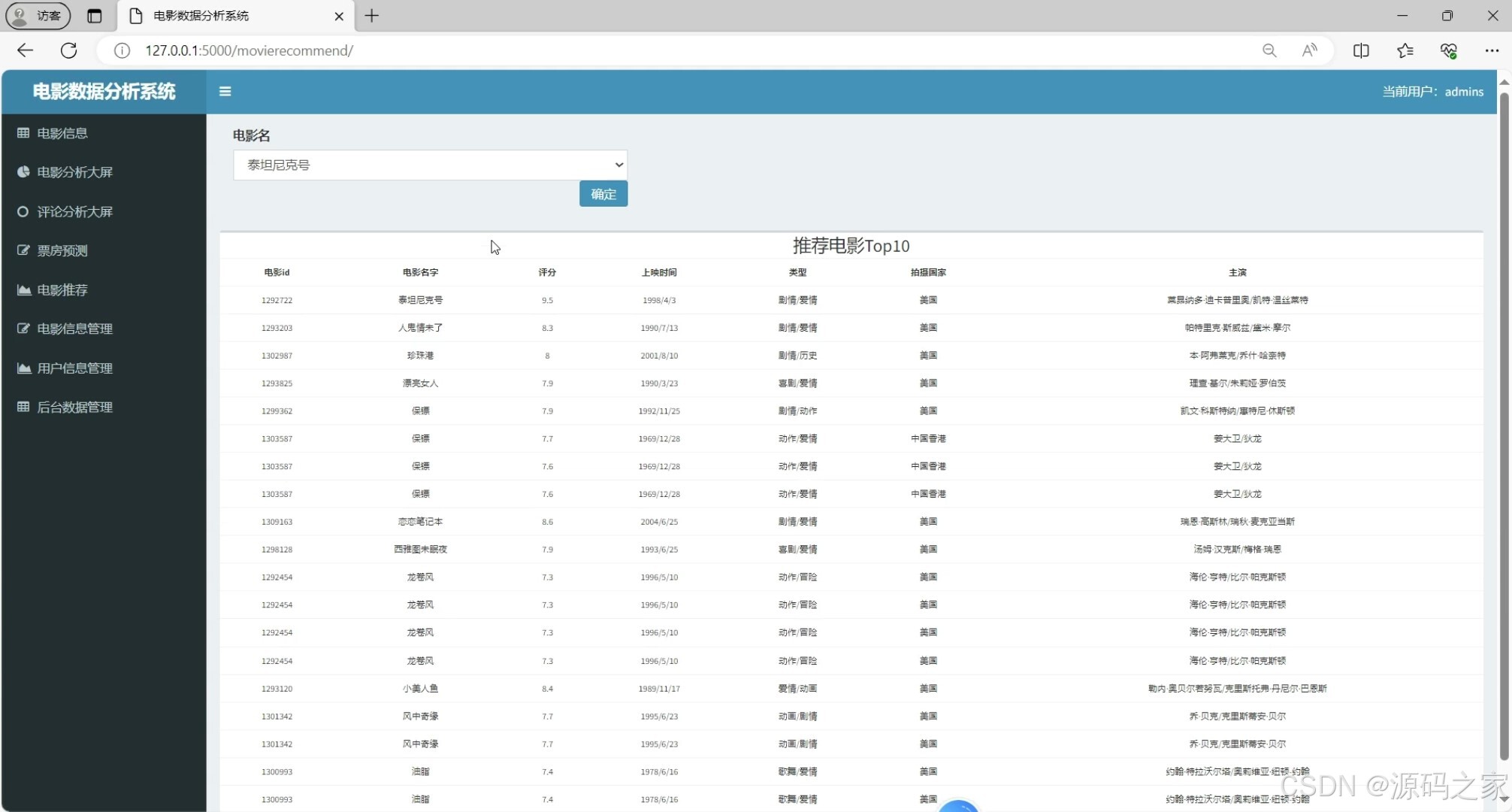
(5)电影推荐
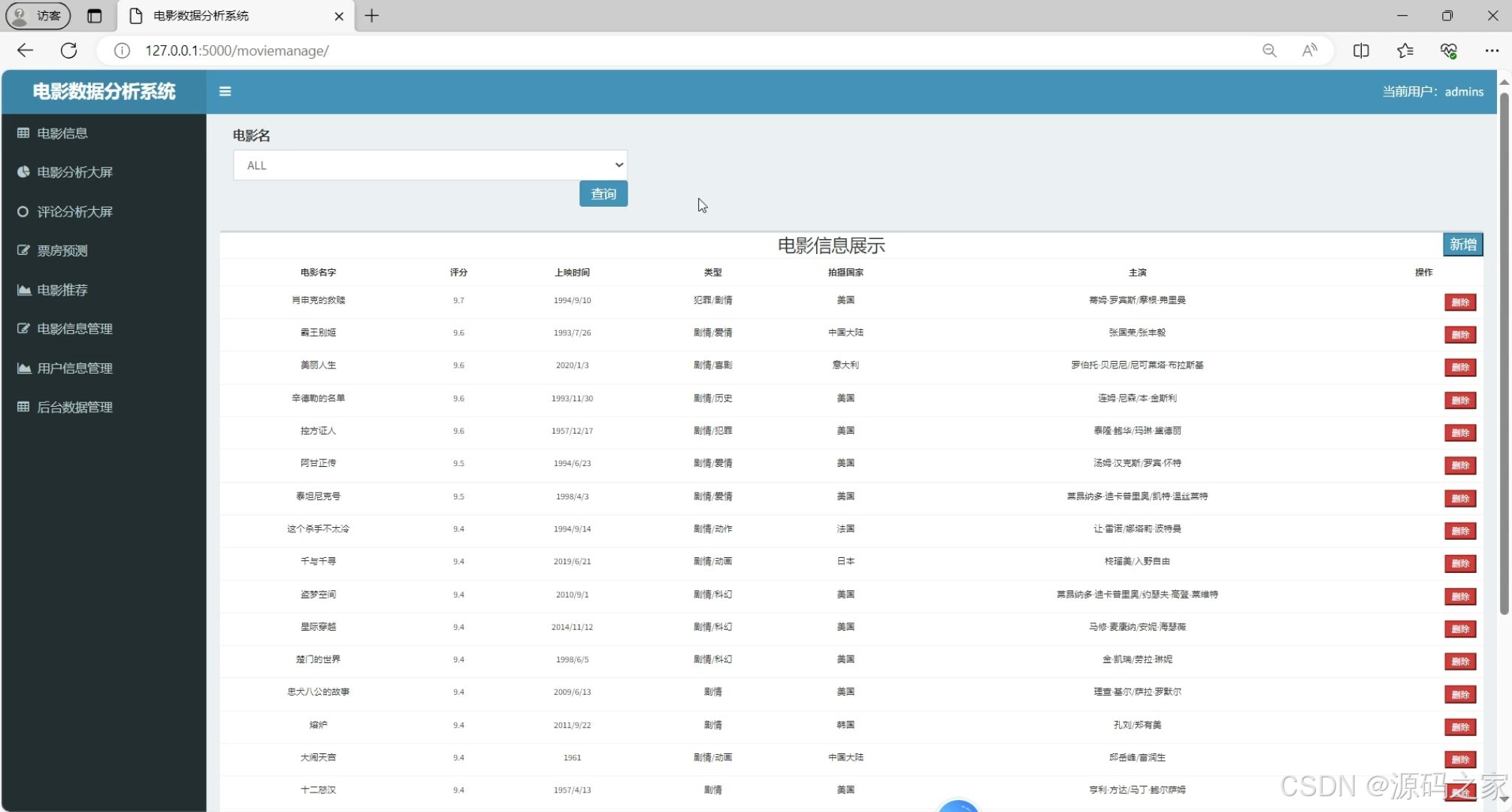
(6)电影信息管理
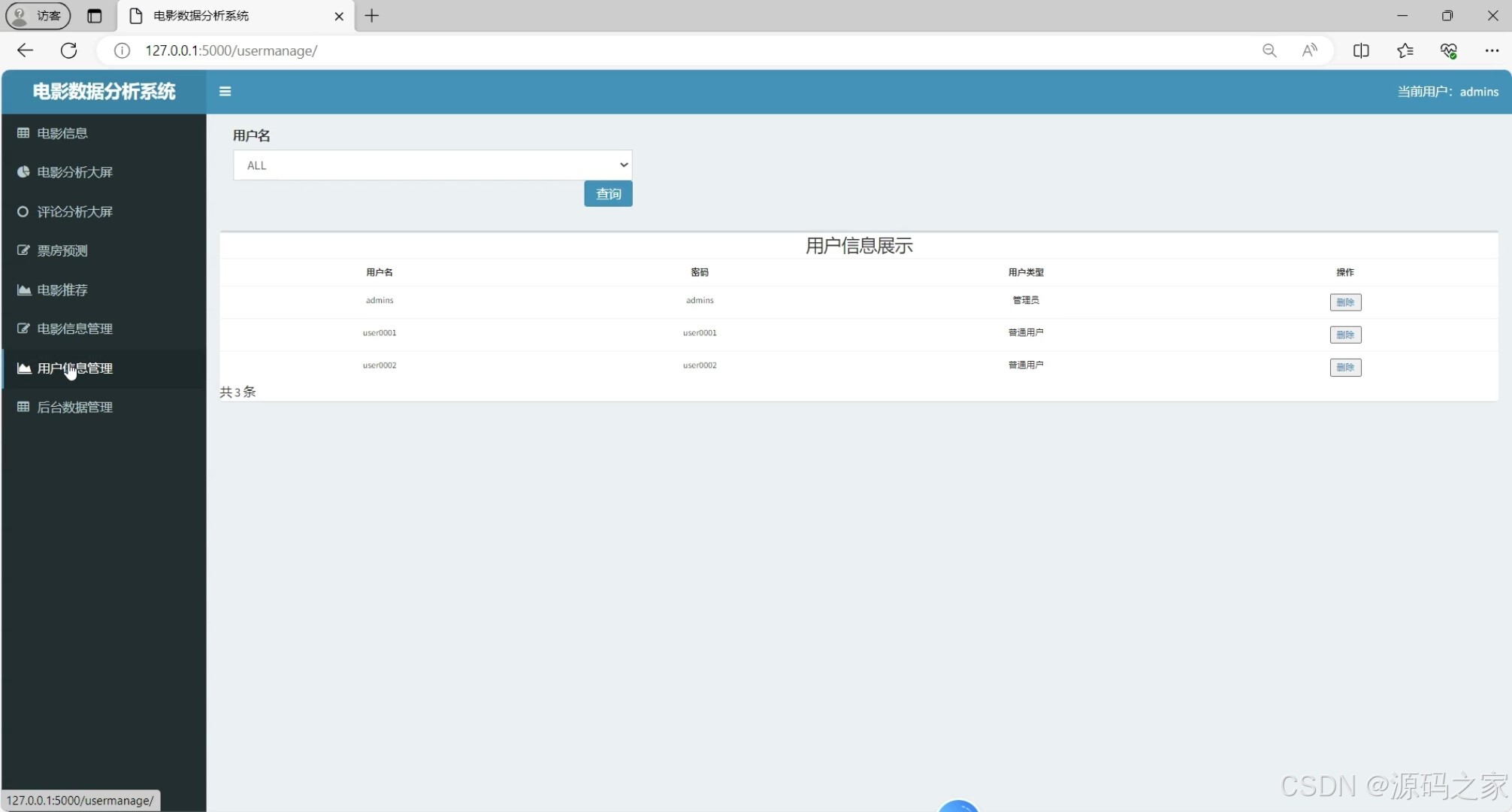
(7)用户信息管理
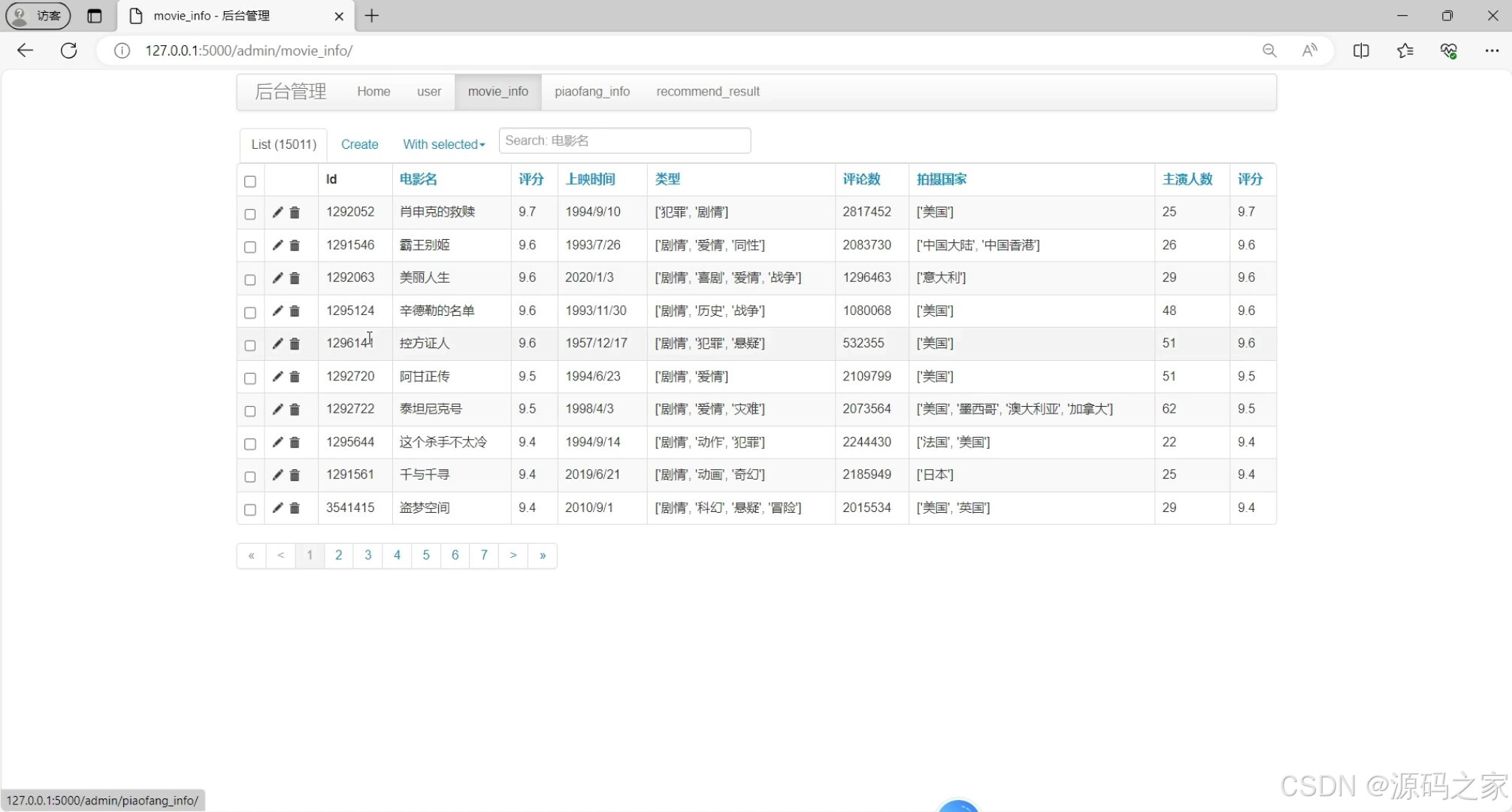
(8)后台数据管理
(9)注册登录
3、项目说明
本项目是基于Python+Flask框架+MySQL数据库开发的电影推荐与票房预测系统,整合requests爬虫、Echarts可视化及机器学习算法,覆盖“数据采集-分析-预测-推荐-管理”全流程,旨在解决电影行业用户选片难、票房预测不准、数据利用低效的问题。
(1)数据采集与存储
系统通过requests爬虫技术定向采集豆瓣等平台的电影数据(含名称、类型、评分、评论、票房相关信息),经数据清洗(过滤无效数据、补全缺失值)后存储至MySQL数据库,为各功能模块提供结构化数据支撑;同时数据库兼顾用户信息(账号、偏好)、评论数据的存储,保障数据完整性与查询效率。
(2)核心算法模块实现
① 电影票房预测模块(Stacking集成学习)
采用Stacking模型融合4个机器学习算法(决策树、Lasso、随机森林、GDBT梯度提升树):以4个基础算法作为第一层模型,对历史票房数据(如电影类型、评分、上映档期、演员热度等特征)进行训练,将其输出结果作为第二层模型的输入,通过集成优化降低单一算法的偏差与方差,最终提升票房预测精度,为电影行业提供可靠的票房参考。
② 电影推荐模块(KNNWithZScore算法)
基于Surprise库实现KNNWithZScore推荐算法(核心代码位于app/home/wals.py):首先对用户电影评分数据进行训练,通过交叉验证计算RMSE(均方根误差)与MAE(平均绝对误差)指标;然后测试不同K值(近邻数量)对模型的影响,绘制“平均RMSE/MAE随K值变化曲线图”,筛选出最优K值;最后基于最优模型,根据用户历史评分与相似用户偏好,生成个性化电影推荐列表,解决传统推荐“泛化不准”的问题。
(3)数据可视化展示
借助Echarts可视化大屏实现多维度数据呈现:
- 电影数据可视化大屏:展示电影总量、评分分布、类型占比等核心指标;
- 评论数据可视化大屏:通过词云、折线图等呈现用户评论情感倾向、热门评论关键词;
- 辅助图表(如电影数据列表、分类统计):帮助用户快速把握电影信息,管理员直观了解数据动态。
(4)用户角色与功能模块
系统支持三级角色登录(普通用户、管理员、后台管理员),功能模块按需分配:
- 普通用户:通过注册登录使用电影浏览、评论查看、个性化推荐接收、个人信息维护功能,降低选片难度;
- 管理员:负责电影信息管理(增删改查电影数据)、用户信息管理(维护用户账号),保障数据有序性;
- 后台管理员:监控爬虫任务、查看系统日志、管理推荐与预测模型参数,确保系统稳定运行。
整体而言,系统通过技术整合实现“算法精准性+功能完整性+操作便捷性”的统一,既满足用户个性化观影需求,又为电影行业提供数据驱动的决策工具,具备较强的技术深度与实际应用价值。
4、核心代码
import re
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.metrics import make_scorer, mean_squared_error
from sklearn.metrics import r2_score
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression as LR, Lasso
import joblib
import seaborn as sns
model_save_path = r'./app/dataset/testModel/'
if not os.path.exists(model_save_path):
os.makedirs(model_save_path)
data = pd.read_csv(r"./app/dataset/ana_result/piaofang_info.csv")
data = data.iloc[:, [2, 3, 4, 5, 7, 9, 10, 11]]
X = data.iloc[:, 0:7]
y = data.iloc[:, 7].apply(lambda x: x / 10000)
# 标签经过 log1p 转换,使其更偏向于正态分布
y = np.log1p(y)
# 数据集划分
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2, random_state=1)
oof_df = pd.DataFrame()
test_oof_df = pd.DataFrame()
def performance_metric(y_true, y_predict):
""" Calculates and returns the performance score between
true and predicted values based on the metric chosen. """
# 计算 'y_true' 与 'y_predict' 的r2值
score = r2_score(y_true, y_predict)
# 返回这一分数
return score
def fit_dtr_model(X, y):
cross_validator = KFold(n_splits=5)
regressor = DecisionTreeRegressor(random_state=1)
# Create a dictionary for the parameter 'max_depth' with a range from 1 to 10
params = {'max_depth': [i for i in range(1, 11)]}
# Transform 'performance_metric' into a scoring function using 'make_scorer'
scoring_fnc = make_scorer(performance_metric)
# Create the grid search cv object --> GridSearchCV()
grid = GridSearchCV(regressor, params, scoring=scoring_fnc, cv=cross_validator)
# Fit the grid search object to the data to compute the optimal model
grid = grid.fit(X, y)
dtr_max_depth = grid.best_estimator_.get_params()['max_depth']
# Return the optimal model after fitting the data
return dtr_max_depth
def fit_decision_tree_model_forcast():
# 进行决策树预测模型的训练
dtr_max_depth = fit_dtr_model(X, y)
dtr_regressor = DecisionTreeRegressor(max_depth=dtr_max_depth)
dtr_regressor.fit(X, y)
pred_y = dtr_regressor.predict(test_X)
test_oof_df['dtr'] = pred_y
r2_score = performance_metric(test_y, pred_y)
rmse_score = np.sqrt(mean_squared_error(pred_y, test_y))
print('决策树回归模型评价指标为:')
print("The R2 score is ", r2_score)
print('均方差', rmse_score)
joblib.dump(dtr_regressor, model_save_path + 'dtr_model.pkl')
return rmse_score
def fit_lasso_model_forcast():
# 进行Lasso预测模型的训练
lasso_regressor = Lasso()
lasso_regressor.fit(X, y)
pred_y = lasso_regressor.predict(test_X)
test_oof_df['lasso'] = pred_y
r2_score = performance_metric(test_y, pred_y)
rmse_score = np.sqrt(mean_squared_error(pred_y, test_y))
print('Lasso回归模型评价指标为:')
print("The R2 score is ", r2_score)
print('均方差', rmse_score)
joblib.dump(lasso_regressor, model_save_path + 'lasso_model.pkl')
return rmse_score
def fit_random_forest_regression_model():
rf_model = RandomForestRegressor()
rf_model.fit(X, y)
pred_y = rf_model.predict(test_X)
test_oof_df['rf'] = pred_y
r2_score = performance_metric(pred_y, test_y)
rmse_score = np.sqrt(mean_squared_error(pred_y, test_y))
print('随机森林模型评价指标为:')
print("The R2 score is ", r2_score)
print('均方差', rmse_score)
joblib.dump(rf_model, model_save_path + 'rf_model.pkl')
return rmse_score
def fit_gdbt_model():
gdbt_model = GradientBoostingRegressor()
gdbt_model.fit(X, y)
pred_y = gdbt_model.predict(test_X)
test_oof_df['gdbt'] = pred_y
r2_score = performance_metric(pred_y, test_y)
rmse_score = np.sqrt(mean_squared_error(pred_y, test_y))
print('GDBT模型评价指标为:')
print("The R2 score is ", r2_score)
print('均方差', rmse_score)
joblib.dump(gdbt_model, model_save_path + 'gdbt_model.pkl')
return rmse_score
def fit_stacking_model():
lr_model = LR()
lr_model.fit(test_oof_df, test_y)
pred_y = lr_model.predict(test_oof_df)
r2_score = performance_metric(pred_y, test_y)
rmse_score = np.sqrt(mean_squared_error(pred_y, test_y))
print('Staking模型评价指标为:')
print("The R2 score is ", r2_score)
print('均方差', rmse_score)
joblib.dump(lr_model, model_save_path + 'stacking_model.pkl')
return rmse_score
def forcast_piaofang(para):
para = pd.DataFrame(para)
# 加载决策树预测模型
dtr_model = joblib.load(model_save_path + 'dtr_model.pkl')
dtr_pred = dtr_model.predict(para)
print("决策树预测票房%s万" % np.expm1(dtr_pred[0]))
# 加载Lasso预测模型
lasso_model = joblib.load(model_save_path + 'lasso_model.pkl')
lasso_pred = lasso_model.predict(para)
print("Lasso预测票房%s万" % np.expm1(lasso_pred[0]))
# # 加载随机森林预测模型
rf_model = joblib.load(model_save_path + 'rf_model.pkl')
rf_pred = rf_model.predict(para)
print("随机森林预测票房%s万" % np.expm1(rf_pred[0]))
# 加载GDBT预测模型
gdbt_model = joblib.load(model_save_path + 'gdbt_model.pkl')
gdbt_pred = gdbt_model.predict(para)
print("GDBT预测票房%s万" % np.expm1(gdbt_pred[0]))
# return [dtr_pred, lr_pred]
return [[dtr_pred[0], lasso_pred[0], rf_pred[0], gdbt_pred[0]]]
核心代码块二:
# 用于训练多个模型并计算它们的 RMSE(均方根误差)分数,并将结果保存到一个 CSV 文件中。
def train_model():
dtr_rmse = fit_decision_tree_model_forcast() # 决策树
lasso_rmse = fit_lasso_model_forcast() # Lasso
rf_rmse = fit_random_forest_regression_model() # 随机森林
gdbt_rmse = fit_gdbt_model() # GDBT
lr_rmse = fit_stacking_model() # 将返回的堆叠模型的 RMSE 分数赋值给变量lr_rmse
rmse_result = pd.DataFrame(index=["决策树", "Lasso", "随机森林", "GDBT", "Stacking"])
rmse_result['rmse_score'] = [dtr_rmse, lasso_rmse, rf_rmse, gdbt_rmse, lr_rmse] # 将之前计算得到的各个模型的 RMSE 分数添加到rmse_result数据帧中的rmse_score列中。
rmse_result.to_csv("../dataset/testModel/rmse_result.csv", encoding='utf-8', index=False) #将rmse_result数据帧保存为一个 CSV 文件
def test_model():
# 1965, 12, 8.9, 1, 3, 29, 132
# 1295124,辛德勒的名单,1993,11,9.6,3,"['剧情', '历史', '战争']",1,['美国'],48,195,322161245
# 10876425,印式英语,2023,02,8.1,3,"['剧情', '喜剧', '家庭']",1,['印度'],13,133,10299150
# 35267208,流浪地球2,2023,01,8.4,3,"['科幻', '冒险', '灾难']",1,['中国大陆'],50,173,8394962
test_para = pd.DataFrame([[2022, 2, 8.4, 3, 1, 50, 173]])
test_piaofang = 8394962 / 10000
print("真实票房%s万" % test_piaofang)
pred_list = forcast_piaofang(test_para)
# 加载线性回归预测模型
stacking_model = joblib.load(model_save_path + 'stacking_model.pkl')
piaofang = stacking_model.predict(pred_list)[0]
piaofang = round(np.expm1(piaofang), 2)
print("Stacking预测票房%s万" % piaofang)
return piaofang
def forcast(para_list):
# 根据传入的参数列表,进行票房预测
pred_list = forcast_piaofang(para_list)
# 加载线性回归预测模型
stacking_model = joblib.load(model_save_path + 'stacking_model.pkl')
piaofang = stacking_model.predict(pred_list)[0]
piaofang = round(np.expm1(piaofang), 2)
print("Stacking预测票房%s万" % piaofang)
return "预测票房%s万(美元)" % piaofang
def vis_relation(x1, y1, name1):
fig = plt.figure(1, figsize=(9, 5))
# plt.plot([0,400000000],[0,400000000],c="green")
plt.scatter(x1, y1, c=['green'], marker='o')
plt.grid()
plt.xlabel("piaofang", fontsize=10)
plt.ylabel(name1, fontsize=10)
plt.title("Link between piaofang and %s" %name1, fontsize=10)
plt.savefig('../dataset/pictures/piaofang_%s.png' %name1)
plt.close()
# 分析票房预测使用的所有属性与票房之间的关系并绘制散点图,分析所有属性之间的相关度绘制热力图
def ana_columns():
year_list = list(data.iloc[:, 0])
month_list = list(data.iloc[:, 1])
rating_list = list(data.iloc[:, 2])
movie_type_count_list = list(data.iloc[:, 3])
country_count_list = list(data.iloc[:, 4])
actor_count_list = list(data.iloc[:, 5])
runtime_list = list(data.iloc[:, 6])
piaofang_list = list(data.iloc[:, 7])
vis_relation(piaofang_list, year_list, 'year')
vis_relation(piaofang_list, month_list, 'month')
vis_relation(piaofang_list, rating_list, 'rating')
vis_relation(piaofang_list, movie_type_count_list, 'movie_type_count')
vis_relation(piaofang_list, country_count_list, 'country_count')
vis_relation(piaofang_list, actor_count_list, 'actor_count')
vis_relation(piaofang_list, runtime_list, 'runtime')
# 相关关系可视化
col = ['year', 'month', 'rating', 'movie_type_count', 'country_count', 'actor_count', 'runtime', 'piaofang']
plt.subplots(figsize=(14, 10))
corr = data.corr()
print(corr)
corr.to_csv("../dataset/ana_result/piaofang_info_corr.csv", encoding='utf-8')
sns.heatmap(corr, xticklabels=col, yticklabels=col, linewidths=.5, cmap="Reds")
plt.savefig('../dataset/pictures/corr.png')
if __name__ == '__main__':
# 四个机器学习算法构建票房预测模型,然后Stacking集成所有的算法模型,构建最终的票房预测模型
train_model()
# 模型测试
piaofang = test_model()
# 分析票房预测使用的所有属性与票房之间的关系并绘制散点图,分析所有属性之间的相关度绘制热力图
ana_columns()
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









