







博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
- 技术栈:Python语言、Flask框架、MySQL数据库、requests爬虫技术、Echarts可视化、豆瓣电影数据(核心流程:爬虫采集→数据清洗→可视化展示)
- 这个项目的研究背景:当前豆瓣电影平台聚集海量电影数据(含制片地区、类型、评分、评论人数等),但数据以分散形式存在,人工采集与整理效率极低,且缺乏直观的可视化呈现——用户难以快速把握“不同地区电影占比”“年份产量趋势”“评分与评论人数关联”等核心信息,导致电影数据的价值无法有效发挥,亟需一套“从数据获取到可视化分析”的一体化系统解决这些痛点。
- 这个项目的研究意义:技术层面,通过requests爬虫实现豆瓣电影数据高效采集,借助MySQL保障数据结构化存储,依托Echarts实现多维度可视化,Flask框架搭建轻量稳定的Web交互环境,解决传统数据处理“散、慢、难展示”的问题;用户层面,为电影爱好者、研究者提供直观的数据分析结果(如地区分布、类型趋势),降低数据理解门槛;行业层面,为电影市场分析提供便捷工具,助力快速洞察市场动态,具备实际应用价值。
2、项目界面
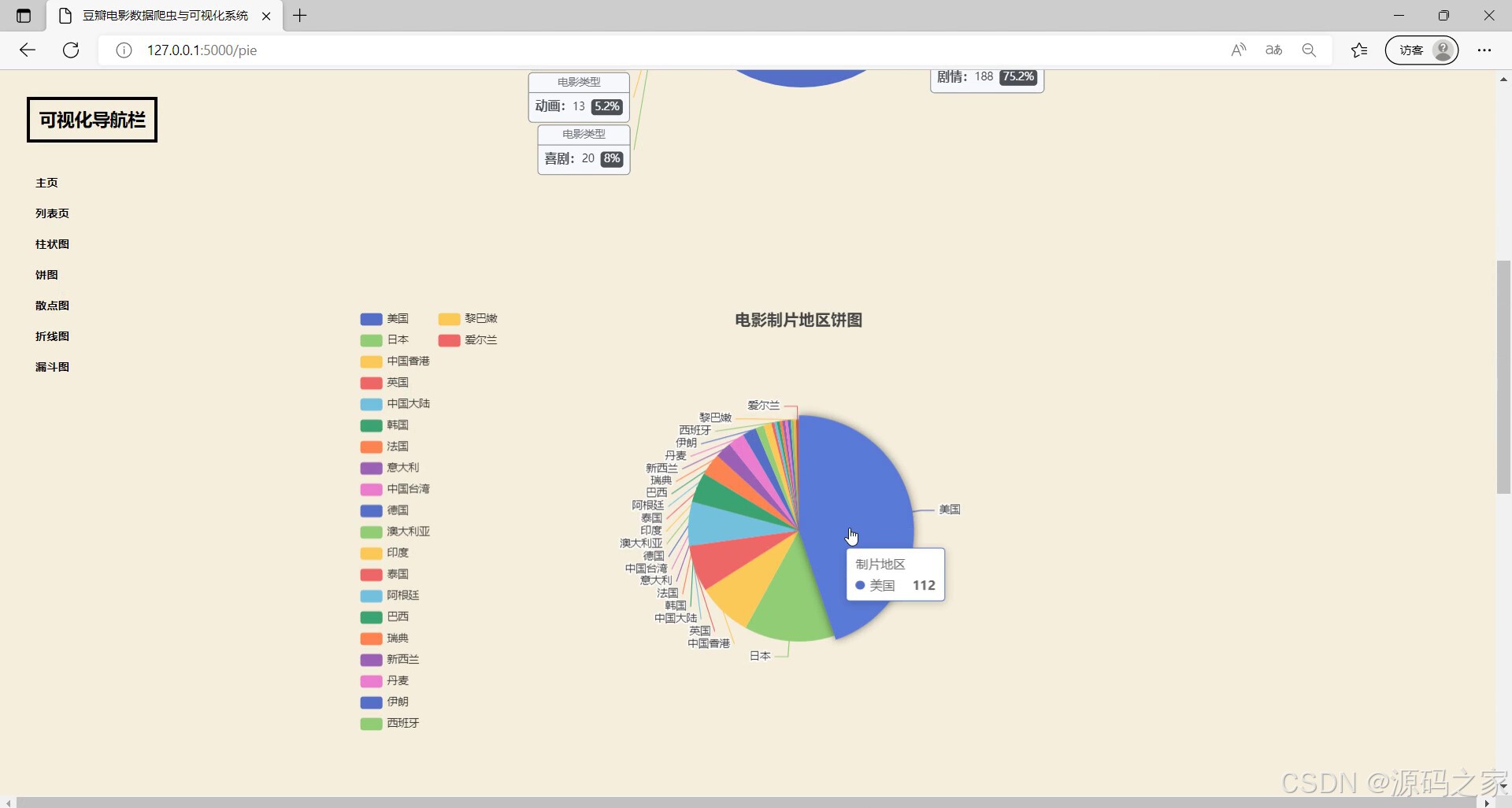
(1)电影制片地区饼图分析
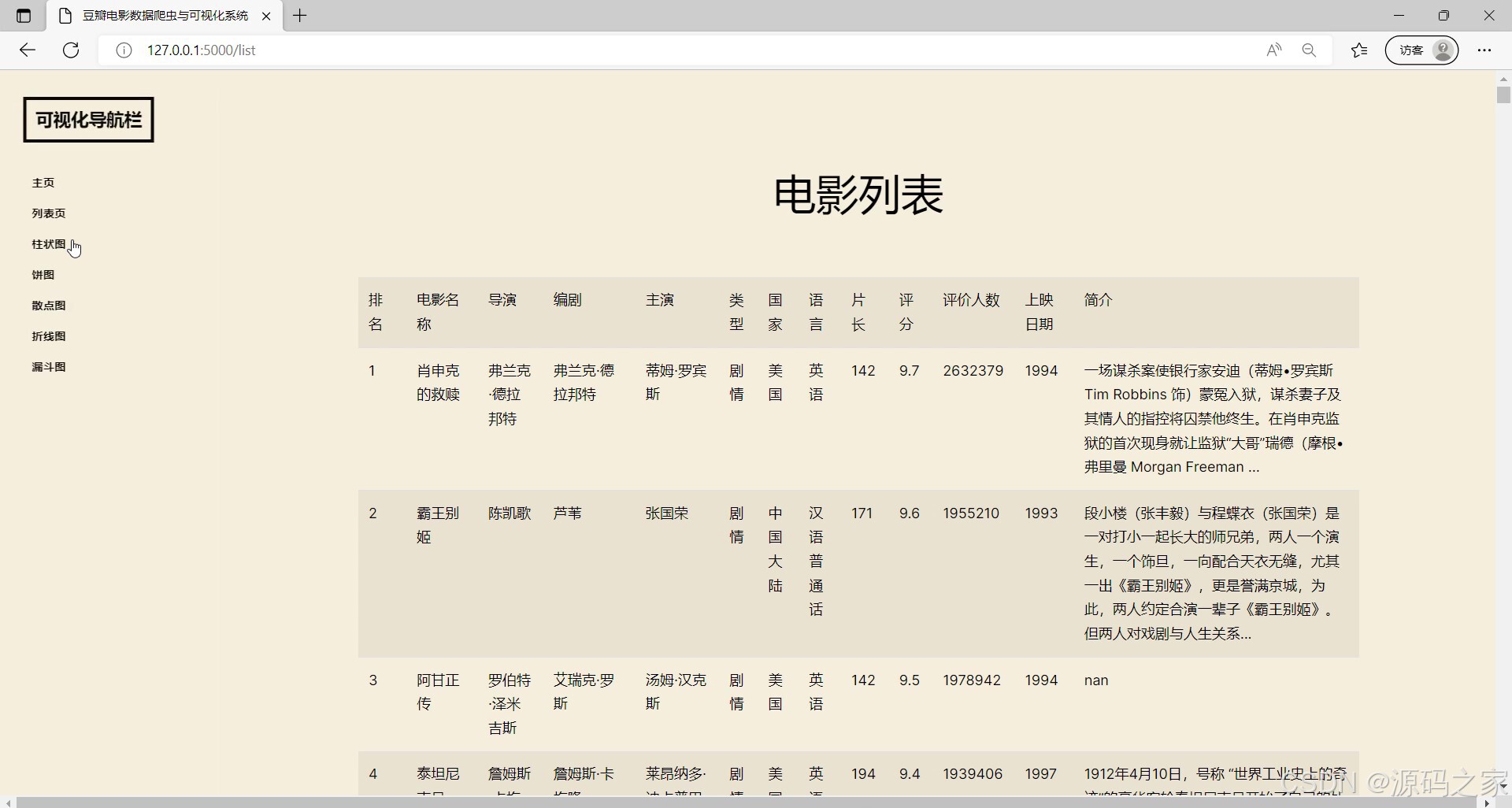
(2)电影数据信息
(3)首页

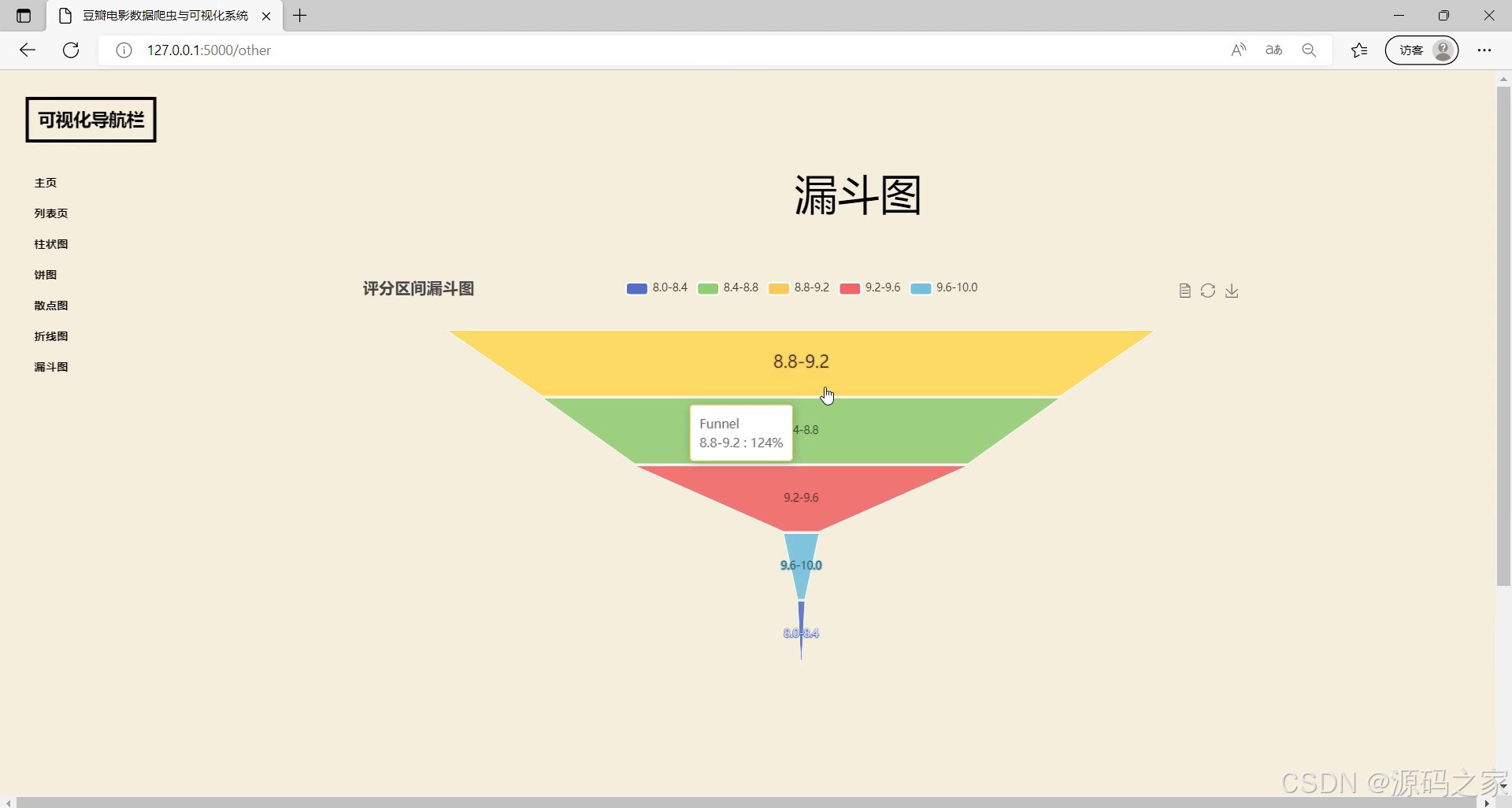
(4)电影数据漏斗图分析
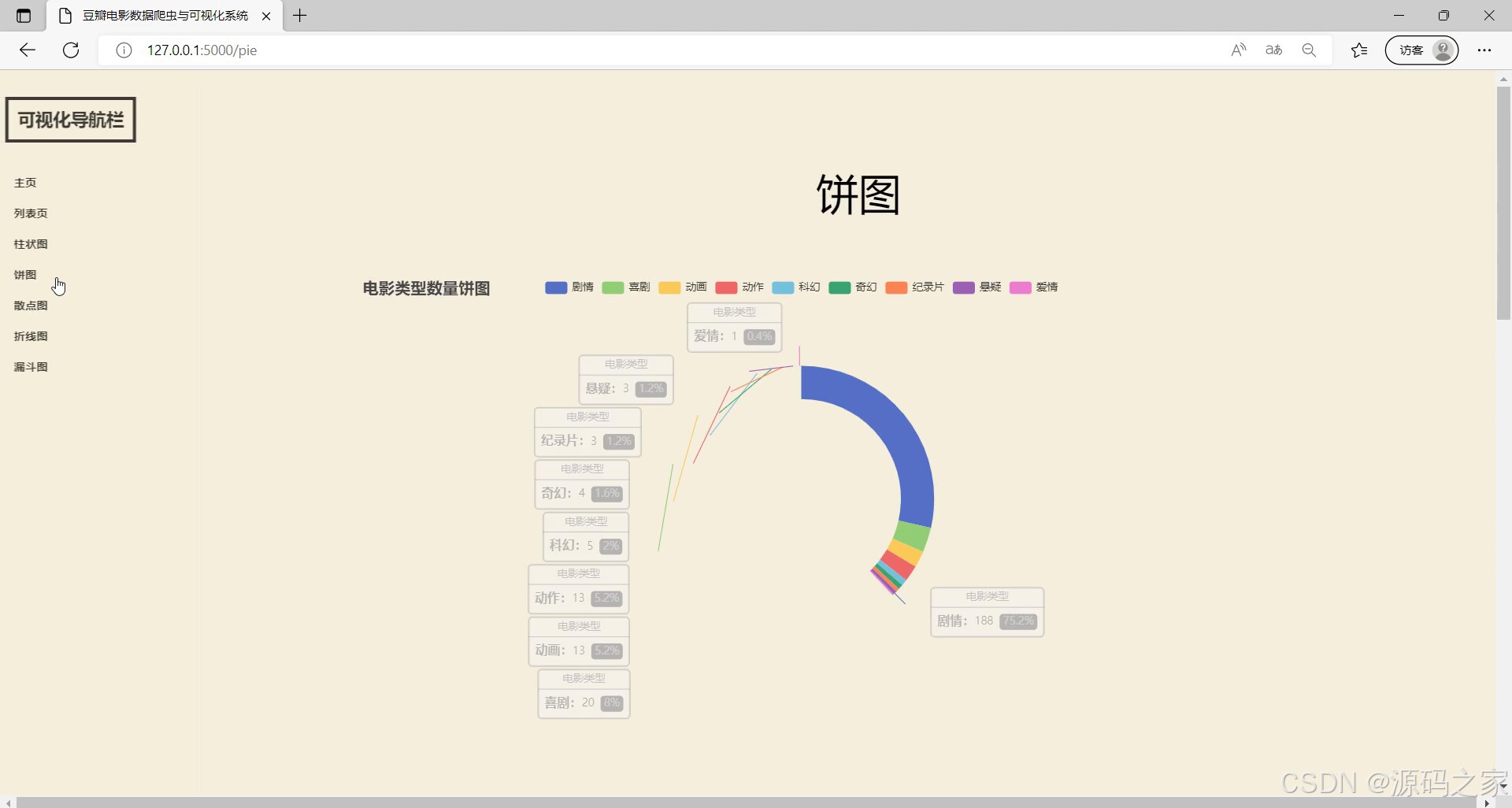
(5)饼图分析
(6)电影类型数据柱状图
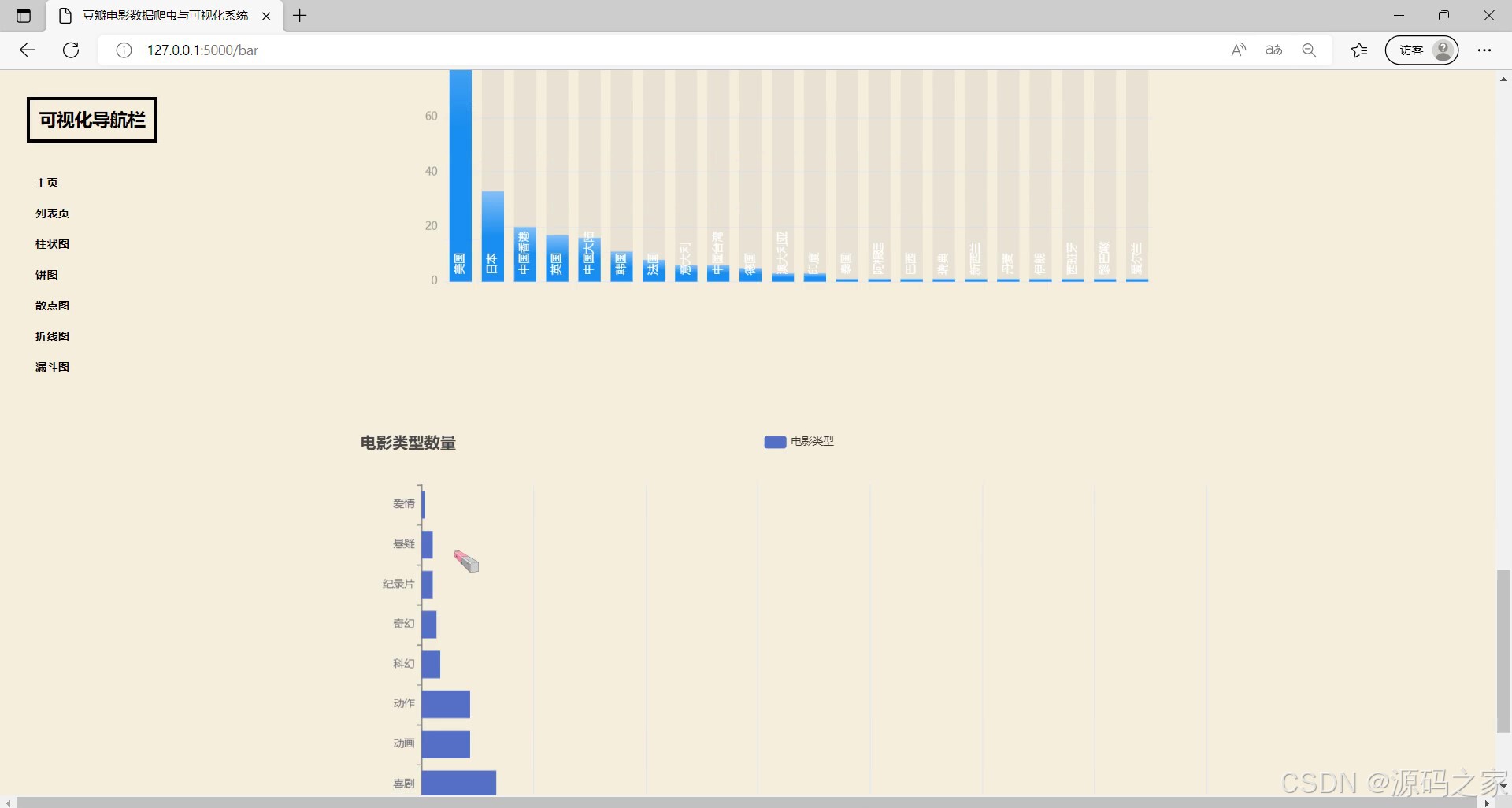
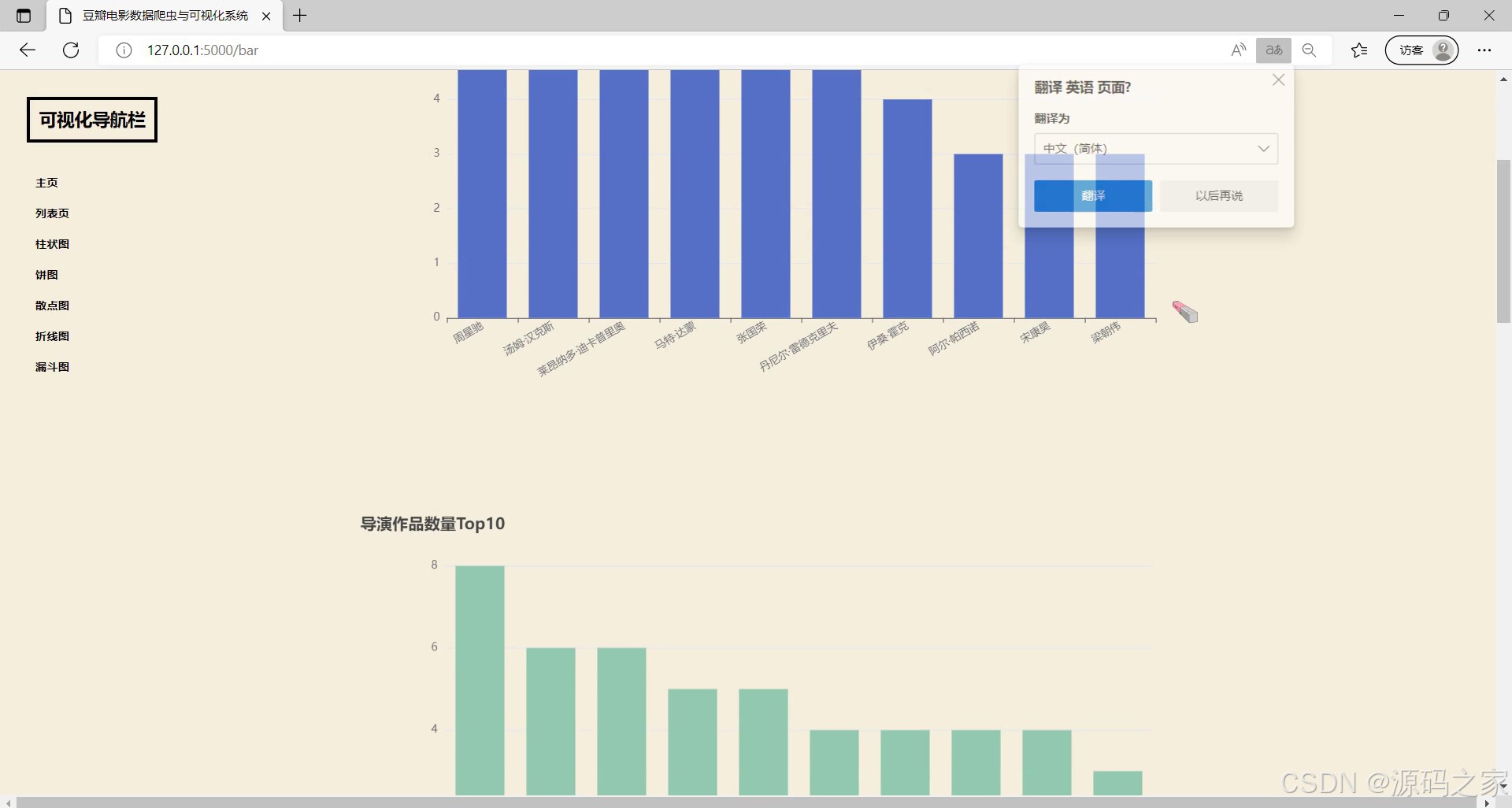
(7)导演作品柱状图分析
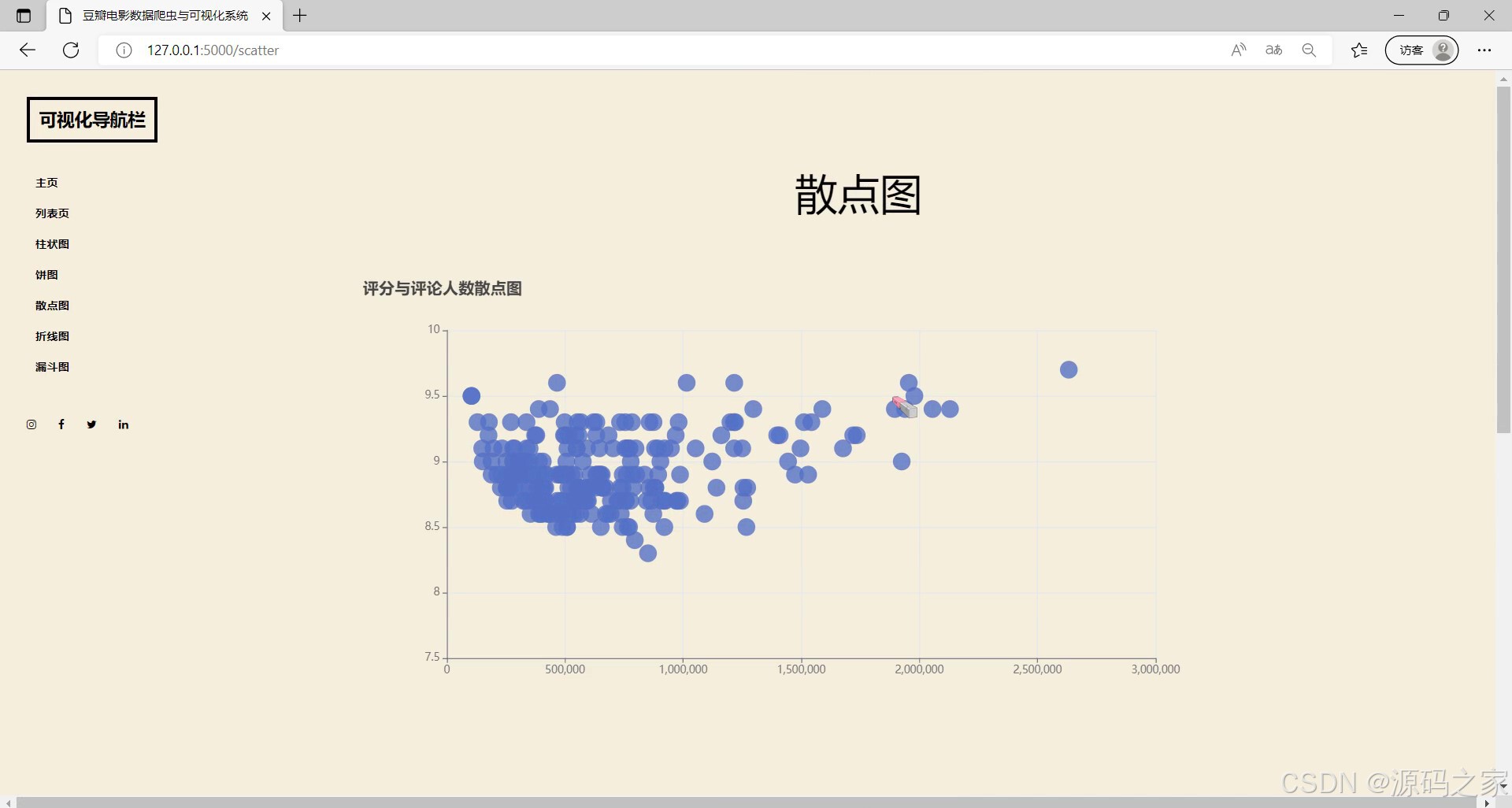
(8)评分与评论人数散点图
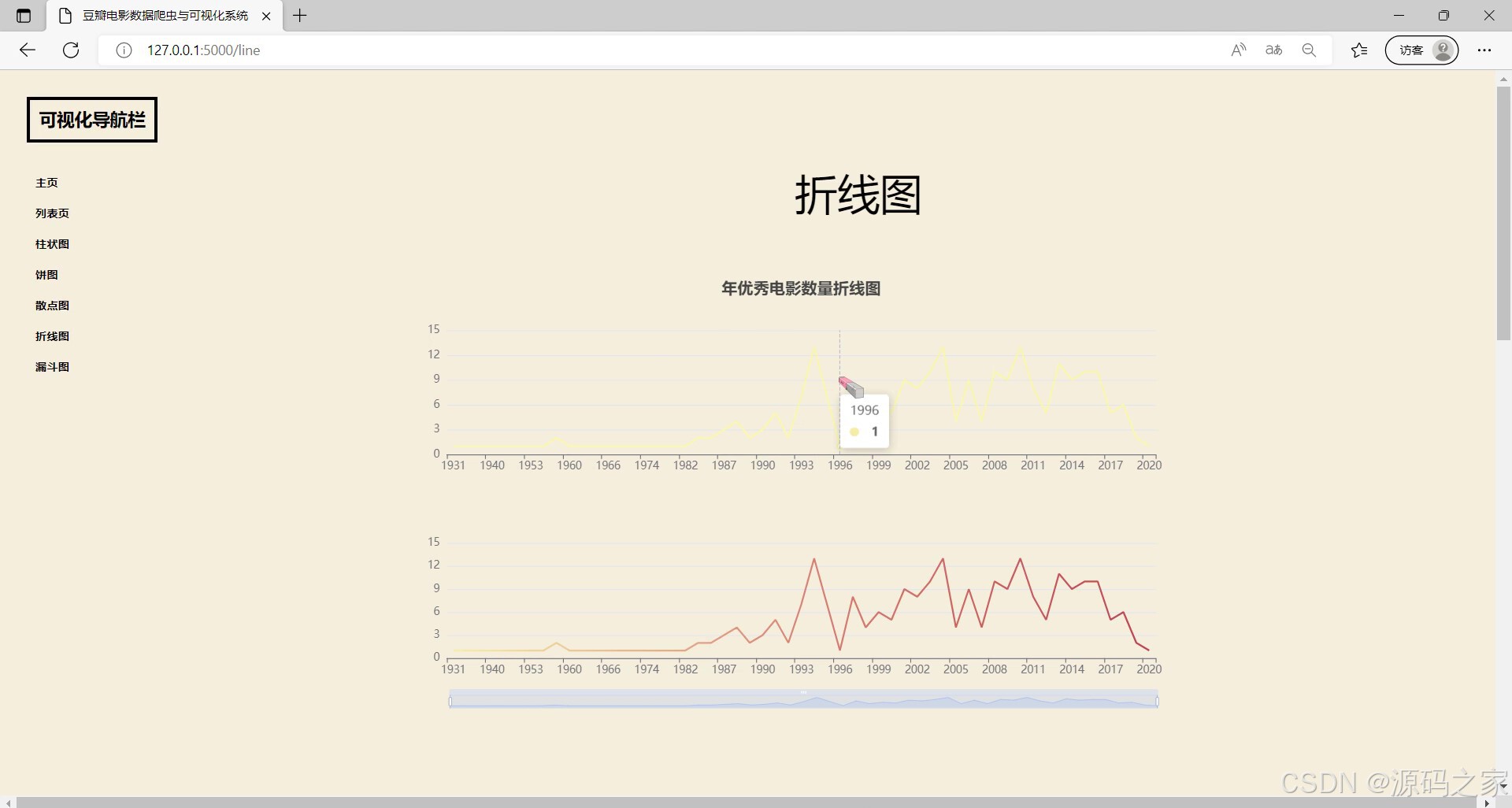
(9)每年电影数量折线图
(10)数据采集页面
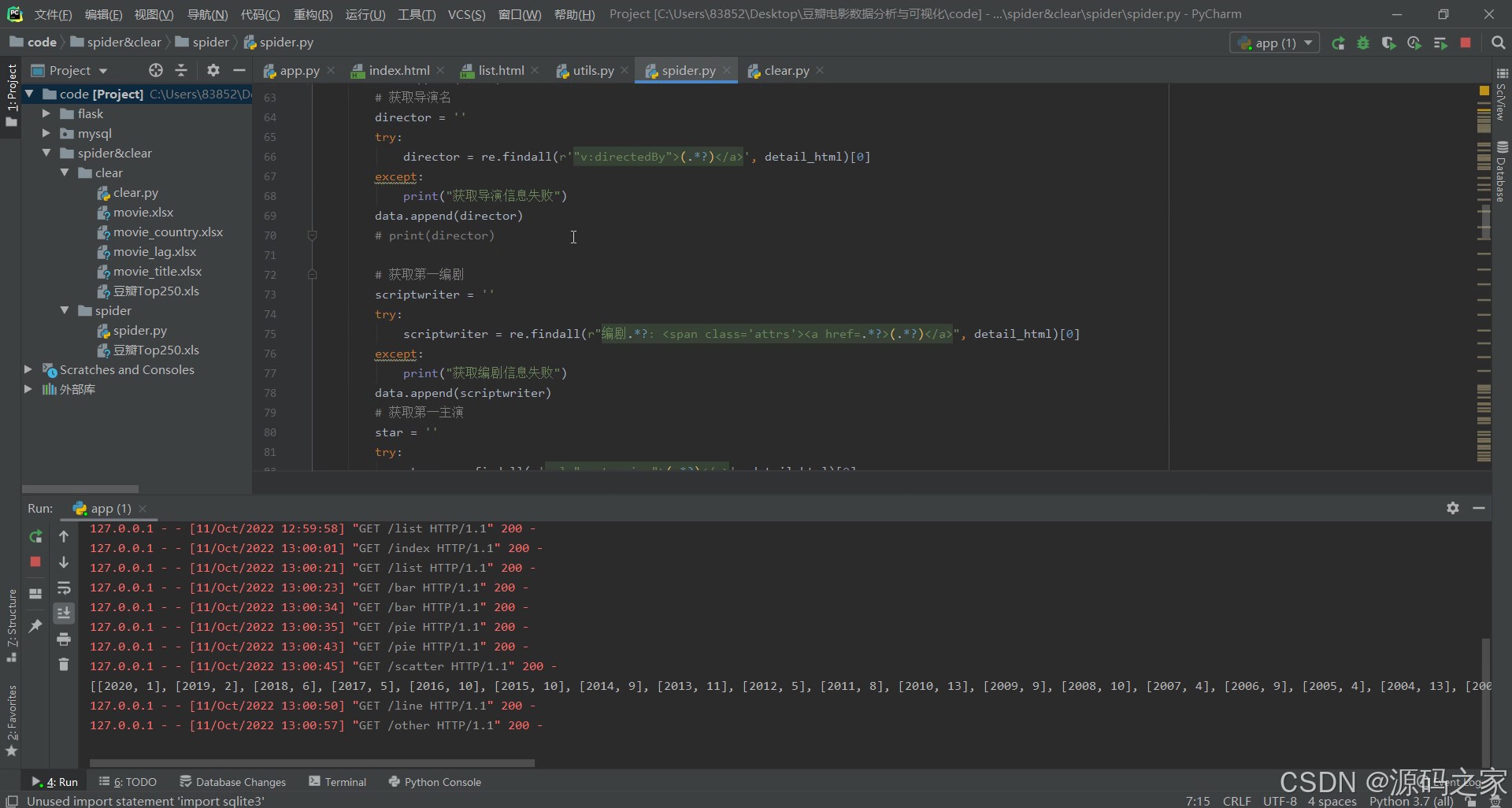
3、项目说明
本项目是基于Python语言开发的豆瓣电影数据可视化分析系统,以Flask为Web框架、MySQL为数据存储载体、requests为爬虫工具、Echarts为可视化引擎,核心实现“豆瓣电影数据采集→清洗→存储→多维度可视化分析”的完整流程,旨在解决电影数据分散、分析低效、展示不直观的问题。
(1)数据采集与预处理
系统通过requests爬虫技术定向采集豆瓣电影平台数据:首先分析豆瓣电影页面结构,编写爬虫逻辑抓取关键信息(含电影名称、制片地区、类型、评分、评论人数、导演、上映年份等);采集到的原始数据需经过清洗处理——过滤无效数据(如缺失核心字段的电影记录)、去重(排除重复抓取的条目)、格式标准化(统一日期、评分等字段格式),确保数据质量;最终将清洗后的结构化数据存储至MySQL数据库,为后续可视化分析提供稳定、可靠的数据源,同时支持通过“数据采集页面”手动触发爬虫任务,实时更新数据库中的电影数据,保障信息时效性。
(2)数据可视化分析(Echarts核心应用)
依托Echarts可视化工具,系统将MySQL中的电影数据转化为多种直观图表,覆盖多维度分析需求:
- 饼图分析:含“电影制片地区饼图”与通用饼图,分别展示不同地区电影的数量占比(如国产、欧美、日韩电影占比)、特定维度分布(如各评分区间电影占比),帮助快速把握整体结构;
- 柱状图分析:包括“电影类型数据柱状图”(对比不同类型电影的数量/平均评分)、“导演作品柱状图”(统计热门导演的作品数量),清晰呈现类别间差异;
- 折线图分析:“每年电影数量折线图”直观展示历年电影产量变化趋势,助力洞察行业发展动态;
- 散点图分析:“评分与评论人数散点图”探索两者关联关系(如高评分电影是否伴随高评论量),挖掘数据背后的潜在规律;
- 漏斗图分析:“电影数据漏斗图”可展示电影从“采集条目→有效数据→高评分(如8分以上)条目”的筛选过程,呈现数据层层筛选后的核心结果。
(3)系统架构与功能模块
- 架构设计:采用Flask轻量级Web框架搭建前后端交互桥梁——后端负责爬虫调度、数据读写(与MySQL交互)、接口开发,向前端提供标准化数据;前端通过HTML/CSS构建界面(如首页、电影数据信息页),调用Echarts接口加载并渲染图表,实现数据可视化展示;
- 核心功能模块:
- 首页:作为系统入口,汇总核心可视化图表与功能入口,方便用户快速定位所需分析维度;
- 电影数据信息页:展示单部电影的详细信息(含基本属性、评分、导演等),支持查看具体条目详情;
- 数据采集页面:提供爬虫任务触发按钮,支持用户手动更新数据,灵活应对豆瓣电影数据更新需求;
- 多维度可视化页:按“地区、类型、年份、导演”等维度分类展示图表,用户可按需查看对应分析结果。
(4)用户价值与应用场景
系统面向两类核心用户:
- 普通电影爱好者:可通过图表快速了解电影市场趋势(如近年产量、热门类型)、筛选高价值电影(如高评分+高评论量作品),降低选片时间成本;
- 电影研究者/从业者:可借助多维度数据(如地区分布、类型趋势)辅助市场分析,为内容创作、发行策略制定提供数据参考。
整体而言,系统通过技术整合实现了电影数据从“无序采集”到“有序分析”再到“直观展示”的闭环,操作简洁、分析维度全面,兼具实用性与易用性,为电影数据的高效利用提供了可靠解决方案。
4、核心代码
from bs4 import BeautifulSoup
import re
import urllib.request,urllib.error
import xlwt
import time
import random
import sqlite3
def main():
baseurl = "https://movie.douban.com/top250?start="
#1.爬取网页
datalist = getData(baseurl)
savepath='豆瓣Top250.xls'
saveData(datalist,savepath)
# askURL(baseurl)
#爬取网页
def getData(baseurl):
#存储详情页链接
href_list =[]
#存储所有电影的信息
datalist = []
'''
0*25=0
1*25=25
...
'''
#调用获取页面信息的函数 10次
for i in range(0,10):
time.sleep(random.random() * 5)
url = baseurl + str(i*25)
#保存网页源码
html = askURL(url)
#2.逐一解析数据
bs = BeautifulSoup(html,'html.parser')
#找到所有的class=item的div,并保存到列表中
item_list = bs.find_all('div',class_='item') #查找符合要求的字符串
for item in item_list:
#正则表达式是字符串匹配,需要把item转化为字符串
item = str(item)
#提取详情页链接
detail_href = re.findall(r'<a href="(.*?)">',item)[0]
# print(detail_href)
href_list.append(detail_href)
# print(href_list)
# print(item)
for href in href_list:
time.sleep(random.random() * 5)
#获取详情页源码
detail_html = askURL(href)
# print(detail_html)
#保存一部电影的所有信息
data = []
# 获取片名
title = ''
try:
title = re.findall(r'"v:itemreviewed">(.*?)</span>', detail_html)[0]
except:
print("获取片名失败")
data.append(title)
# 获取导演名
director = ''
try:
director = re.findall(r'"v:directedBy">(.*?)</a>', detail_html)[0]
except:
print("获取导演信息失败")
data.append(director)
# print(director)
# 获取第一编剧
scriptwriter = ''
try:
scriptwriter = re.findall(r"编剧.*?: <span class='attrs'><a href=.*?>(.*?)</a>", detail_html)[0]
except:
print("获取编剧信息失败")
data.append(scriptwriter)
# 获取第一主演
star = ''
try:
star = re.findall(r'rel="v:starring">(.*?)</a>', detail_html)[0]
except:
print("获取演员信息失败")
data.append(star)
# print(star)
# 获取类型
filmtype = ''
try:
filmtype = re.findall(r'"v:genre">(.*?)</span>', detail_html)[0]
except:
print("获取电影类型信息失败")
data.append(filmtype)
# print(filmtype)
# 获得制片国家
country = ''
try:
country = re.findall(r'<span class="pl">制片国家/地区:</span> (.*?)<br/>', detail_html)[0]
except:
print("获取制片国家失败")
data.append(country)
# print(country)
# 获得语言
lag = ''
try:
lag = re.findall(r'<span class="pl">语言:</span> (.*?)<br/>', detail_html)[0]
except:
print("获取语言失败")
data.append(lag)
# print(lag)
# 获得片长
runtime = ''
try:
runtime = re.findall(r'<span property="v:runtime" content="(.*?)">', detail_html)[0]
except:
print("获取片长失败")
data.append(runtime)
# print(runtime)
# 获得评分 ----------------
score = ''
try:
score = re.findall(r'property="v:average">(.*?)</strong>', detail_html)[0]
except:
print("获取评分失败")
data.append(score)
# print(score)
# 获得评价人数
num = ''
try:
num = re.findall(r'<span property="v:votes">(.*?)</span>人评价', detail_html)[0]
except:
print("获取评价人数失败")
data.append(num)
# print(num)
year = ''
try:
year = re.findall(r'<span class="year">(.*?)</span>', detail_html)[0]
except:
print("获取上映日期失败")
data.append(year)
# print(year)
description = ''
try:
description = re.findall(r'<meta property="og:description" content="(.*?)" />', detail_html)[0]
except:
print("获取简介失败")
data.append(description)
# print(description)
image = ''
try:
image = re.findall(r'<meta property="og:image" content="(.*?)" />', detail_html)[0]
except:
print("获取图片失败")
data.append(image)
# print(image)
print(data)
datalist.append(data)
# print(datalist)
return datalist
#得到指定一个URL的网页内容
def askURL(url):
#模拟浏览器头部信息,向豆瓣服务器发送消息
# headers = {
# 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
# }
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36 Edg/103.0.1264.44'
}
content = ''
#请求对象
req = urllib.request.Request(url,headers = headers)
try:
#得到响应信息
response = urllib.request.urlopen(req)
#读取响应信息
content = response.read().decode('utf-8')
# print(content)
except urllib.error.URLError as e:
#hasattr 检查指定属性是否存在
if hasattr(e,'code'):
print(e.code)
if hasattr(e,'reason'):
print(e.reason)
return content
def saveData(datalist,savepath):
# 创建workbook对象
workbook = xlwt.Workbook(encoding='utf-8',style_compression=0)
# 创建工作表
worksheet = workbook.add_sheet('豆瓣电影Top250',cell_overwrite_ok=True)
col = ('电影名','导演','编剧','主演','类型','制片国家','语言','片长','评分','评价人数','上映日期','简介','图片')
for i in range(0,13):
# 写入表头
worksheet.write(0,i,col[i])
for i in range(0,250):
print('第%d条'%(i+1))
data = datalist[i]
for j in range(0,13):
worksheet.write(i+1, j, data[j])
workbook.save(savepath) #保存
if __name__ == '__main__':
main()
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式

🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

















 1095
1095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









