







毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈:
Python语言、Django框架、Echarts可视化、MySQL数据库、HTML
农产品销售分析可视化系统
农产品销售分析可视化系统是一个基于Python语言、Django框架、Echarts可视化库、MySQL数据库和HTML技术的综合性解决方案。该系统旨在帮助农业从业者、销售商和决策者更直观地理解农产品的销售情况,以便做出更明智的商业决策。
农产品销售分析可视化系统通过整合销售数据,运用先进的数据分析技术和可视化手段,为用户提供清晰、直观的销售分析报告。该系统利用Django框架搭建后端服务,通过MySQL数据库存储和管理销售数据,前端则采用HTML结合Echarts库进行数据可视化展示。
2、项目界面
(1)农产品价格区间分布
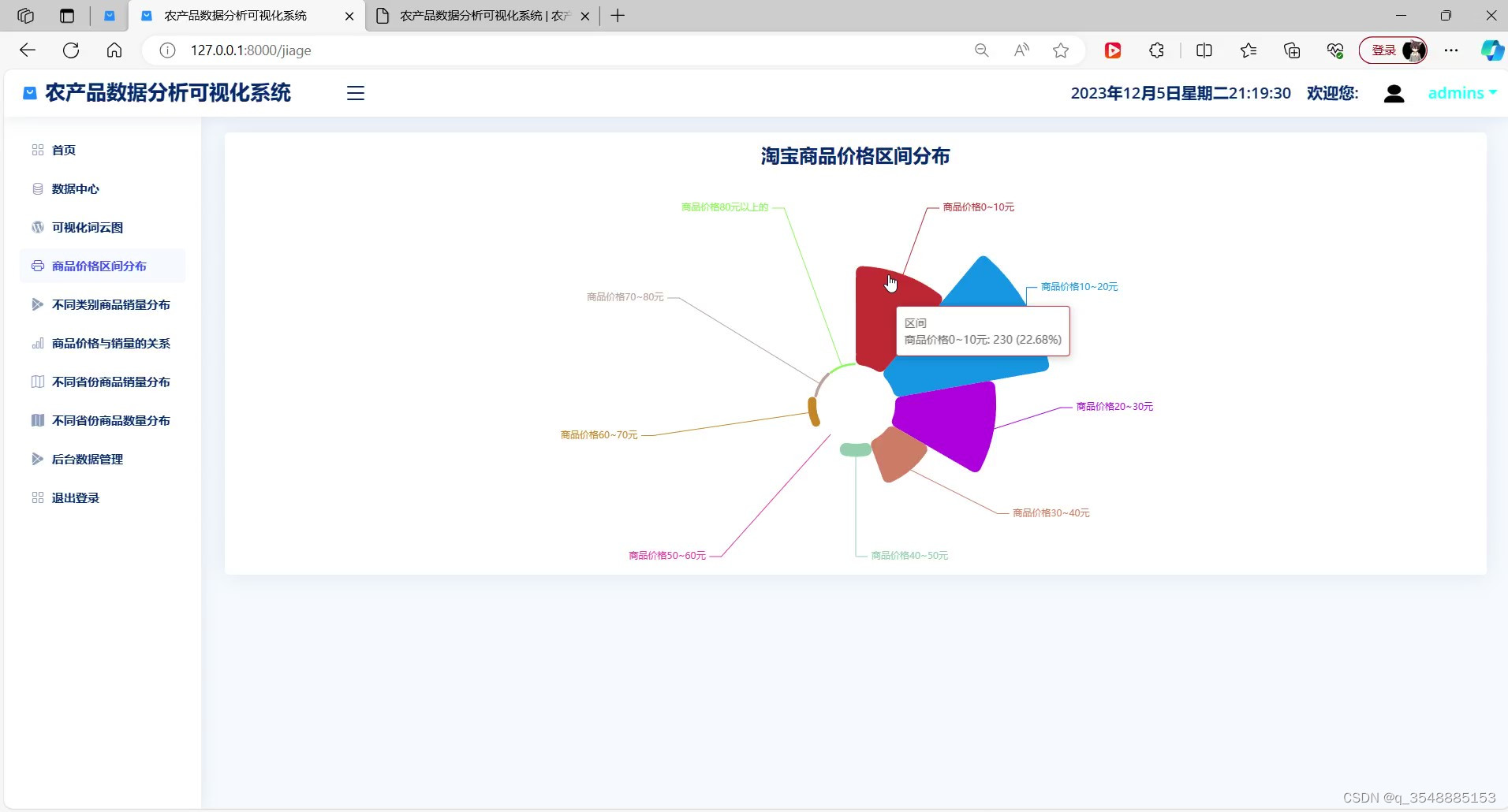
(2)农产品销量分布
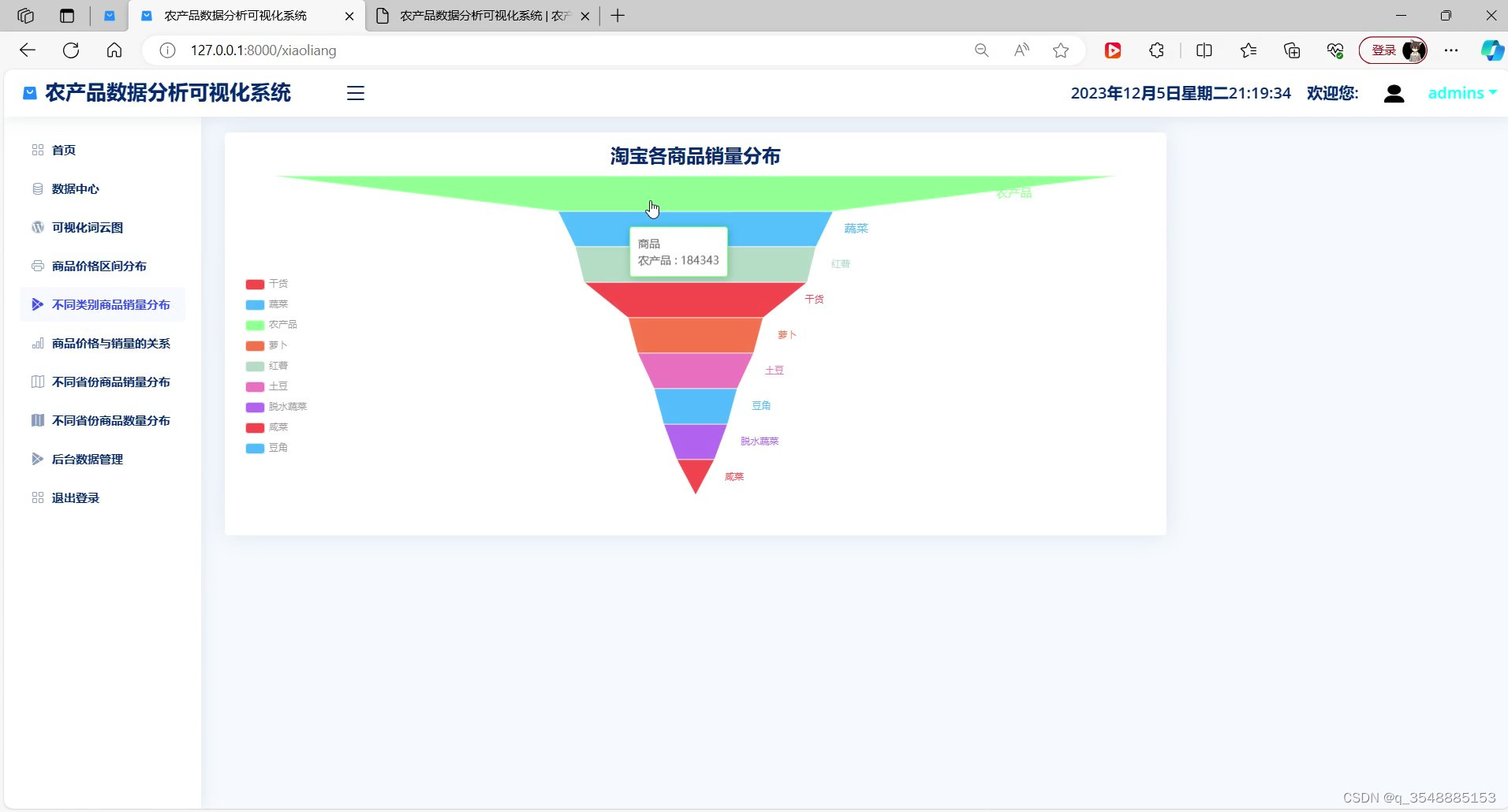
(3)农产品不同省份销量分布-----中国地图
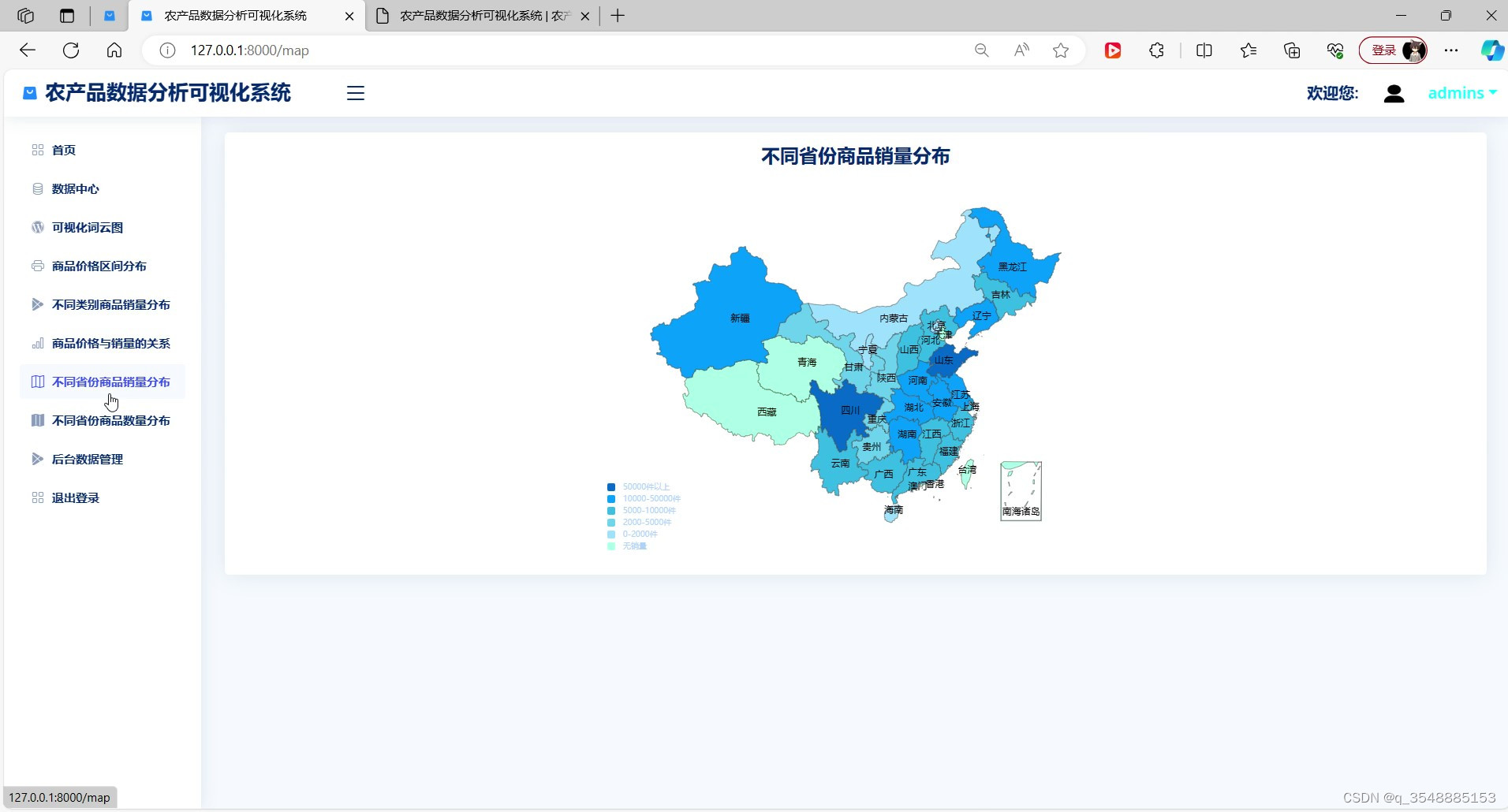
(4)农产品不同省份数量分布-----中国地图
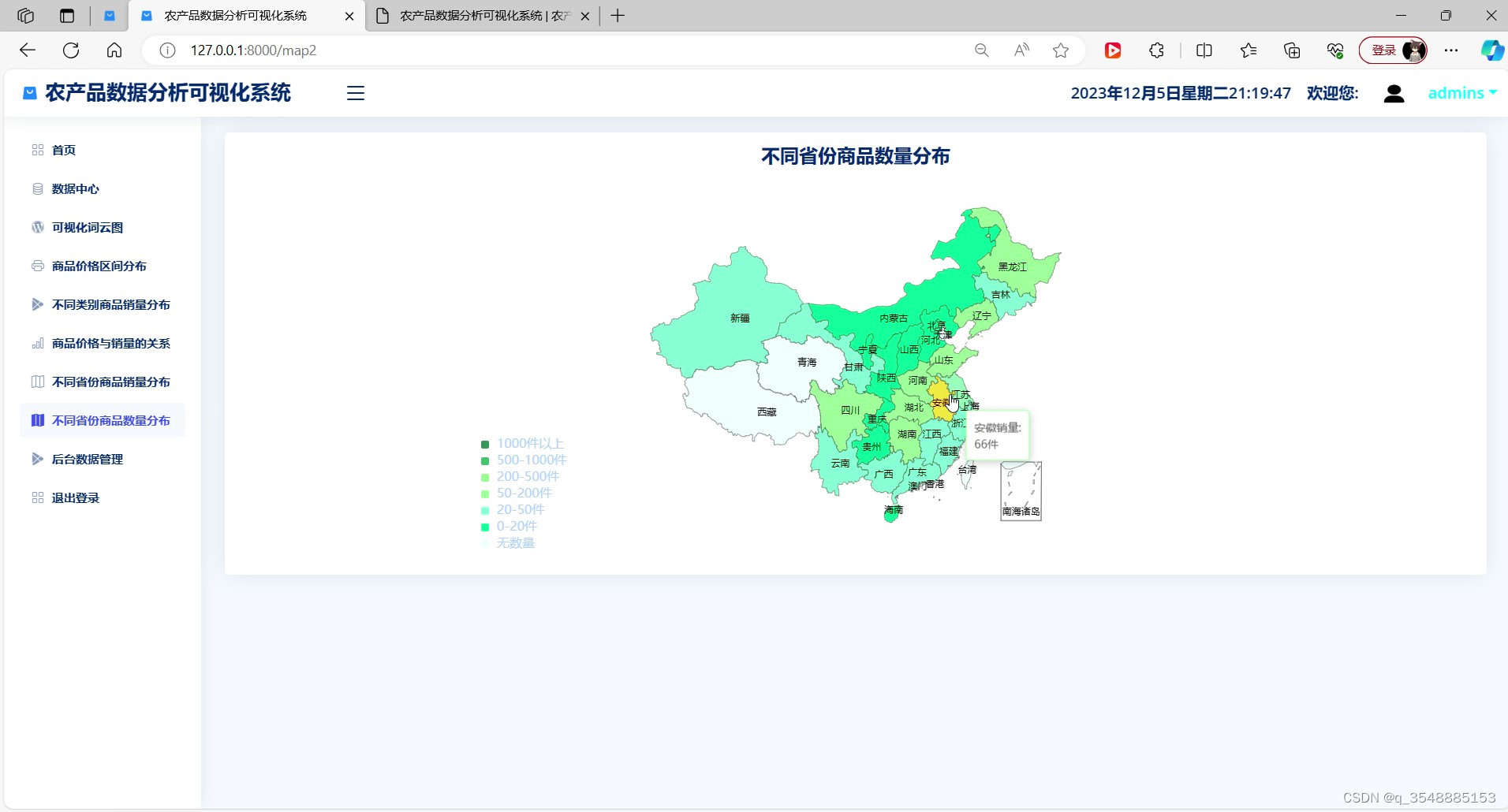
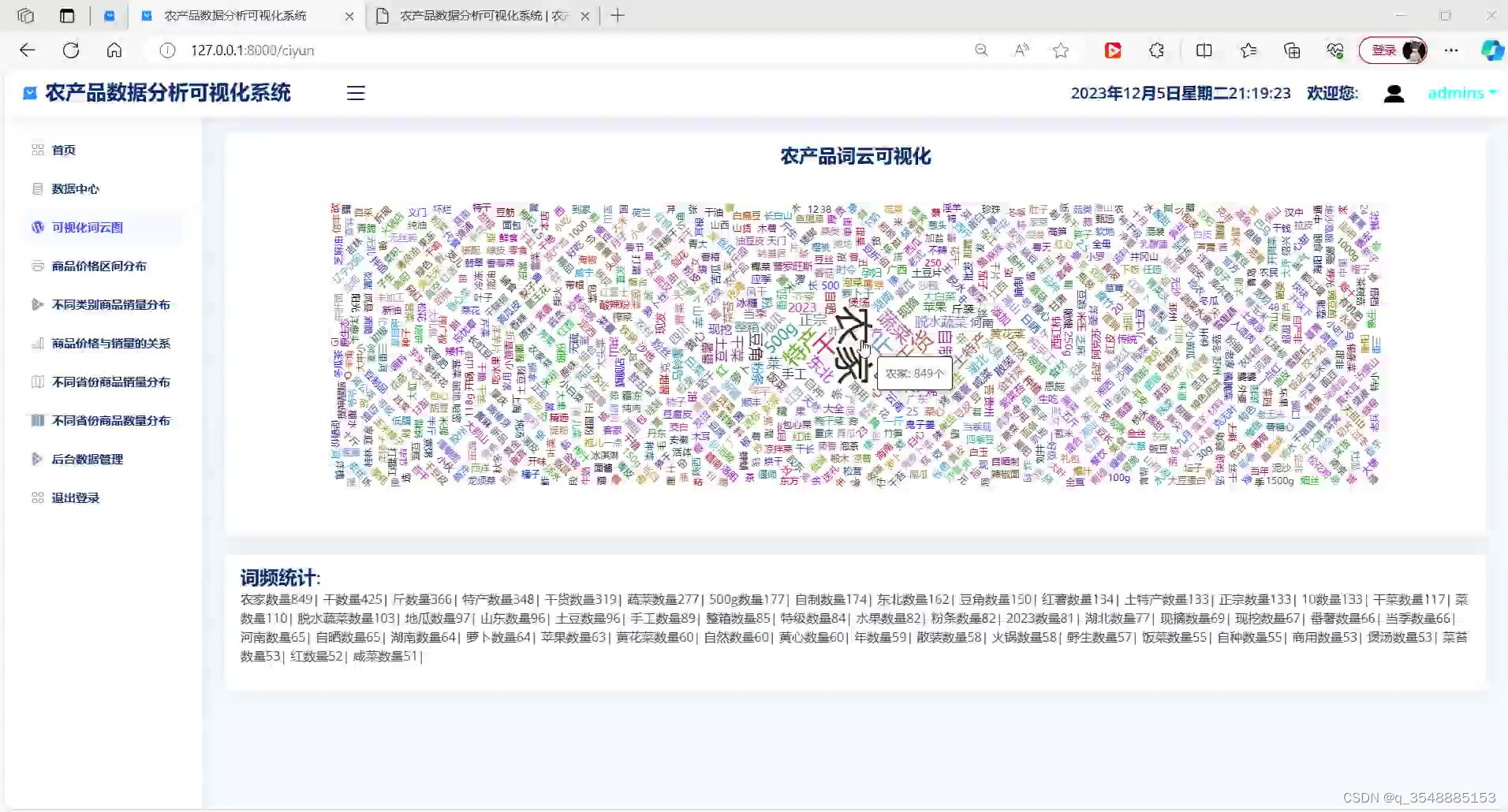
(5)农产品词云图分析
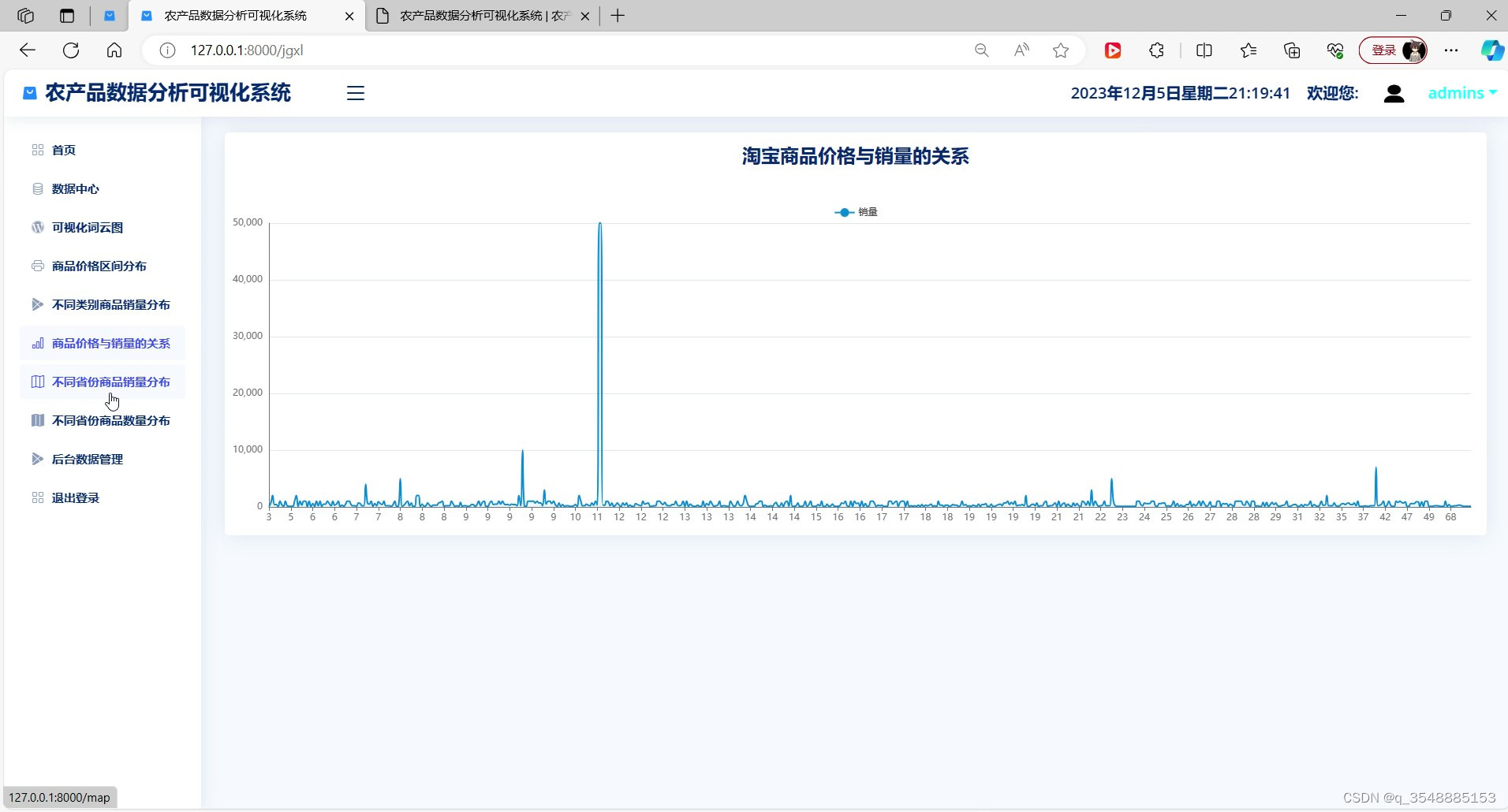
(6)农产品价格与销量的关系
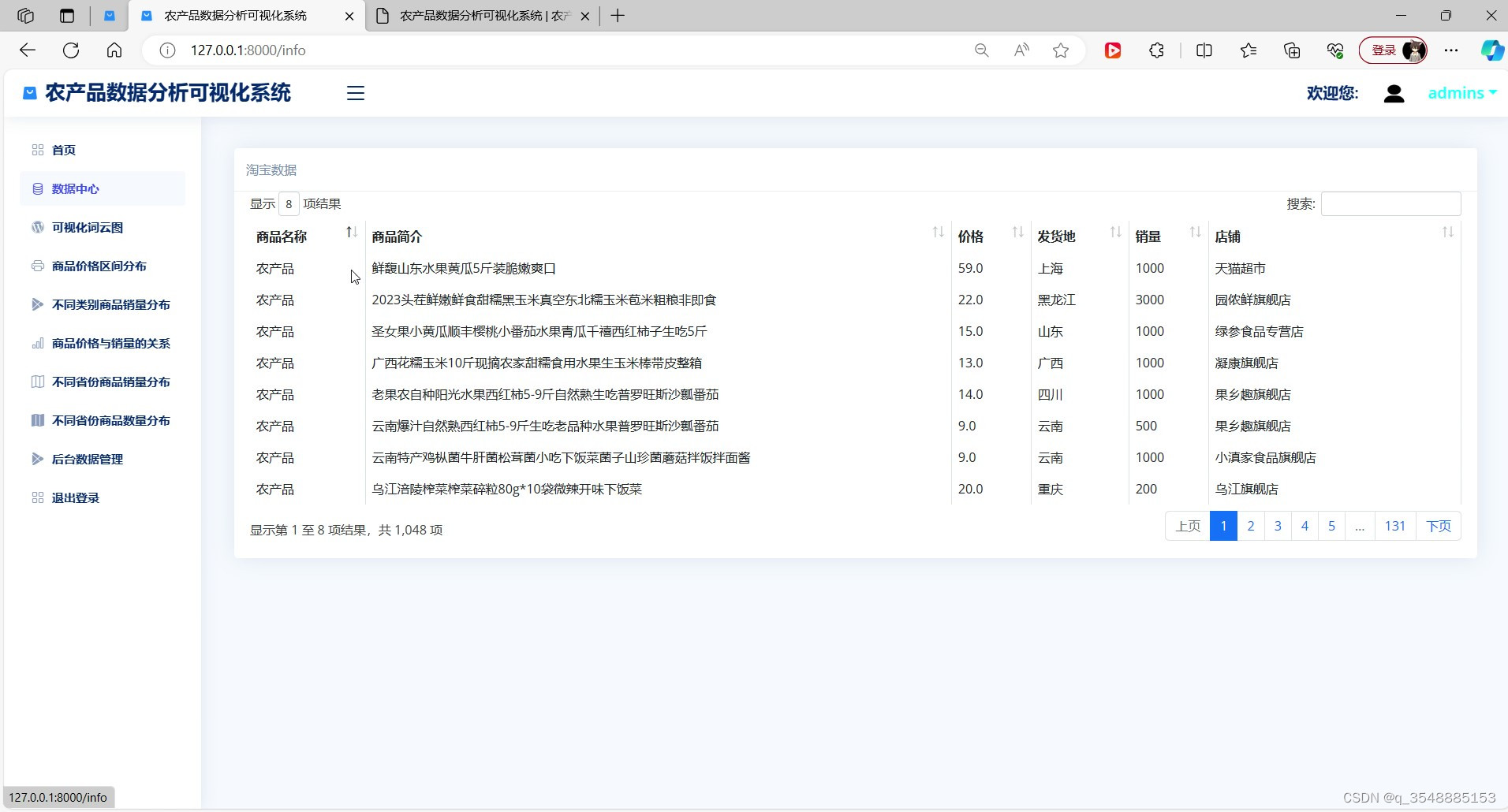
(7)农产品数据
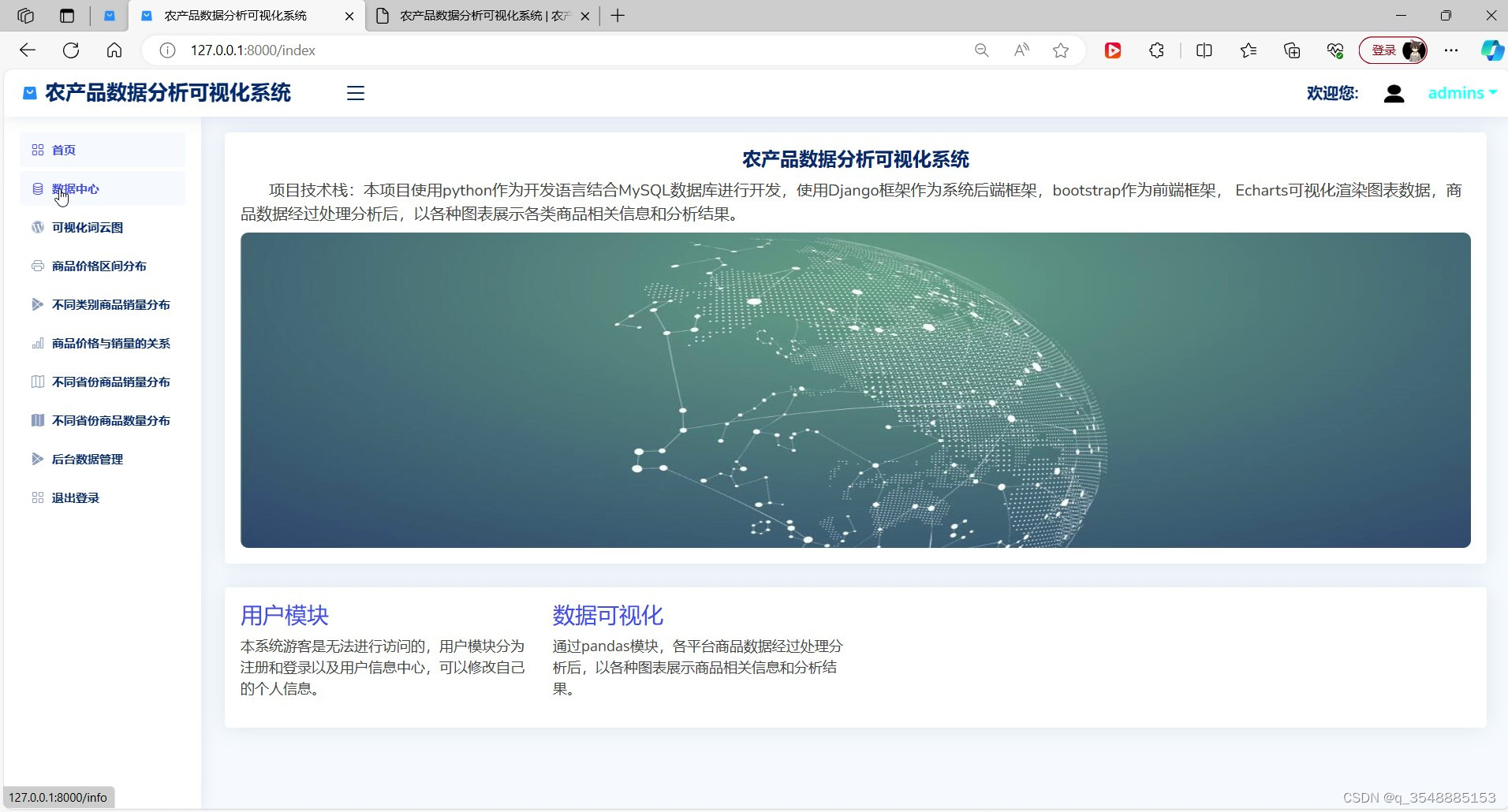
(8)首页
3、项目说明
农产品销售分析可视化系统是一个基于Python语言、Django框架、Echarts可视化库、MySQL数据库和HTML技术的综合性解决方案。该系统旨在帮助农业从业者、销售商和决策者更直观地理解农产品的销售情况,以便做出更明智的商业决策。
一、系统概述
农产品销售分析可视化系统通过整合销售数据,运用先进的数据分析技术和可视化手段,为用户提供清晰、直观的销售分析报告。该系统利用Django框架搭建后端服务,通过MySQL数据库存储和管理销售数据,前端则采用HTML结合Echarts库进行数据可视化展示。
二、核心功能
数据集成与管理:系统能够定期从各种销售渠道(如线上商城、线下门店等)收集销售数据,并将其存储到MySQL数据库中。通过数据库管理系统,用户可以方便地查询、修改和更新销售数据。
数据分析:系统内置多种数据分析算法,能够对销售数据进行深度挖掘。用户可以根据需要选择不同的分析维度(如产品类别、销售地区、销售时间等),系统将自动生成相应的分析报告。
数据可视化:系统利用Echarts库将分析结果以图表、图形等形式直观地展示出来。这些可视化图表不仅能够帮助用户快速了解销售情况,还能发现潜在的销售趋势和规律。
用户交互:系统提供友好的用户界面,用户可以通过浏览器访问系统并查看销售分析报告。同时,系统还支持用户自定义查询条件,以满足不同用户的个性化需求。
三、系统优势
实时性:系统能够实时收集和处理销售数据,确保分析结果的时效性和准确性。
灵活性:系统支持多种分析维度和可视化方式,用户可以根据需要灵活选择。
可扩展性:系统基于Django框架构建,具有良好的可扩展性。用户可以根据需要添加新的功能模块或修改现有功能。
易于使用:系统提供友好的用户界面和简洁的操作流程,用户无需专业培训即可轻松上手。
四、总结
农产品销售分析可视化系统是一个功能强大、易于使用的数据分析工具。它能够帮助用户全面了解农产品的销售情况,发现潜在的销售机会和挑战,为商业决策提供有力支持。在未来,随着技术的不断发展和完善,该系统将发挥更大的作用,推动农业产业的持续发展和创新。
4、核心代码
@login_required
def ciyun(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
def cy(df):
# 词云图数据处理
titles = df['标题'].tolist()
# 加载停用词表
stopwords = set()
with open(BASE_DIR + r'./app/StopWords.txt', 'r', encoding='utf-8') as f:
for line in f:
stopwords.add(line.strip())
# 将数据进行分词并计算词频
words = []
for item in titles:
if item:
words += jieba.lcut(item.replace(' ', ''))
word_counts = Counter([w for w in words if w not in stopwords])
# 获取词频最高的词汇
top20_words = word_counts.most_common()
words_data = []
for word in top20_words:
words_data.append({
'name': word[0], 'value': word[1]})
return words_data
word1 = cy(df1)
return render(request, 'ciyun.html', locals())
@login_required
def jiage(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
def cy(df):
# 商品价格区间分布
data_res = [[], [], [], [], [], [], [< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









