










博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈: Python语言 MySQL数据库 FLASK框架 Vue框架 机器学习算法 随机森林分类算法模型
摘 要
随着医疗数据日益增长,现有的数据管理和分析方式面临效率低下和信息孤岛等问题。系统服务于医疗行业,优化数据采集、分析和可视化。当前行业存在的数据整合不畅、决策支持不足、患者信息利用率低等缺陷。
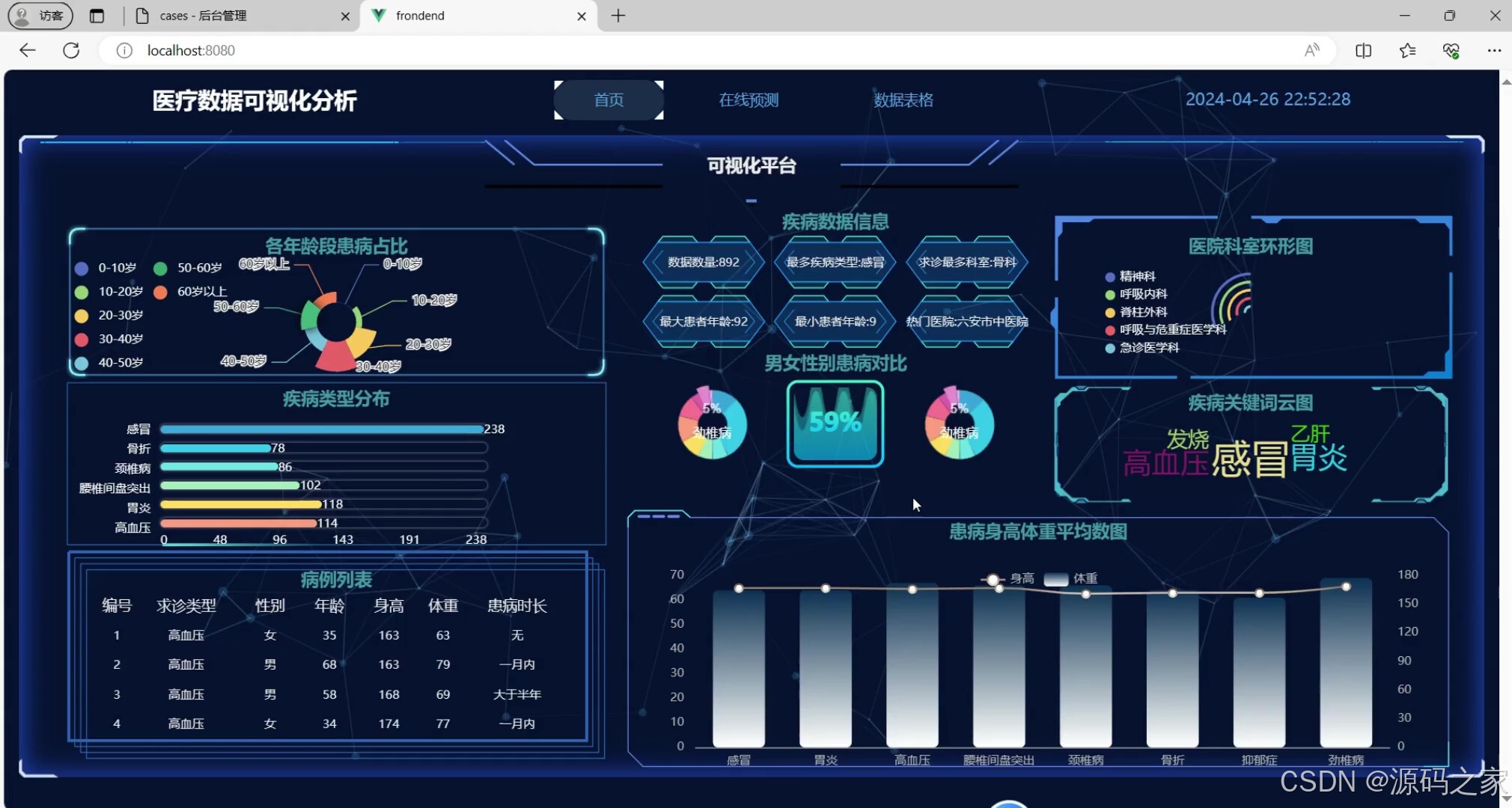
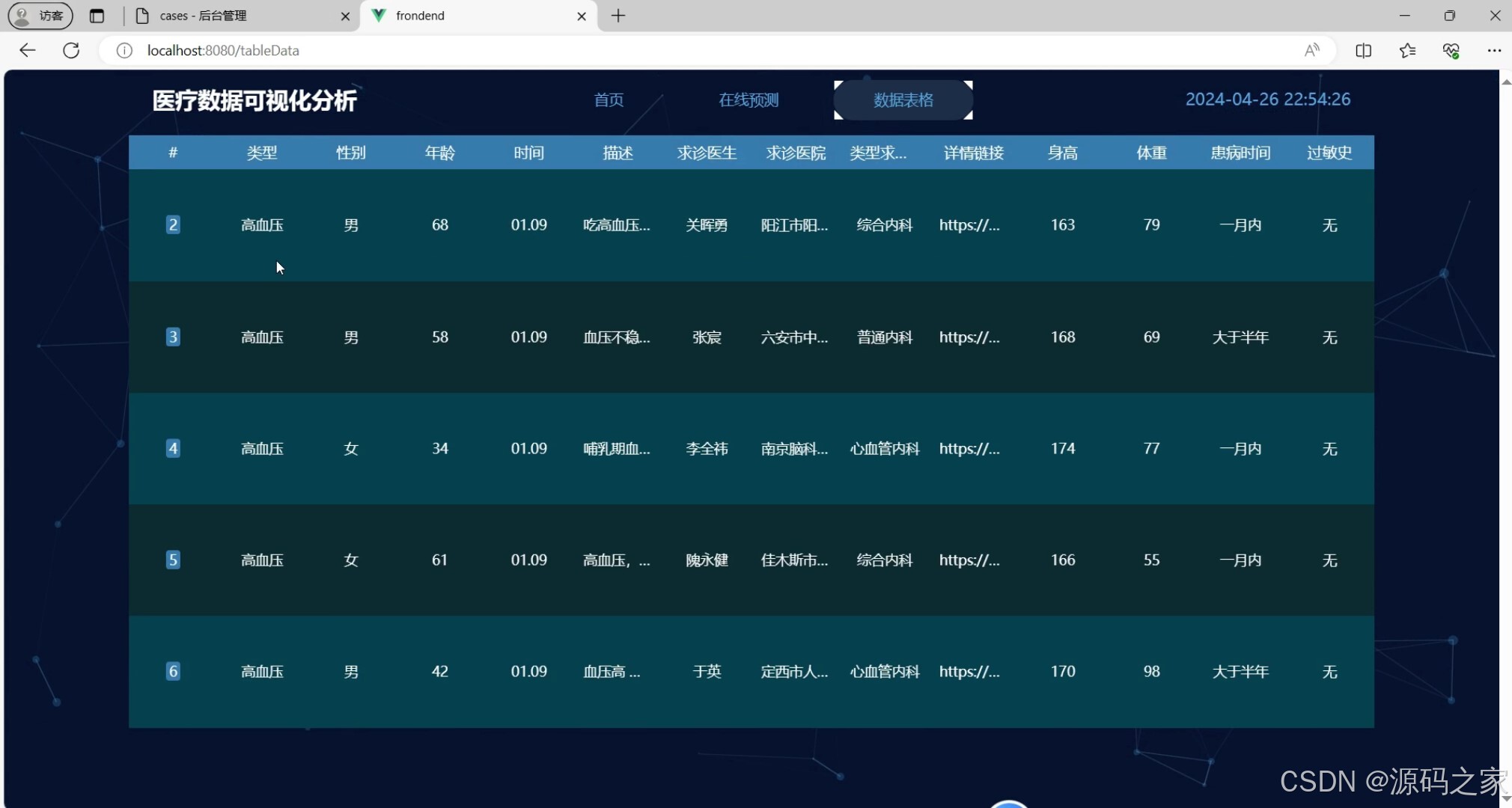
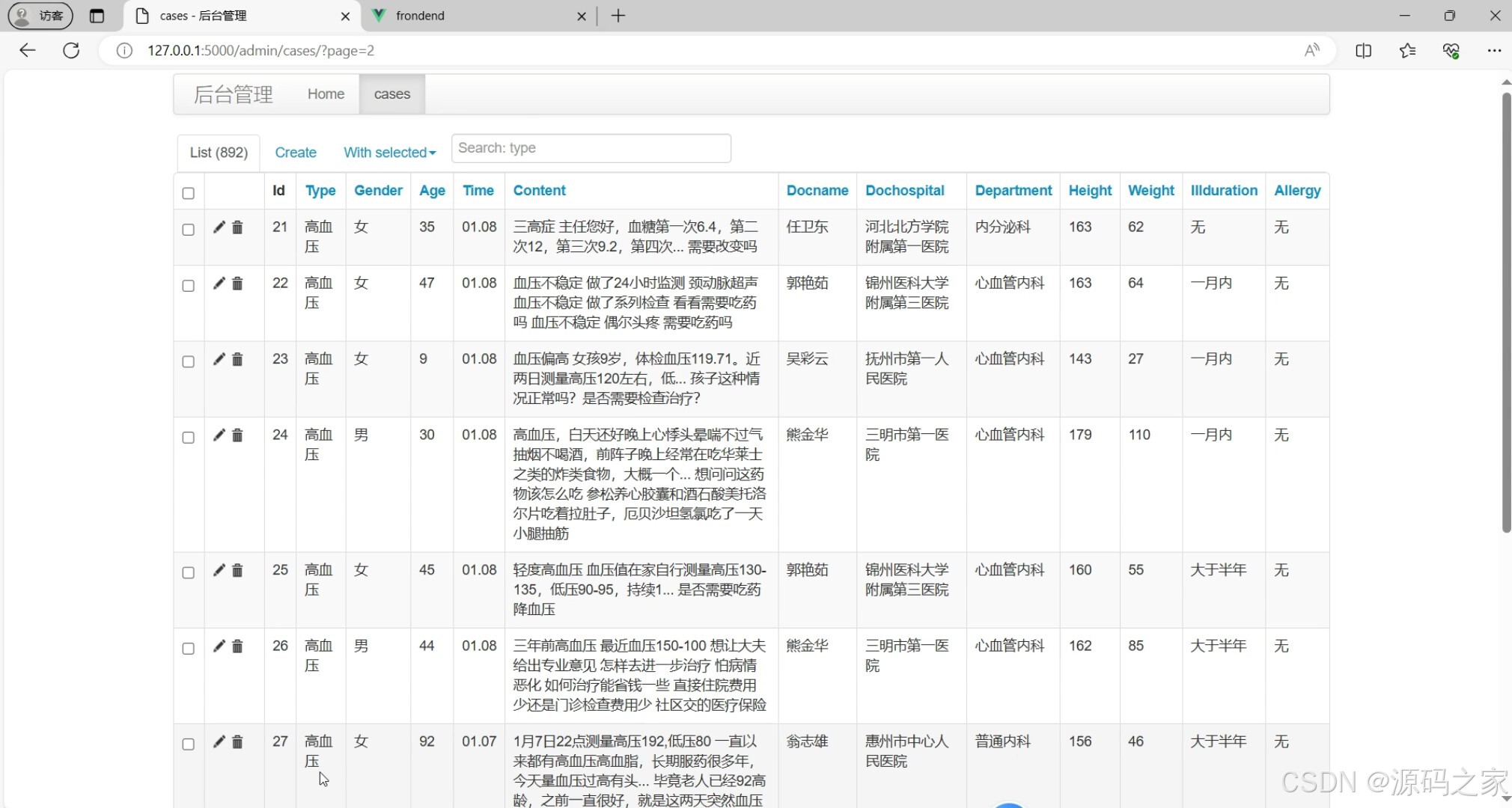
本系统采用Python语言和FLASK框架构建后端,前端使用Vue框架,数据库则选择MySQL。系统主要功能有可视化平台,展示各年龄段患病占比、疾病类型分布、病例列表及相关疾病数据信息,并提供男女性别患病对比和医院科室分布的环形图、疾病关键词云图、患病身高体重平均数图;在线预测功能允许用户输入病情描述并获取初步预测结果;数据表格则展示病例的详细信息,主要有求诊医生、求诊医院等,支持通过类型搜索与删除功能。
关键词:数据分析,可视化,Python,FLASK框架
2、项目界面
(1)医疗数据分析可视化实时监控大屏
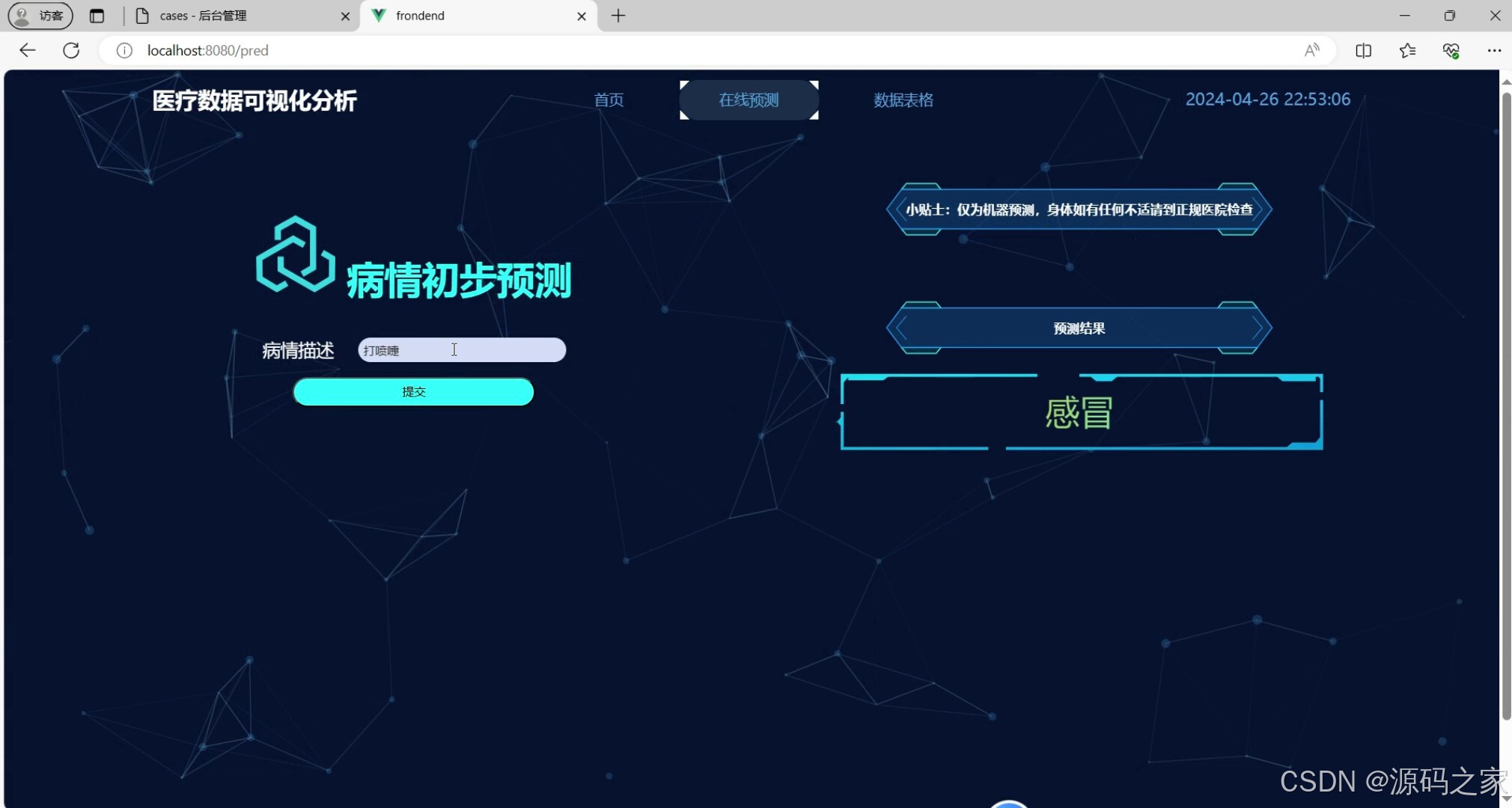
(2)疾病预测—机器学习算法
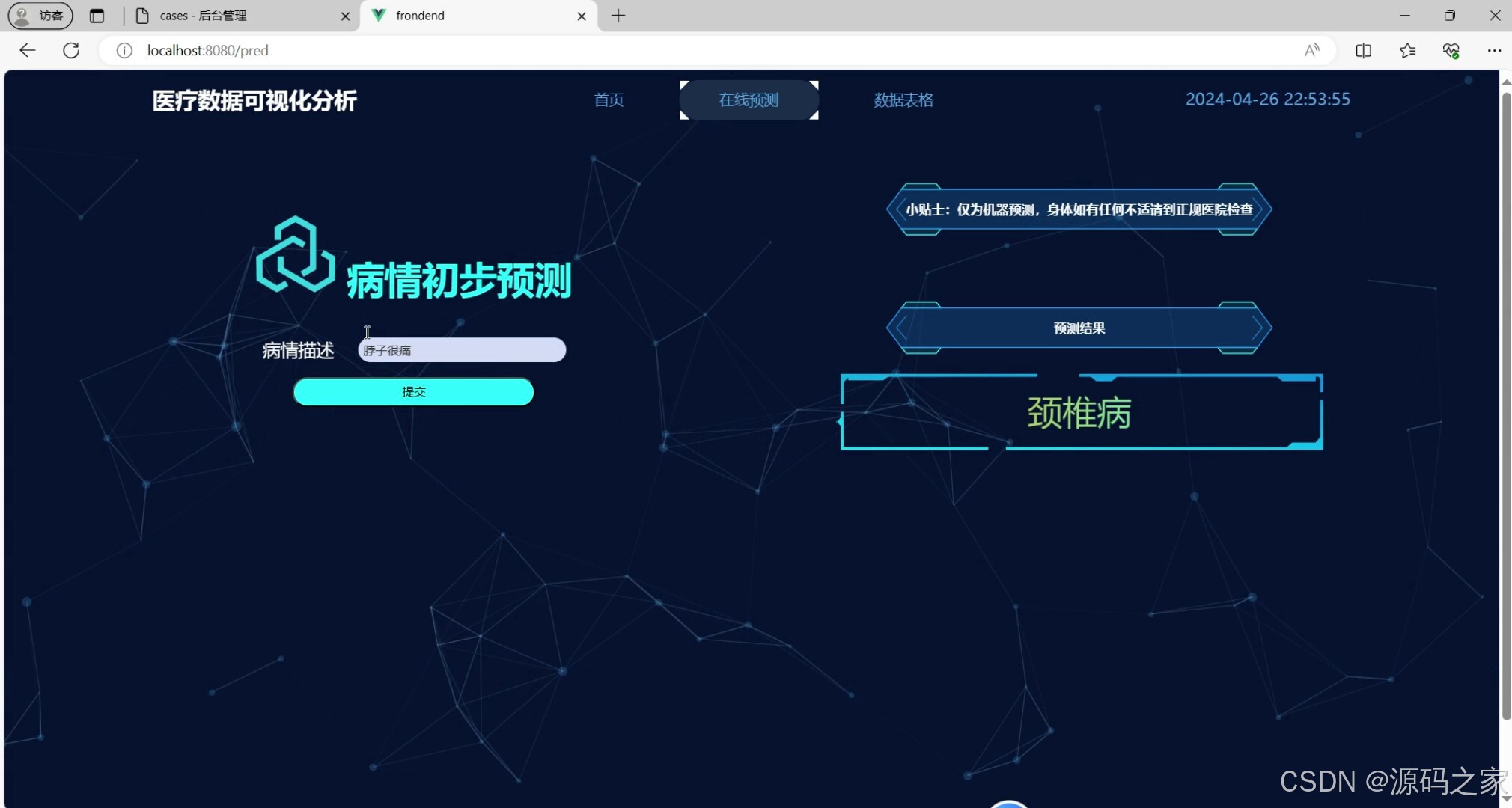
(3)疾病预测—机器学习算法
(4)医疗数据展示
(5)后台数据管理
3、项目说明
摘 要
随着医疗数据日益增长,现有的数据管理和分析方式面临效率低下和信息孤岛等问题。系统服务于医疗行业,优化数据采集、分析和可视化。当前行业存在的数据整合不畅、决策支持不足、患者信息利用率低等缺陷。
本系统采用Python语言和FLASK框架构建后端,前端使用Vue框架,数据库则选择MySQL。系统主要功能有可视化平台,展示各年龄段患病占比、疾病类型分布、病例列表及相关疾病数据信息,并提供男女性别患病对比和医院科室分布的环形图、疾病关键词云图、患病身高体重平均数图;在线预测功能允许用户输入病情描述并获取初步预测结果;数据表格则展示病例的详细信息,主要有求诊医生、求诊医院等,支持通过类型搜索与删除功能。
关键词:数据分析,可视化,Python,FLASK框架
医疗数据分析可视化系统介绍
在当今医疗领域,数据分析正逐渐成为提高诊断准确性、优化治疗流程和提升患者满意度的重要手段。本项目所介绍的医疗数据分析可视化系统,基于Python语言、MySQL数据库、Flask框架、Vue框架以及机器学习算法中的随机森林分类算法模型,旨在从大量医疗文本数据中提取有价值的信息,并通过直观的可视化方式展示给医疗工作者,辅助他们进行疾病预测和决策。
一、系统架构
该系统采用前后端分离的设计模式,后端基于Python语言和Flask框架构建,负责数据处理、算法训练和模型预测等核心功能;前端则采用Vue框架,提供用户交互界面和数据可视化展示。数据库方面,系统使用MySQL数据库来存储和管理医疗文本数据,确保数据的安全性和稳定性。
二、数据处理与机器学习
系统首先从MySQL数据库中获取医疗文本数据,这些数据可能包括患者的病历记录、医生的诊断报告、医学文献等。然后,通过Python语言对数据进行预处理,包括文本清洗、分词、特征提取等步骤,以提取出对疾病预测有帮助的关键信息。
接下来,系统利用随机森林分类算法模型对预处理后的数据进行训练。随机森林是一种集成学习方法,它通过构建多个决策树并综合它们的预测结果来提高分类的准确性。在训练过程中,系统会根据数据的特点和模型的性能调整参数,以优化模型的预测效果。
三、疾病预测与可视化
一旦模型训练完成,系统就可以利用该模型对新的中文文本数据进行类别预测。用户只需将待预测的文本数据输入到系统中,系统就会调用训练好的随机森林分类器进行预测,并返回预测结果。
为了更直观地展示预测结果和数据分布情况,系统还提供了丰富的可视化功能。通过Vue框架的前端界面,用户可以查看各类疾病的发病率、地域分布、时间趋势等信息,以及预测结果的详细数据。这些可视化图表不仅可以帮助医疗工作者更好地理解数据,还可以辅助他们进行疾病预测和决策。
四、总结
本医疗数据分析可视化系统利用先进的Python语言、MySQL数据库、Flask框架、Vue框架和机器学习算法,实现了从医疗文本数据中提取有价值信息、进行疾病预测和可视化展示的功能。该系统不仅提高了医疗工作者的工作效率,还为他们提供了更科学、更准确的决策支持。未来,该系统还将继续优化算法和界面设计,以满足更多医疗场景的需求。
4、核心代码
import jieba
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import accuracy_score,classification_report
from sklearn.preprocessing import LabelEncoder
from sqlalchemy import create_engine,text
conn = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/medicalinfo?charset=utf8')
stopwords = set(open('./machine/stopword.txt','r',encoding='utf-8').read().splitlines())
def tokensize(text):
words = [word for word in jieba.cut(text) if word not in stopwords]
return ' '.join(words)
def getData():
query = text('select * from cases')
try:
df = pd.read_sql(query,con=conn,index_col='id') #
except Exception as e:
print(e)
data = df[['content','type']]
data['content'] = data['content'].apply(tokensize)
# print(data)
return data
vectorizer = TfidfVectorizer(max_features=10000)
def model_train(data):
x_train,x_test,y_train,y_test = train_test_split(data['content'],data['type'],test_size=0.2,random_state=42)
#文本提取
x_train_vectorizer = vectorizer.fit_transform(x_train)
x_test_vectorizer = vectorizer.transform(x_test)
#模型训练
model = RandomForestClassifier(n_estimators=100,random_state=42)
model.fit(x_train_vectorizer,y_train)
y_pred = model.predict(x_test_vectorizer)
accuracy = accuracy_score(y_test,y_pred)
return model
def pred(model,content):
content = [' '.join(jieba.cut(content))]
x_test_vectorizer = vectorizer.transform(content)
pred = model.predict(x_test_vectorizer)
return pred[0]
if __name__ == '__main__':
trainData = getData()
model = model_train(trainData)
pred(model,'腰部疼痛')
5、源码获取方式
biyesheji0005 或 biyesheji0001 (绿色聊天软件)
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









