









上一篇写了如何在CDH中集成Flink
https://blog.csdn.net/qaz1qaz1qaz2/article/details/118153264
本篇记录一下Flink集成并使用Iceberg的过程
目录
1. 集成
1.1 版本
CentOS 7.2
CDH 6.3.2
Hadoop 3.0
Hive 2.1.1
Flink 1.11.2
Iceberg 0.11.1
1.2 过程
1. flink与Iceberg集成的包下载
iceberg-flink-runtime-0.11.1.jar
2.下载hive依赖包
由于Iceberg catalog依赖hive或者hadoop,因此也需要下载flink连接hive的相关jar包
具体的版本需要参照flink和CDH上hive版本,可参阅以下文档
https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/hive/
截图如下
需下载的依赖包如下:
flink-connector-hive_2.11-1.11.2.jar
flink-sql-connector-hive-2.2.0_2.11-1.11.2.jar
hive-exec-2.1.1.jar
3.安装依赖包
将iceberg-flink-runtime-0.11.1.jar,flink-connector-hive_2.11-1.11.2.jar,flink-sql-connector-hive-2.2.0_2.11-1.11.2.jar,hive-exec-2.1.1.jar拷贝到flink每个节点的“
/opt/cloudera/parcels/FLINK/lib/flink/lib”目录下
cp * /opt/cloudera/parcels/FLINK/lib/flink/lib/2. 使用
2.1 Flink SQL Client
启动flink sql client
cd /opt/cloudera/parcels/FLINK/lib/flink
./bin/sql-client.sh embedded \
-j /opt/cloudera/parcels/FLINK/lib/flink/lib/iceberg-flink-runtime-0.11.1.jar \
-j /opt/cloudera/parcels/FLINK/lib/flink/lib/flink-sql-connector-hive-2.2.0_2.11-1.11.2.jar \
shell问题1:启动报错
Caused by: java.lang.VerifyError: Stack map does not match the one at exception handler 70
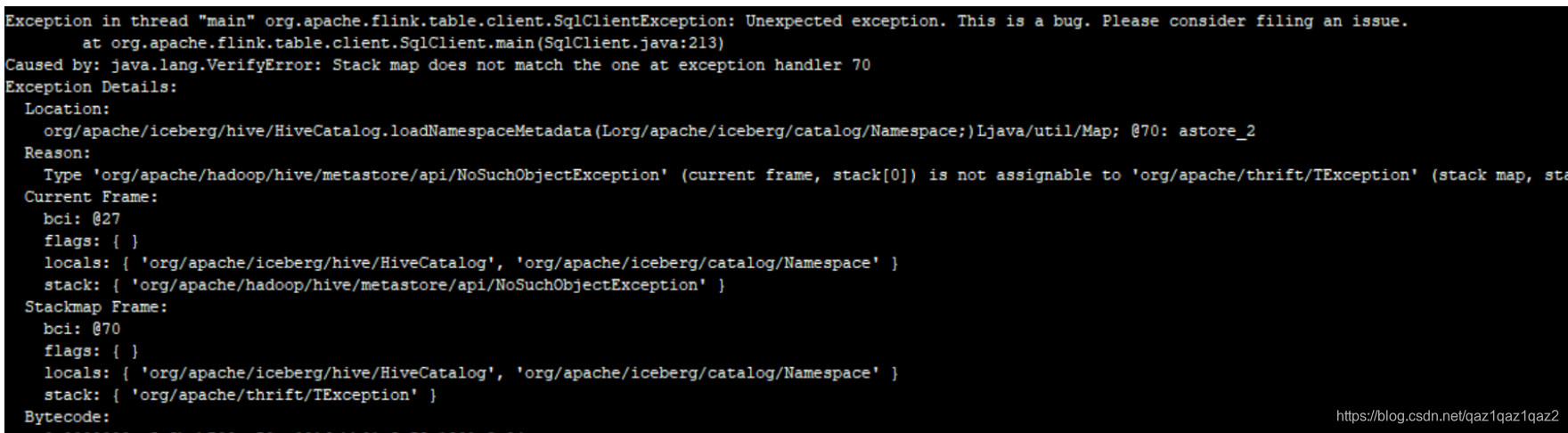
解决:
进入flink bin目录下,打开sql-client.sh文件,在启动jar包的地方加上-noverify ,跳过字节码校验,重新启动sql-client即可
cd /opt/cloudera/parcels/FLINK/lib/flink/bin
vi sql-client.sh
效果如图

常用命令
#创建iceberg catalog
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://localhost:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs://172.28.216.45:8020/user/hive/warehouse'
);
#创建数据库
CREATE DATABASE iceberg_db;
#创建表
CREATE TABLE iceberg_001 (
id BIGINT,
data STRING
);2.2 Flink Table Api
1.pom依赖,这是关键部分,如果缺少jar包,项目启动的时候会报错
<properties>
<scala.version>2.11.12</scala.version>
<flink.version>1.11.2</flink.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<!-- flink -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink table -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table</artifactId>
<version>${flink.version}</version>
<type>pom</type>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.11.2</version>
<scope>test</scope>
</dependency>
<!-- iceberg flink -->
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-flink-runtime</artifactId>
<version>0.11.1</version>
</dependency>
<!-- iceberg end -->
<!-- hadoop common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.0.0</version>
</dependency>
<!-- hadoop end -->
<!--- hive-metastore -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
2. scala读写iceberg代码
package com.rock.flink.iceberg
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.TableResult
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object FlinkIcebergTest {
/**
* flink version: 1.11.2
* iceberg version: 0.11.1
*/
def main(args: Array[String]): Unit ={
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.enableCheckpointing(10000)
val tenv = StreamTableEnvironment.create(env)
// 使用table api 创建 hive catalog
val tableResult = tenv.executeSql("CREATE CATALOG hive_catalog WITH (\n" +
" 'type'='iceberg',\n" +
" 'catalog-type'='hive',\n" +
" 'uri'='thrift://172.28.216.45:9083',\n" +
" 'warehouse'='hdfs://172.28.216.45:8020/user/hive/warehouse',\n" +
" 'property-version'='1'\n" +
")");
tenv.useCatalog("hive_catalog");
// 创建库
tenv.executeSql("CREATE DATABASE if not exists iceberg_hive_db");
tenv.useDatabase("iceberg_hive_db");
// 创建iceberg 结果表
tenv.executeSql("CREATE TABLE hive_catalog.iceberg_hive_db.iceberg111 (\n" +
" id BIGINT,\n" +
" data STRING\n" +
")");
//向Iceberg写入数据
val result= tenv.executeSql("insert into hive_catalog.iceberg_hive_db.iceberg111 values (100,'hello')");
result.print()
//读取Iceberg数据
val showResult = tenv.executeSql("select * from hive_catalog.iceberg_hive_db.iceberg111")
showResult.print()
}
}3. 运行结果

















 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











