









什么是大数据
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据的定义是4Vs:Volume、Velocity、Variety、Veracity。用中文简单描述就是大、快、多、真。
Volume —— 数据量大
随着技术的发展,人们收集信息的能力越来越强,随之获取的数据量也呈爆炸式增长。例如百度每日处理的数据量达上百PB,总的数据量规模已经到达EP级。Velocity —— 处理速度快
指的是销售、交易、计量等等人们关心的事件发生的频率。2017年双11,支付成功峰值达25.6万笔/秒、实时数据处理峰值4.72亿条/秒。Variety —— 数据源多样
现在要处理的数据源包括各种各样的关系数据库、NoSQL、平面文件、XML文件、机器日志、图片、音视频等等,而且每天都会产生新的数据格式和数据源。Veracity —— 真实性
诸如软硬件异常、应用系统bug、人为错误等都会使数据不正确。大数据处理中应该分析并过滤掉这些有偏差的、伪造的、异常的部分,防止脏数据损害到数据准确性。
如何学习大数据
在谈到学习大数据的时候,不得不提Hadoop和Spark。
- Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 [1]
Hadoop实现了一个分布式文件系统(Hadoop Distributed File
System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high
throughput)来访问应用程序的数据,适合那些有着超大数据集(large data
set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
简而言之,Hadoop就是处理大数据的一个分布式系统基础架构。
- Spark
- Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop
MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark
在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala
能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。 尽管创建 Spark
是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos
的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and
People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
简而言之,Spark是那么一个专门用来对那些分布式存储的大数据进行处理的工具。
关于Hadoop和Spark学习这块,我也是个初学者,对于整体的学习路线目前无法给出很好的答案,但是可以推荐一些学习大数据不错的文章以及相关资源,这些可以在本文底部获取。
大数据的相关技术介绍
首先看张大数据的整体技术图吧,可以有个更直观的了解。
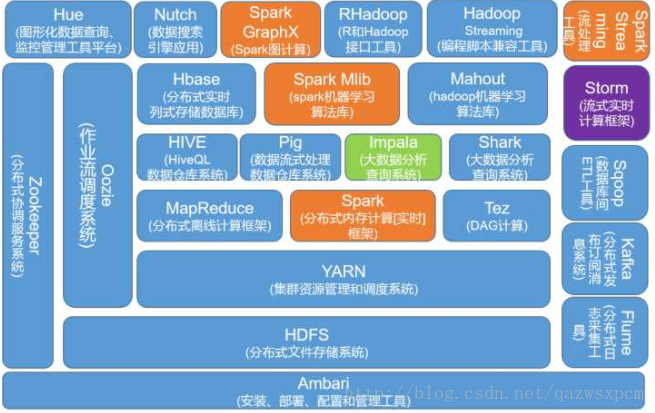
注:Shark 目前已经被Spark SQL取代了。
看到了这么多相关技术,是不是眼花了了呢,这上面的技术别说都精通,全部都能用好的估计也多少。
那么这些技术应该主要学习那些呢?
先将这些技术做个分类吧。
- 文件存储:Hadoop HDFS、Tachyon、KFS
- 离线计算:Hadoop MapReduce、Spark
- 流式、实时计算:Storm、Spark Streaming、S4、Heron、Flink
- K-V、NOSQL数据库:HBase、Redis、MongoDB
- 资源管理:YARN、Mesos
- 日志收集:Flume、Scribe、Logstash、Kibana
- 消息系统:Kafka、StormMQ、ZeroMQ、RabbitMQ
- 查询分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、分布式协调服务:Zookeeper、Kylin、Druid
- 集群管理与监控:Ambari、Ganglia、Nagios、Cloudera Manager
- 数据挖掘、机器学习:Mahout、Spark MLLib
- 数据同步:Sqoop
- 任务调度:Oozie
这样整体之后,对于如何学习是不是有个更明确的路线了呢?
那么个人觉得初步学习的技术应该有以下这些:
HDFS
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。 HDFS存储相关角色与功能: Client:客户端,系统使用者,调用HDFS API操作文件;与NN交互获取文件元数据;与DN交互进行数据读写。 Namenode:元数据节点,是系统唯一的管理者。负责元数据的管理;与client交互进行提供元数据查询;分配数据存储节点等。 Datanode:数据存储节点,负责数据块的存储与冗余备份;执行数据块的读写操作等。MapReduce
MapReduce是一种计算模型,用以进行大数据量的计算。Hadoop的MapReduce实现,和Common、HDFS一起,构成了Hadoop发展初期的三个组件。MapReduce将应用划分为Map和Reduce两个步骤,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。YARN
YARN是Hadoop最新的资源管理系统。除了Hadoop MapReduce外,Hadoop生态圈现在有很多应用操作HDFS中存储的数据。资源管理系统负责多个应用程序的多个作业可以同时运行。例如,在一个集群中一些用户可能提交MapReduce作业查询,另一些用户可能提交Spark 作业查询。资源管理的角色就是要保证两种计算框架都能获得所需的资源,并且如果多人同时提交查询,保证这些查询以合理的方式获得服务。SparkStreaming
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数据源(如Kdfka、Flume、Twitter、Zero和TCP 套接字)进行类似Map、Reduce和Join等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。SparkSQL
SparkSQL是Hadoop中另一个著名的SQL引擎,正如名字所表示的,它以Spark作为底层计算框架,实际上是一个Scala程序语言的子集。Spark基本的数据结构是RDD,一个分布于集群节点的只读数据集合。传统的MapReduce框架强制在分布式编程中使用一种特定的线性数据流处理方式。MapReduce程序从磁盘读取输入数据,把数据分解成键/值对,经过混洗、排序、归并等数据处理后产生输出,并将最终结果保存在磁盘。Map阶段和Reduce阶段的结果均要写磁盘,这大大降低了系统性能。也是由于这个原因,MapReduce大都被用于执行批处理任务Hive
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。Impala
Impala是一个运行在Hadoop之上的大规模并行处理(MPP)查询引擎,提供对Hadoop集群数据的高性能、低延迟的SQL查询,使用HDFS作为底层存储。对查询的快速响应使交互式查询和对分析查询的调优成为可能,而这些在针对处理长时间批处理作业的SQL-on-Hadoop传统技术上是难以完成的。 Impala的最大亮点在于它的执行速度。官方宣称大多数情况下它能在几秒或几分钟内返回查询结果,而相同的Hive查询通常需要几十分钟甚至几小时完成,因此Impala适合对Hadoop文件系统上的数据进行分析式查询。Impala缺省使用Parquet文件格式,这种列式存储对于典型数据仓库场景下的大查询是较为高效的。HBase
一个结构化数据的分布式存储系统。 HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。 HBase是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。Apache Kylin
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。Flume
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
参考文章
大数据初步了解
http://lxw1234.com/archives/2016/11/779.htm
大数据杂谈
http://lxw1234.com/archives/2016/12/823.htm
推荐文章
零基础学习Hadoop
http://blog.csdn.net/qazwsxpcm/article/details/78460840
HBase 应用场景
http://blog.csdn.net/lifuxiangcaohui/article/details/39894265
Hadoop硬件选择
http://bigdata.evget.com/post/1969.html
图解Spark:核心技术与案例实战
http://www.cnblogs.com/shishanyuan/category/925085.html
一个大数据项目的架构设计与实施方案
http://www.360doc.com/content/17/0603/22/22712168_659649698.shtml
相关文档
Hadoop-10-years
链接:http://pan.baidu.com/s/1nvBppQ5 密码:7i7m
Hadoop权威指南
链接:http://pan.baidu.com/s/1skJEzj3 密码:0ryw
Hadoop实战
链接:http://pan.baidu.com/s/1dEQi29V 密码:ddc7
Hadoop源代码分析
链接:http://pan.baidu.com/s/1bp8RTcN 密码:ju63
Spark最佳学习路径
链接:http://pan.baidu.com/s/1i5MmJVv 密码:qfbt
深入理解大数据+大数据处理与编程实践
链接:http://pan.baidu.com/s/1dFq6OSD 密码:7ggl
版权声明:
作者:虚无境
博客园出处:http://www.cnblogs.com/xuwujing
CSDN出处:http://blog.csdn.net/qazwsxpcm
个人博客出处:http://www.panchengming.com
原创不易,转载请标明出处,谢谢!















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









