







-
HTTP缓存
使用缓存的优劣
因为Web的访问时下载特性,使用缓存可以有效避免每次访问都下载资源给服务器造成带宽压力、同时减少Web加载时间。
但缓存使用不当,会造成用户无法看到最新的内容或者显示问题。
浏览器缓存机制
根据http协议,在 http 1.0 时代,给客户端设定缓存方式一般通过两个字段 Pragma 和 Expires:
<meta http-equiv="pragma" content="no-cache" >
<meta http-equiv="Expires" content="Tue, 01 Jan 1980 1:00:00 GMT">
其中pragma字段代表是否使用缓存,Expires代表缓存时间
http 1.1 新增加了 Cache-Control 来定义缓存过期时间,目的是针对上述 Expires 时间是相对于服务器而言,无法保证和客户端时间统一的问题
<meta http-equiv="Cache-Control" content="public,max-age=900">
max-age:指示客户机可以接收生存期不大于指定时间(以秒为单位)的响应。
今天主要说明的三种缓存方式:
public: 所有内容都将被缓存(客户端和代理服务器都可缓存)。
no-store:所有内容都不会被缓存到缓存或 Internet 临时文件中。
no-cache: 告诉浏览器、缓存服务器,不管本地副本是否过期,使用资源副本前,一定要到源服务器进行副本有效性校验。
- Public缓存
以apache为例:
打开httpd.conf,找到并取消注释:
LoadModule headers_module modules/mod_headers.so
然后在extra/ httpd-vhosts.conf中加入:
header set cache-control " public,max-age=5"
设置完毕后,重启apache,刷新浏览器页面,观察缓存时间,过5秒后,观察缓存时间。
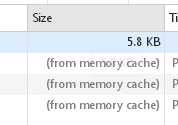
在有效期内,浏览器返回的状态码均为200,from cache。
- No-cache缓存
在进行一个测试:
header set cache-control "no-cache"
设置完毕,重启apache,刷新浏览器页面观察,此时应该状态码为304
这种缓存模式通过header头的两个字段:Last-Modified(最后修改时间)和ETag(唯一标识符)来判断是否需要重新更新资源。
Last-Modified代表的是文件最后修改时间
ETag代表的是文件唯一标识符(具体规则由服务器软件自动判定或手动设置)
判断这两个参数是否一致,如果一致返回状态码304,代表这个资源没有被更改过(可以使用本地)
- No-store缓存
就是不使用缓存,每次打开页面一定向服务器索取最新资源。
Public与no-cache对比:
虽然no-cache可以随时使用最新的资源且节约服务器带宽,但依然要向服务器发起http请求进行询问,没有能够非常有效的减少http请求的次数。
Public这种强缓存可以将请求和带宽优化做到极致,但如果利用不好就会造成用户显示内容的滞后。
no-store(禁用浏览器缓存)考虑服务器压力问题一般不会应用在网站上,小部分内网、局域网用户会用到。
具体可以看流程图:

浏览器信息储存发展
超文本标记语言(第一版)——在1993年6月作为互联网工程工作小组(IETF)工作草案发布(并非标准),1997年12月提出了HTML4。
之后随着计算机普及,互联网人数增多,Web的复杂性提高,很快HTML4的功能与标准不能满足建站者的需要,2014年HTML5标准规范,正式宣告HTML5时代到来。
因为http是无状态协议,所以当一个用户访问多个页面时无法确定其身份,所以发明了Cookie用来保存身份或其他信息,这是石器时代唯一的本地储存功能。
每个HTTP请求,浏览器会自动将Cookie附加到请求头中,同时每个Cookie有4KB的大小限制。一个是减少本地磁盘占用,另一个是由于请求头中会附带Cookie,会增加请求头的大小。
浏览器本地储存技术
为了满足更复杂的网页需求,HTML5标准制定了多种本地储存规范,其中localStorage、sessionStorage兼容性良好,基本所有浏览器都支持,Web SQL则只有Chrome、Safari、Opera在进行了实现。
localStorage、sessionStorage是一种key、value的简单储存方式,一般浏览器支持分配5-20MB的储存空间。其中localStorage是储存在硬盘上的,sessionStorage储存在内存中,在关闭浏览器后消失。
使用很简单:只有三个API:
localStorage.setItem() localStorage.getItem() localStorage.removeItem()
但要注意的是清理浏览器缓存时会被清理掉。
Js、css文件混淆压缩
再上线之前对js、css代码进行压缩,不仅保护代码原创性,还能减少体积。
这里使用uglifyjs进行演示:
通过Node.js进行安装:
npm install uglify-js –g
安装好后,进入目录,运行命令(将inet.js压缩为inet-min.js):
uglifyjs inet.js -o inet-min.js
还有一些其他参数这里一并列出来:
--source-map 指定输出的文件产生一份sourcemap
--source-map-root 此路径中的源码编译后会产生sourcemap
--source-map-url 放在//#sourceMappingURL的sourcemap路径. 默认是
--source-map传入的值.
--source-map-include-sources 如果你要在sourcemap中加上源文件的内容作为sourcesContent属性,
就传这个参数吧。
--source-map-inline 把sourcemap以base64格式附在输出文件结尾
--in-source-map 输入sourcemap。假如的你要编译的JS是另外的源码编译出来的。
假如该sourcemap包含在js内,请指定"inline"。
--screw-ie8 是否要支持IE6/7/8。UglifyJS默认不兼容IE。
--support-ie8 是否要支持IE6/7/8,等同于在`compress`, `mangle` 和
`output`选项中都设置`screw_ie8: false`
--expr 编译一个表达式,而不是编译一段代码(编译JSON时用)
-p, --prefix 忽略sourcemap中源码的前缀。例如`-p 3`会干掉文件名前面3层目录
以及保证路径是相对路径。你也可以指定`-p relative`,让UglifyJS
自己计算输出文件、sourcemap与源码之间的相对路径。
-o, --output 输出文件,默认标准输出(STDOUT)
-b, --beautify 美化输出/指定输出 选项
-m, --mangle Mangle的名字,或传入一个mangler选项.
-r, --reserved mangle的例外,不包含在mangling的名字
-c, --compress 是否启用压缩功能(true/fasle),或者传一个压缩选项对象, 例如
`-c 'if_return=false,pure_funcs=["Math.pow","console.log"]'`,
`-c`不带参数的话就是用默认的压缩设置。
-d, --define 全局定义
-e, --enclose 所有代码嵌入到一个大方法中,传入参数为配置项
--comments 保留版权注释。默认保留Google Closure那样的,保留JSDoc-style、
包含"@license" 或"@preserve"字样的注释。你也可以传下面的参数:
- "all" 保留所有注释
- 正则(如`/foo/`、`/^!/`)保留匹配到的。要注意,如果启用了压
缩,因为会移除不可达代码以及压缩连续声明,因此不是*所有*注释都能
保留下来。
--preamble 在输出文件开头插入的前言。你可以插入一段注释,例如版权信息。
这些不会被编译,但sourcemap会改成当前的样子。
--stats 在STDERR中显示操作运行时间。
--acorn 用 Acorn解析。
--spidermonkey 假如输入文件是 SpiderMonkey AST 格式(像JSON).
--self 把UglifyJS2本身也构建成一个依赖包
(等同于`--wrap=UglifyJS --export-all`)
--wrap 所有代码嵌入到一个大函数中,让"exports"和"global"变量有效,
你需要传入一个参数指定模块被浏览器引入时的名字。
--export-all 只当`--wrap`时有效,告诉UglifyJS自动把代码暴露到全局。
--lint 显示一些可视警告
-v, --verbose Verbose
-V, --version 打印版本号.
--noerr 不要为-c,-b 或 -m选项中出现未知选项而抛出错误。
--bare-returns 允许返回函数的外部。当最小化CommonJs模块和Userscripts时,
可能匿名函数会被.user.js引擎调用立即执行(IIFE)
--keep-fnames 不要混淆、干掉的函数的名字。当代码依赖Function.prototype.name时有用。
--reserved-file 要保留的文件的名字
--reserve-domprops 保留(绝大部分?)DOM的属性,当--mangle-props
--mangle-props 混淆属性,默认是`0`.设置为`true`或`1`则会混淆所有属性名。
设为`unquoted`或 `2`则只混淆不在引号内的属性。`2`时也会让
`keep_quoted_props` 美化选项生效,保留括号内的属性;让压缩选项
的`properties`失效,阻止覆写带点号(.)的属性。你可以通过在命令
中明确设置来覆写它们。
--mangle-regex 混淆正则,只混淆匹配到的属性名。
--name-cache 用来保存混淆map的文件
--pure-funcs 假如返回值没被调用则可以安全移除的函数。
例如`--pure-funcs Math.floor console.info`(需要设置 `--compress`)一般使用-m参数进行最小化压缩
零散图片合并
多张图片合并在一起能够有效减少请求次数,但维护起来会相应变困难一些,图片合并工具也有很多,但我一般只用PS。
![]()
Css3规范中也可以将图片转化为base64编码格式放到css文件中,从而减少图片的加载,非常适合多组的零散小图,但维护性略差。
服务器使用gzip压缩
Gzip压缩可以先在服务端进行压缩,然后传递给浏览器后浏览器在进行解压,从而减少大小,以apache为例,打开httpd.conf:
LoadModule deflate_module modules/mod_deflate.so
就能打开gzip压缩,
接着在下方添加代码:
<IfModule mod_deflate.c>
# 告诉 apache 对传输到浏览器的内容进行压缩
SetOutputFilter DEFLATE
# 压缩等级1-9
DeflateCompressionLevel 9
#设置不对后缀gif,jpg,jpeg,png的图片文件进行压缩
SetEnvIfNoCase Request_URI .(?:gif|jpe?g|png)$ no-gzip dont-vary
</IfModule>
一般文本压缩率能达到50%甚至更好,图片压缩效果不明显,同时在header里面就能看到:Content-Encoding:gzip字段。
我本地测试一个6kb的html和css在启用level1时就能压缩到2kb,但1-9效果并不明显。虽然gzip好用,但是需要消耗cpu处理,还是要看服务器本身的场景,带宽重要还是CPU更重要。
图片懒加载
即当网页很长时,只加载第一屏的图片,当用户继续往后滚屏的时候才加载后续的图片。因为不是所有用户都想浏览整个网页。
这个实现方法一般是在开发时配合处理。
将资源分离或放入CDN
一般来说,浏览器会对统一域名下的http请求数进行限制。
比如a.dajiaochongmanhua.com下有30张图片资源,那么实际上浏览器不会同时加载这30张图片,只会同时下载10张(具体几张看浏览器机制)。
但a.dajiaochongmanhua.com、b.dajiaochongmanhua.com、c.dajiaochongmanhua.com各有10张却会同时下载30张。
且还有一个好处不会携带cookie,减少请求头大小。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









