







路过的小游侠+ 原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
理解进程调度时机跟踪分析进程调度与进程切换的过程
进程调度和进程调度时机的分析:不同类型的进程有不同的调度需求,所以需要不同的算法来满足人的需求和使计算机高效运行。就有了调度策略,Linux根据优先级排队
— schedule ,内核函数,非系统代用,只能使用中断处理过程调用(时钟中断,i/o中断,系统调用和异常),或者返回用户态调用need_reschedule(被动调度)。内核线程可以直接调用schedule,也可以在中断过程中进行调研度,即内核线程作为一类的特殊进程可以主动调度,也可以被动调度。
挂起正在CPU上执行的进程,与中断时候保存现场不同
进程上下文包含了:
- 用户地址空间:程序代码,数据,用户堆栈等
- 控制信息:进程描述符,内核堆栈等
- 硬件上下文
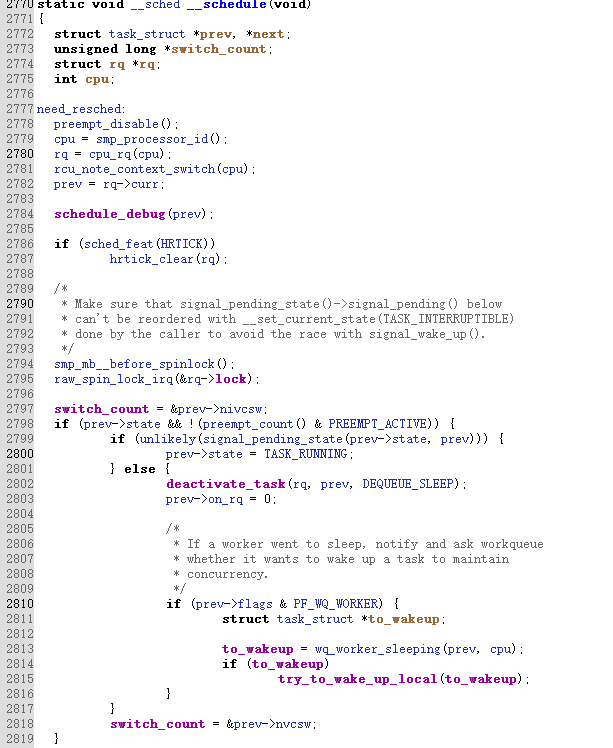
这是schedule函数,调用context_switch来进行上下文切换,其调用内联汇编switch_to来进行关键上下文切换。
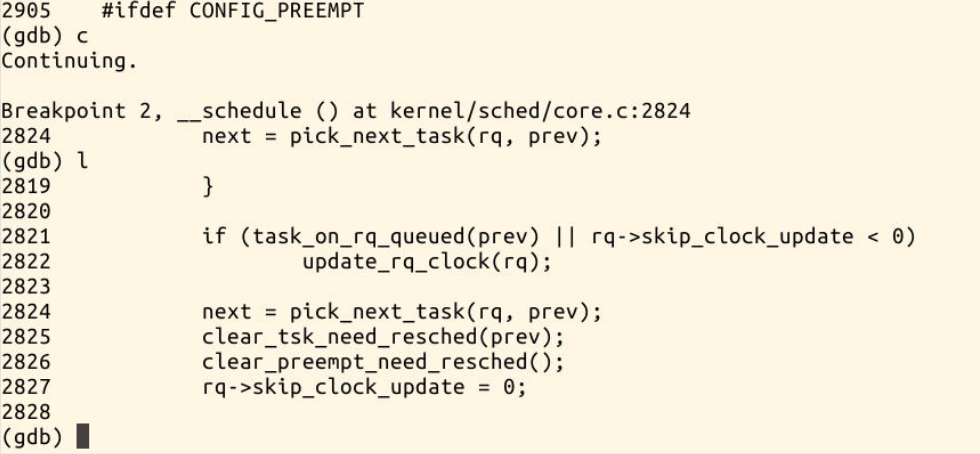
2824,next = pick_next_task(rq,prev) //进程调度算法
其中核心代码switch_to,用于切换prev和next进程

#define switch_to(prev, next, last) \
do { \
/* \
* Context-switching clobbers all registers, so we clobber \
* them explicitly, via unused output variables. \
* (EAX and EBP is not listed because EBP is saved/restored \
* explicitly for wchan access and EAX is the return value of \
* __switch_to()) \
*/ \
unsigned long ebx, ecx, edx, esi, edi; \
\
asm volatile("pushfl\n\t" /* 保存flags*/ \
"pushl %%ebp\n\t" /* 将当前ebp压栈 */ \
"movl %%esp,%[prev_sp]\n\t" /* 把当前ebp保存到当前进程中(prev->thread.sp) */ \
"movl %[next_sp],%%esp\n\t" /* 把下一个进程的esp的值赋给esp寄存器 */ \
"movl $1f,%[prev_ip]\n\t" /* 保存当前进程eip */ \
"pushl %[next_ip]\n\t" /* 把下一个进程的eip压入堆栈 */ \
__switch_canary \
"jmp __switch_to\n" /* regparm call */ \
"1:\t" /* 下一个进程开始执行 */
"popl %%ebp\n\t" /* restore EBP */ \
"popfl\n" /* restore flags */ \
\
/* output parameters */ \
: [prev_sp] "=m" (prev->thread.sp), \
[prev_ip] "=m" (prev->thread.ip), \
"=a" (last), \
\
/* clobbered output registers: */ \
"=b" (ebx), "=c" (ecx), "=d" (edx), \
"=S" (esi), "=D" (edi) \
\
__switch_canary_oparam \
\
/* input parameters: */ \
: [next_sp] "m" (next->thread.sp), \
[next_ip] "m" (next->thread.ip), \
\
/* regparm parameters for __switch_to(): */ \
[prev] "a" (prev), \
[next] "d" (next) \
\
__switch_canary_iparam \
\
: /* reloaded segment registers */ \
"memory"); \
} while (0)
#Linux系统的一般执行过程
最一般情况:正在运行的用户态进程X切换到运行用户态 进程Y的过程
1.正在运行的用户态进程X
2.发生中断——save cs:eip/esp/eflags(current) to kernel stack,then load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack).
SAVE_ALL //保存现场
- 正在运行的用户态进程X 发生中断——save cs:eip/esp/eflags(current) to kernel
- stack,then load cs:eip(entry of a specific ISR) and ss:esp(point to
- kernel stack). SAVE_ALL //保存现场
- 中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换
- 标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
- restore_all //恢复现场
- iret - pop cs:eip/ss:esp/eflags from kernel stack 继续运行用户态进程Y
特殊情况:
通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;
创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
加载一个新的可执行程序后返回到用户态的情况,如execve;
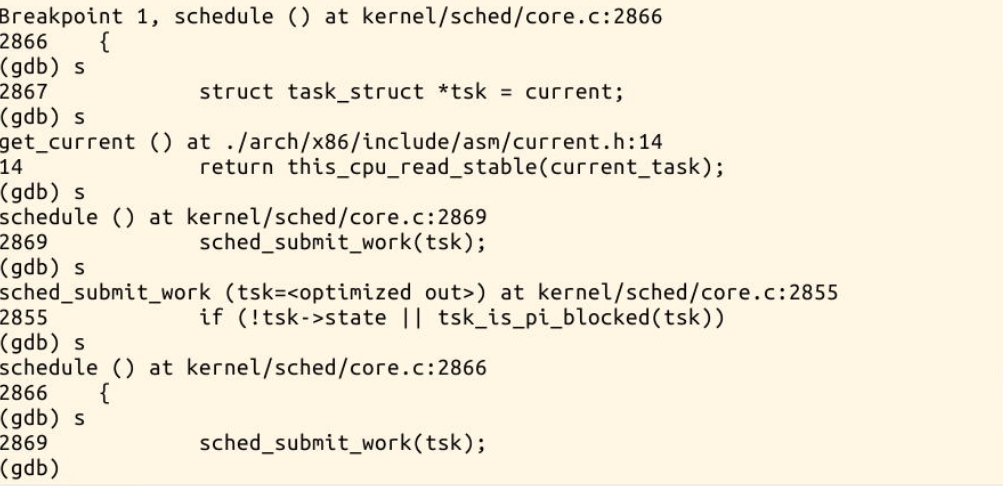
gdb

















 9172
9172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









