







下面以爬取智联招聘为例讲解下获取动态数据的一般步骤。
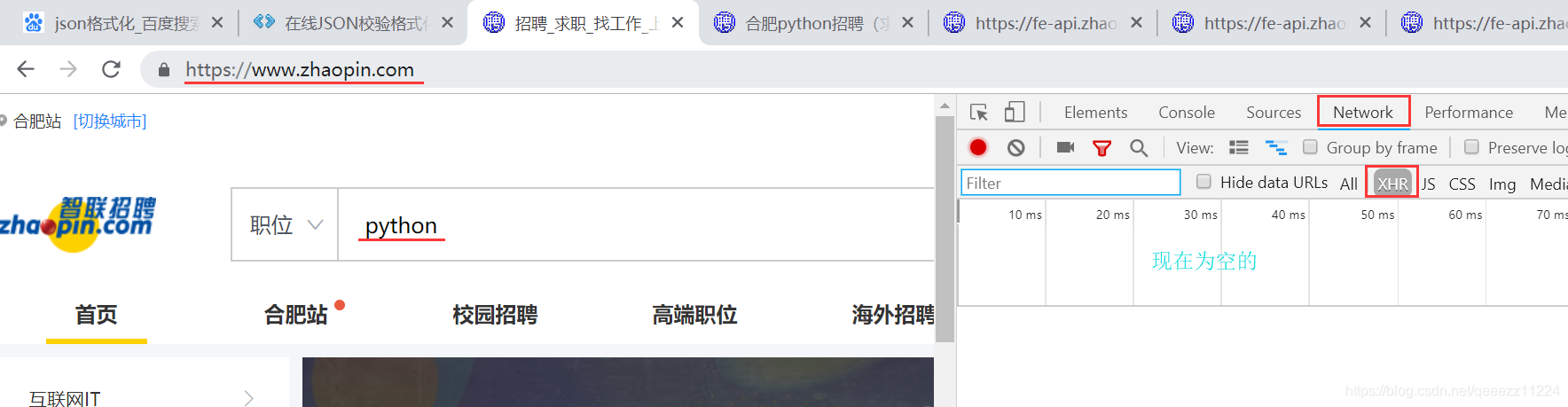
首先打开谷歌浏览器输入地址智联招聘地址https://www.zhaopin.com/数据页面,Fn+F12查看网页源代码,然后选择Network——>XHR,可以看到,现在里面什么都没有
然后点击谷歌浏览器的刷新按钮或者按F5刷新页面,可以看到,有一条数据出现了,这个链接就是获取数据的页面API,选择Response,可以看到,它是以Json格式返回的数据,我们需要的信息都在里面。
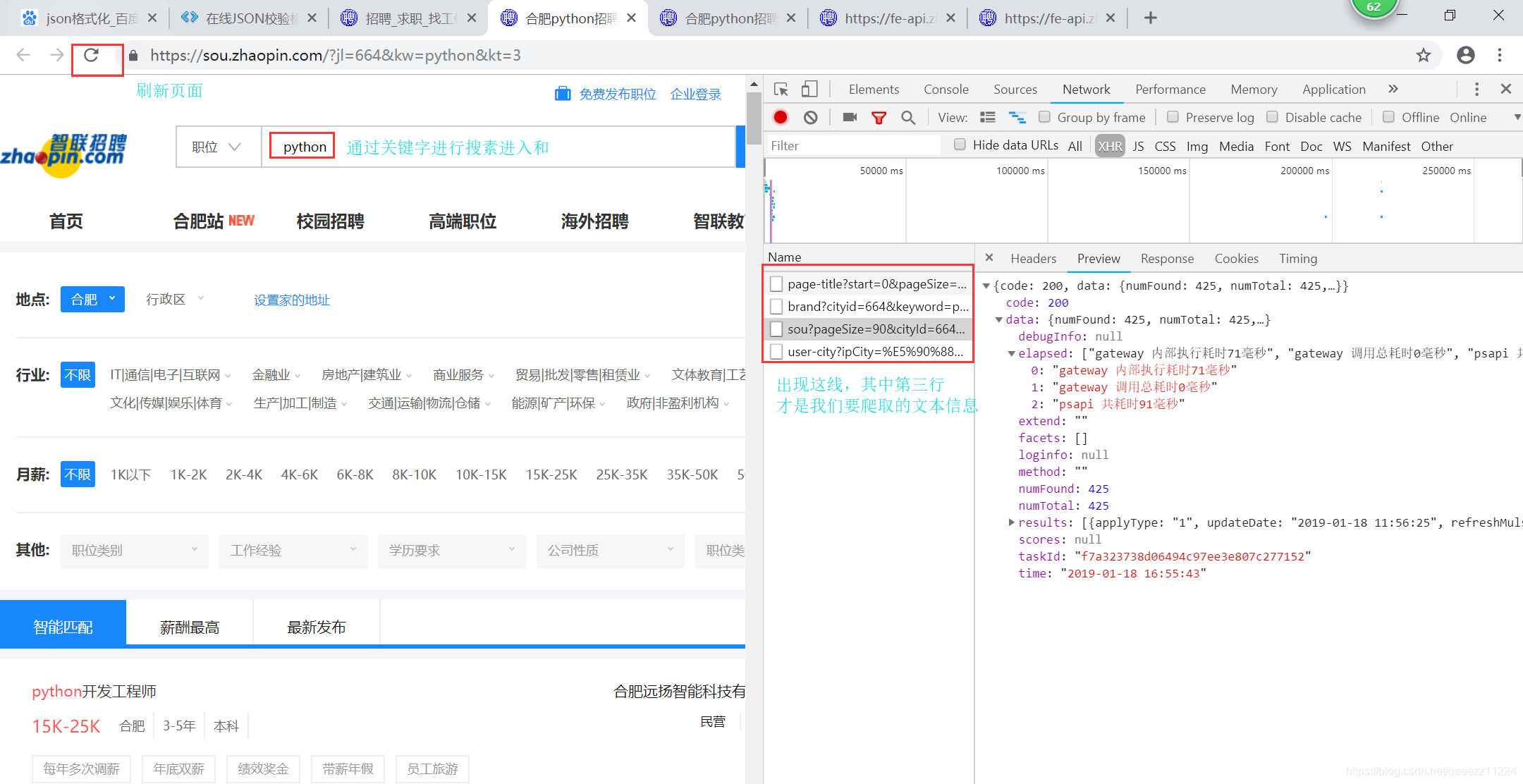
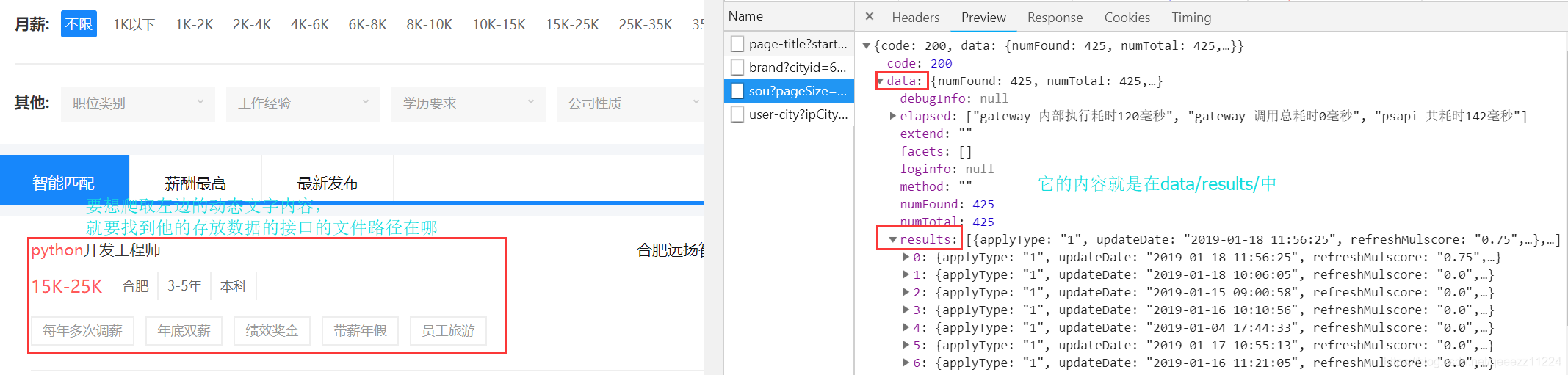
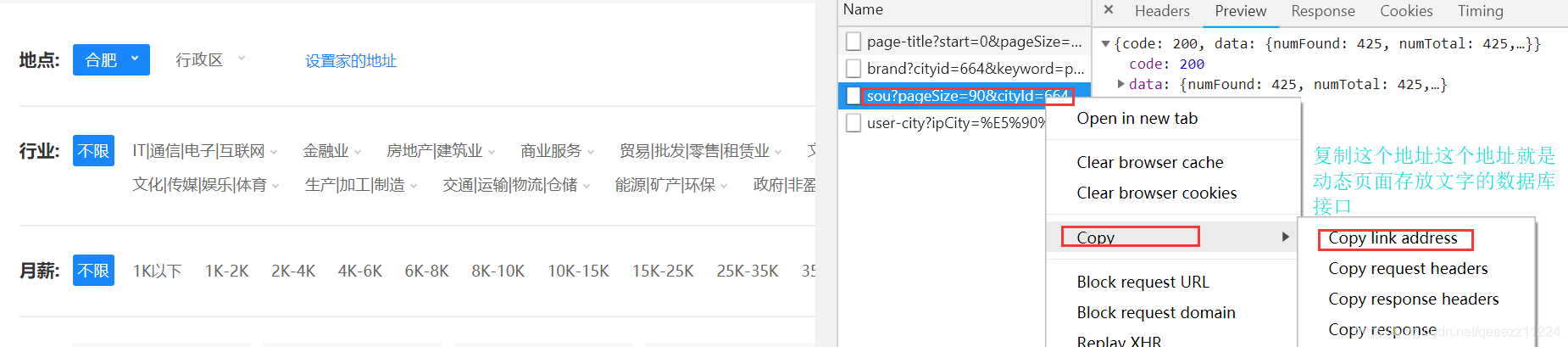
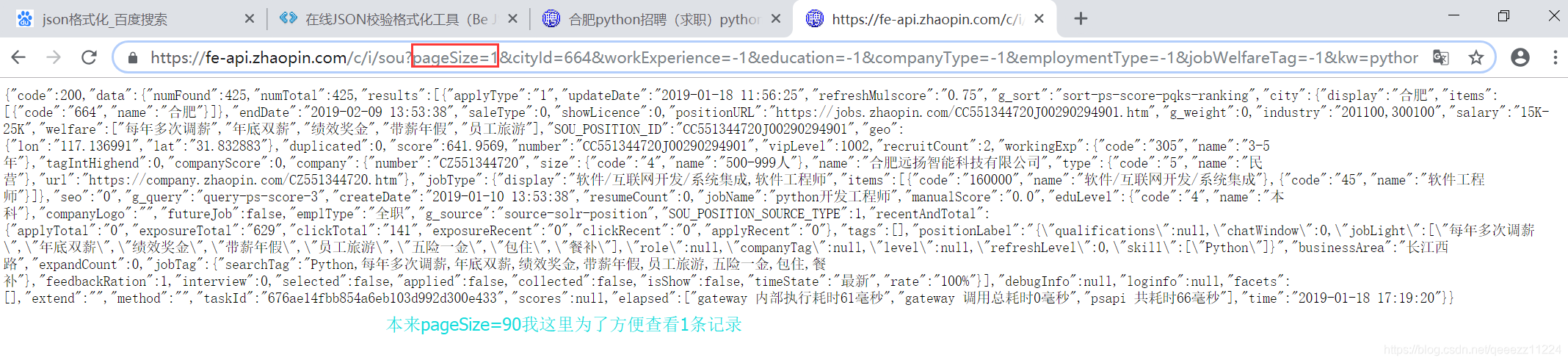
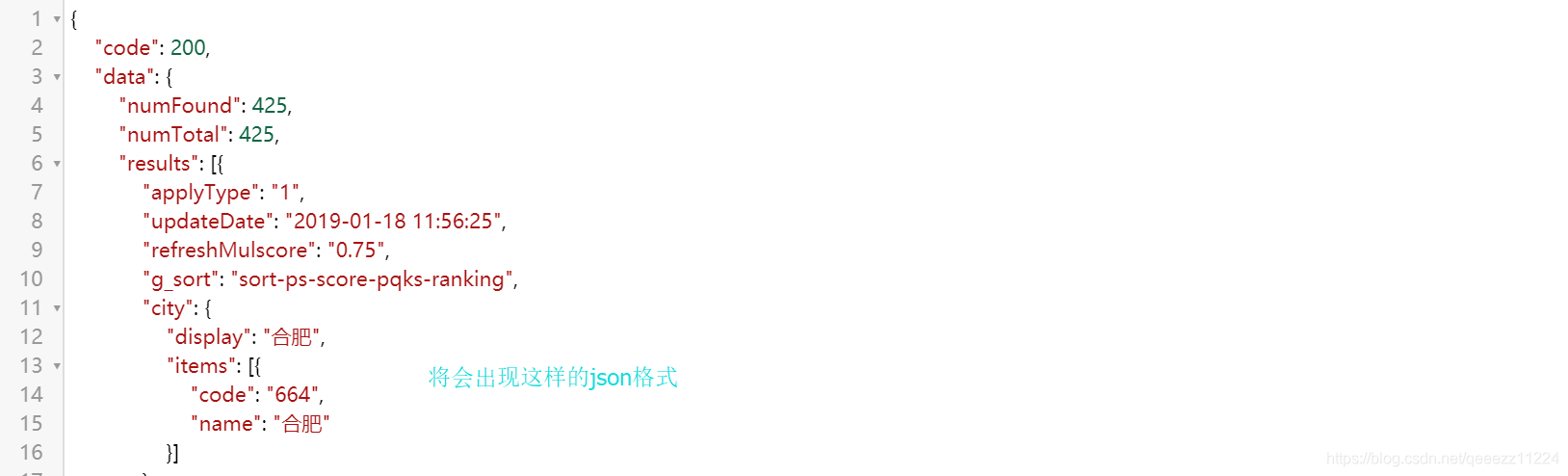
下面是动态爬取智联网站的内容代码因为我们爬取的内容在data/results:
# -*- coding:utf-8 -*-
import scrapy
import json
class ZhilianSpider(scrapy.Spider):
name = 'zhilian' #爬虫名称
start_urls = ['https://fe-api.zhaopin.com/c/i/sou?&pageSize=90&cityId=664&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&_v=0.84702683&x-zp-page-request-id=ac81a75ef7c147f6a9b40d272e978e7a-1547807209172-146763']
def parse(self, response):
json_body = json.loads(response.body)
json_data = json_body.get("data")
json_results = json_data.get("results")
for js in json_results:
city = js.get("city")["display"]
salary = js.get("salary")
jobName = js.get("jobName")
yield {
"city":city,
"salary":salary,
"jobName":jobName
}



实现第一页的动态90条数据的爬取















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









