









python自然语言处理
句子拆分器
sent_tokenize
from nltk.tokenize import sent_tokenize
inputstring='This is an example sent. The sen' \
'tence splitter will split on sent markers. Ohh really !!'
all_sent=sent_tokenize(inputstring)
print(all_sent)
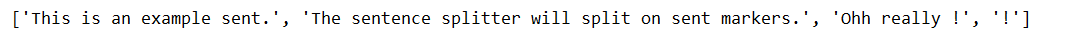
标记解析
regexp_tokenize,wordpunct_tokenize,blankline_tokenize
from nltk.tokenize import word_tokenize
print(word_tokenize(s))
from nltk.tokenize import regexp_tokenize,wordpunct_tokenize,blankline_tokenize
print(regexp_tokenize(s,pattern='\w+'))
print(regexp_tokenize(s,pattern='\d+'))
print(wordpunct_tokenize(s))
print(blankline_tokenize(s))
词干提取
LancasterStemmer,SnowballStemmer
'''词干提取'''
from nltk.stem import PorterStemmer
from nltk.stem.lancaster import LancasterStemmer
from nltk.stem.snowball import SnowballStemmer
pst=PorterStemmer()
lst=LancasterStemmer()
print(lst.stem('eating'))
print(pst.stem('shopping'))
词形还原
'''词形还原'''
from nltk.stem import WordNetLemmatizer
wlem=WordNetLemmatizer()
print(wlem.lemmatize('ate'))
停用词删除
'''停用词删除'''
from nltk.corpus import stopwords
stoplist=stopwords.words('english')
text='This is just a test'
cleanwordlist=[word for word in text.split() if word not in stoplist]
print(cleanwordlist)
拼写矫正
edit_distance
''''''
from nltk.metrics import edit_distance
print(edit_distance('rain','shine'))
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









