







数据是大数据时代互联网巨头们傲视群雄的秘密武器。当我们想要接触一个数据驱动型的新领域(如语音识别)时,往往囿于没有足够成熟的数据做实验而举步维艰。幸运的是,有很多机构将他们的成熟的数据公开出来,供我们学习、研究,TIMIT数据库就是其中之一。
TIMIT全称The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus, 是由德州仪器(TI)、麻省理工学院(MIT)和坦福研究院(SRI)合作构建的声学-音素连续语音语料库。TIMIT数据集的语音采样频率为16kHz,一共包含6300个句子,由来自美国八个主要方言地区的630个人每人说出给定的10个句子,所有的句子都在音素级别(phone level)上进行了手动分割,标记。70%的说话人是男性;大多数说话者是成年白人。
在给定的10个句子,包括:
- 2个方言句子(SA, dialect sentences),对于每个人这2个方言句子都是相同的;
- 5个音素紧凑句子(SX, phonetically compact sentences),这5个是从MIT所给的450个因素分布平衡的句子中选出,目的是为了尽可能的包含所有的音素对。
- 3个音素发散句子(SI, phonetically diverse sentences),这3个是由TI从已有的Brown 语料库(the Brown Coupus)和剧作家对话集(the Playwrights Dialog)中随机选择的,目的是为了增加句子类型和音素文本的多样性,使之尽可能的包括所有的音位变体(allophonic contexts)。
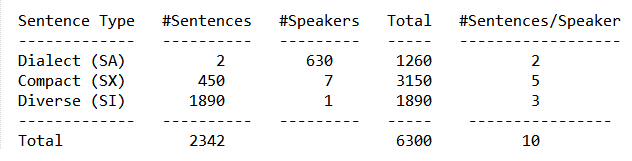
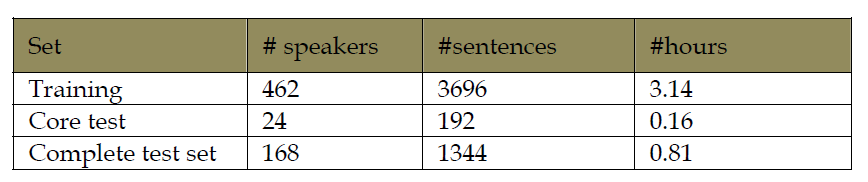
TIMIT官方文档建议按照7:3的比例将数据集划分为训练集(70%)和测试集(30%),但一般只用到SX和SI的句子,也就是说训练集包括由462个人所讲的3696个句子,全部测试集(complete test set)包括由168个人所讲的1344个句子,核心测试集(Core test)包括由24个所讲的192个句子,训练集和测试集没有重合。具体如下:
TIMIT的原始录音是基于61个音素的,如下所示:
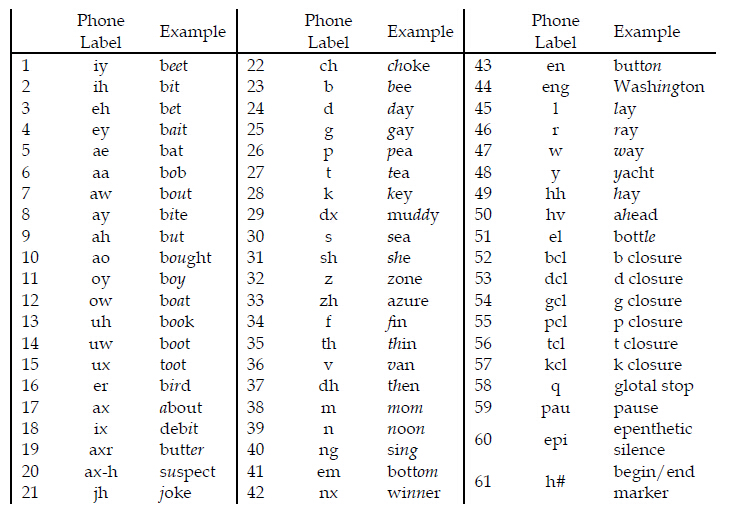
由于在实际中61个音素考虑的情况太多,因而在训练时有些研究者整合为48个音素,当评估模型时,李开复在他的成名作(Lee & Hon, 1989)所提出的将61个音素合并为39个音素方法被广为使用。
下面列出近年来在TIMIT数据库上进行语音识别实验的研究成果,有兴趣可以查看相关论文。
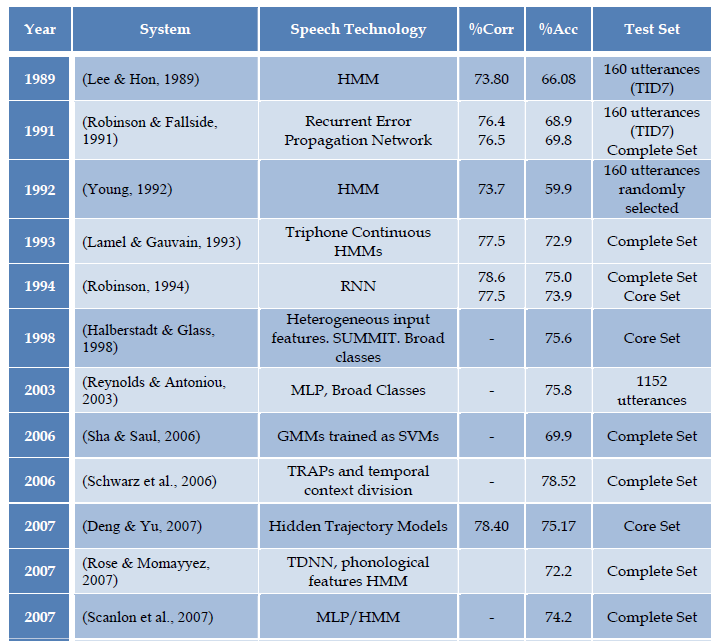
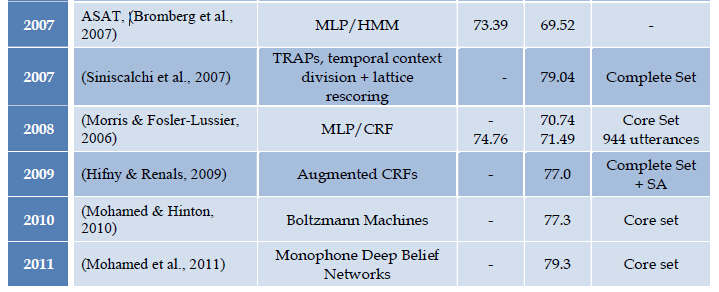
TIMIT语料库多年来已经成为语音识别社区的一个标准数据库,在今天仍被广为使用。其原因主要有两个方面:
- 数据集中的每一个句子都在音素级别上进行了手动标记,同时提供了说话人的编号,性别,方言种类等多种信息;
- 数据集相对来说比较小,可以在较短的时间内完成整个实验;同时又足以展现系统的性能。
下一篇: TIMIT数据库(二):文件目录及结构
参考文献:
- Lopes, Carla, and Fernando Perdigao. “Phone recognition on the TIMIT database.” Speech Technologies/Book 1 (2011): 285-302.
- Lee, K-F., and H-W. Hon. “Speaker-independent phone recognition using hidden Markov models.” IEEE Transactions on Acoustics, Speech, and Signal Processing 37.11 (1989): 1641-1648.
- Documentation for TIMIT
一、目录结构
目录组织形式如下:
/<语料库>/<用处>/<方言种类>/<性别><说话者ID>/<句子ID>.<文件类型>
在这里:
语料库:timit
用法:train | test
方言种类:dr1 | dr2 | dr3 | dr4 | dr5 | dr6 | dr7 | dr8
性别:m | f
说话者ID:<说话者缩写><0-9任意数字>
句子ID:<文本类型><句子编号>,其中,文本类型:sa | si | sx
文件类型:wav | txt | wrd | phn举例:
(1) /timit/train/dr1/fcjf0/sa1.wav
(2) /timit/test/df5/mbpm0/sx407.phn
二、文件类型
TIMIT语料库包括一些与话语句子相关的文件,除了语音波形文件(.wav)外,还包括对应的句子内容(.txt),经过时间对齐(time-aligned)的单词内容(.wrd),经过时间对齐(time-aligned)的音素内容(.phn)三种类型的文件。这些文件的格式如下:
<采样起始点> <采样结束点> <文本内容>
… … …
… … …
… … …
<采样起始点> <采样结束点> <文本内容>
在这里:
采样起始点:语音段的开始位置(整数)。对于每一个文件,第一个起始位置总是0。
采样结束点:语音段的结束位置(整数)。由于翻译方法(transcription
method)的使用,最后一个采样结束位置的值可能比对应的.wav文件。
文本内容:<完整句子> | <单词标签> | <音素标签>举例:(/timit/test/dr5/fnlp0/sa1.wav):
.txt:
0 61748 She had your dark suit in greasy wash water all year.
.wrd:
7470 11362 she
11362 16000 had
15420 17503 your
17503 23360 dark
23360 28360 suit
28360 30960 in
30960 36971 greasy
36971 42290 wash
43120 47480 water
49021 52184 all
52184 58840 year.phn:(开始和结束的静音区以h#标记,展示部分内容)
0 7470 h#
7470 9840 sh
9840 11362 iy
11362 12908 hv
12908 14760 ae
14760 15420 dcl
15420 16000 jh
16000 17503 axr
17503 18540 dcl
18540 18950 d
18950 21053 aa
21053 22200 r
22200 22740 kcl
22740 23360 k
参考文献:
1. Documentation for TIMIT

















 6894
6894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









