






走近Java
JRE:jvm + core lib
JDK:JRE + development kit
类文件结构 (字节码)
class文件是一组8个字节为基础单位的二进制流。当需要占用8个字节以上空间的数据项时,则会按照高位在前的方式分割成若干个8个字节进行存储。
两种数据类型:
无符号数,基本数据类型u1、u2、u4、u8,可用来描述数字、索引引用、数量值或者按照UTF-8编码构成字符串值。
表,由多个多个无符号数或其他表作为数据项构成的复合数据类型,习惯性以_info结尾,用于描述有层次关系的复合结构的数据,整个class文件本质上也可以视为一个表。
数据项:
u4,magic,1
u2,minor_version,1
u2,major_version,1
u2,constant_pool_count,1
cp_info,constant_pool,constant_pool_count-1
u2,access_flags,1
u2,this_class,1
u2,super_class,1
u2,interfaces_class,1
u2,interfaces,interfaces_count
u2,fields_count,1
fields_info,fields,fields_count
u2,methods_count,1
methods_info,methods,methods_count
u2,attributes_count,1
attribute_info,attributes,attributes_count
类加载机制(类加载器)
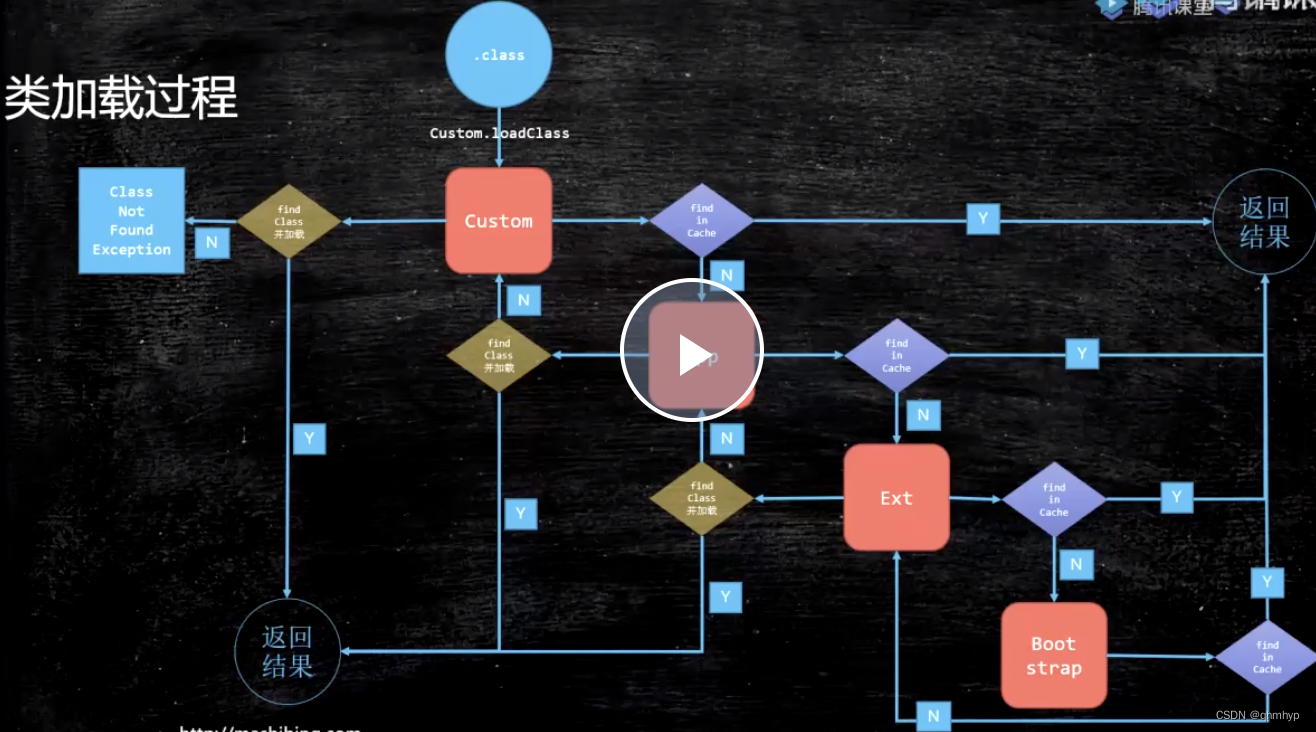
1. 类加载过程
- 加载:双亲委派模型,基于安全考虑设计(打破双亲委派机制:重写loadClass;)
- 连接:
- 验证:验证文件是否符合JVM规定
- 准备:静态变量赋默认值,静态字段、方法表
- 解析: 将类、文件、属性等符号引用解析为直接引用;常量池中的各种符号引用解析为指针、偏移量等内存地址的直接引用
- 初始化:调用类初始化代码,给静态成员变量赋初始值
2. 类加载时机
虚拟机启动,main方法所在类
new创建实例
调用静态方法
访问静态字段
初始化子类加载父类
接口定义default方法,实现时会初始化
反射API对某个类反射调用
初次调用实例
3. 什么时候不会初始化
子类引用父类静态字段,只会父类初始化
定义对象数组
常量编译期间,不会初始化所在类
通过类名访问,如A.class
Class.forName加载指定类(需指定初始化参数)
ClassLoader默认方法loadClass
4. 类加载器
三类加载器
启动类加载器BootStrapClassLoader
扩展类加载器ExtClassLoader
应用类加载器AppClassLoader
加载器特点
双亲委托
负责依赖
缓存加载
类启动加载器Bootstrap ClassLoader:C++实现
其他所有类加载器:

添加引用类的方法
放到JDK lib/ext下,或者-Djava.ext.dirs
java -cp/classpath 或者 class 文件放到当前路径
自定义ClassLoader加载
拿到当前执行类的ClassLoader,反射调用addUrl方法添加Jar或路径
JVM内存结构
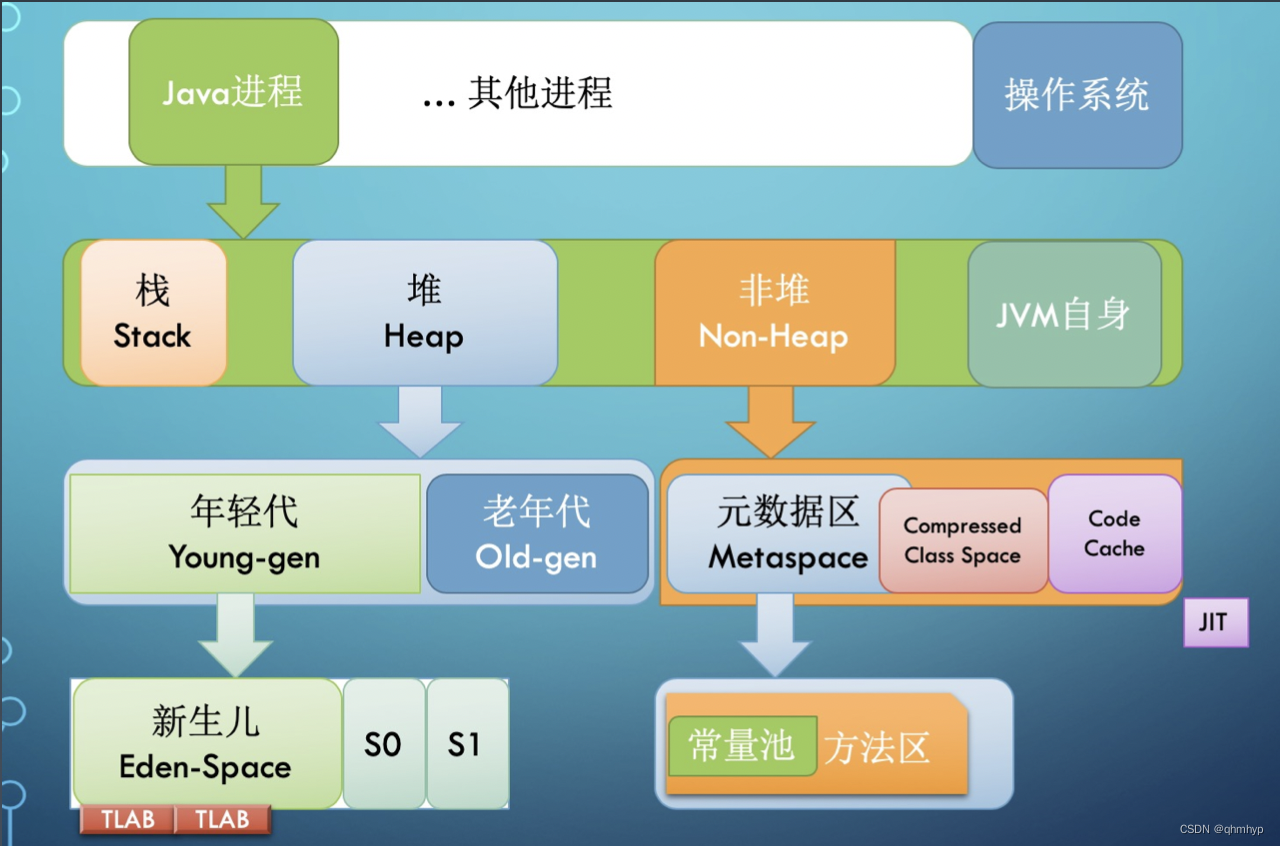
JVM栈内存结构
JVM堆内存结构
JVM内存模型
JMM 规范明确定义了不同的线程之 间,通过哪些方式,在什么时候可以 看见其他线程保存到共享变量中的 值;以及在必要时,如何对共享变量 的访问进行同步。这样的好处是屏蔽 各种硬件平台和操作系统之间的内存 访问差异,实现了 Java 并发程序真 正的跨平台。
后端编译与优化
混合执行:
编译执行:
解释执行:
检测热点代码:-XX:CompileThreshold = 10000
Java内存模型与线程
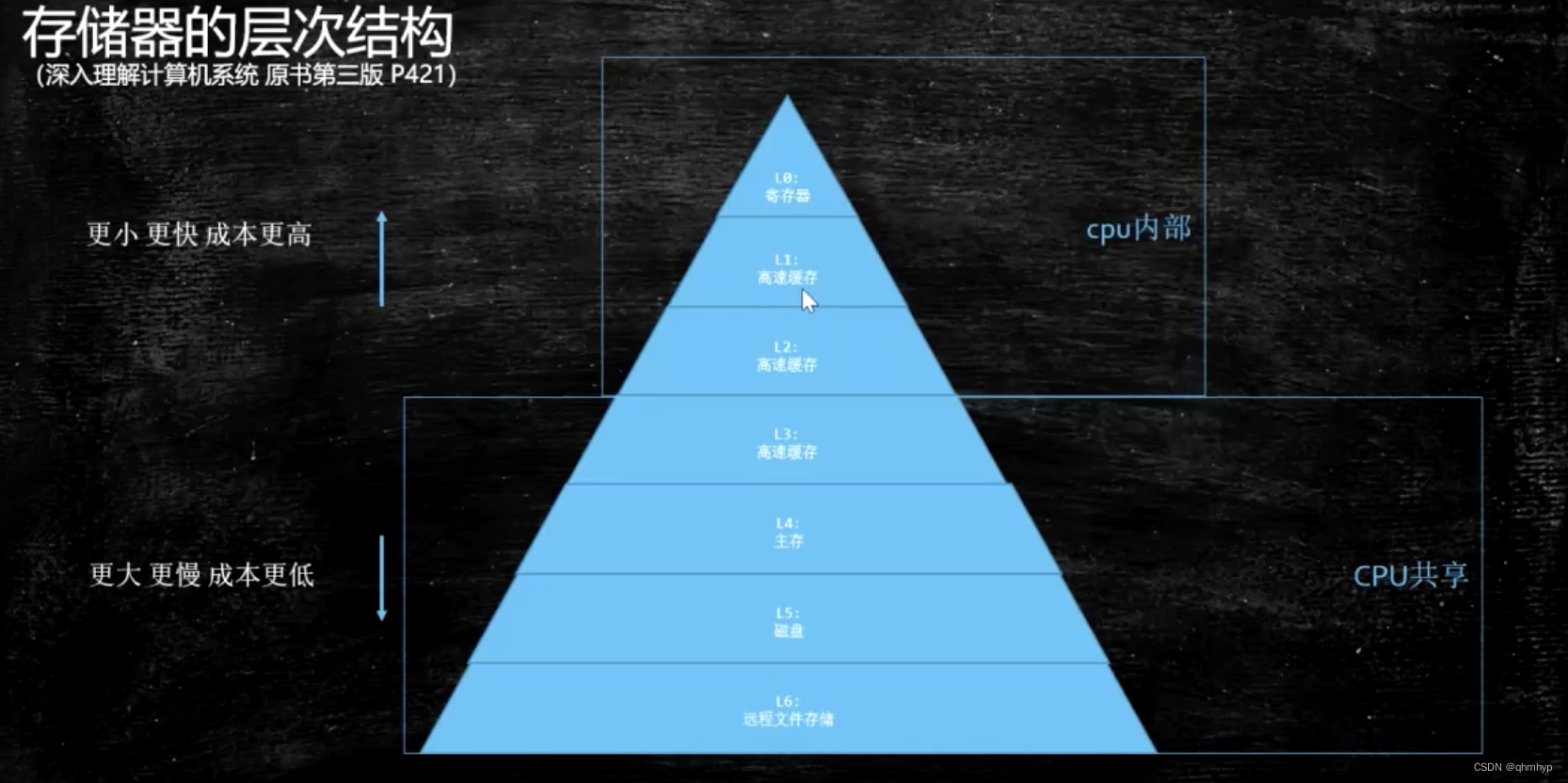

数据一致性
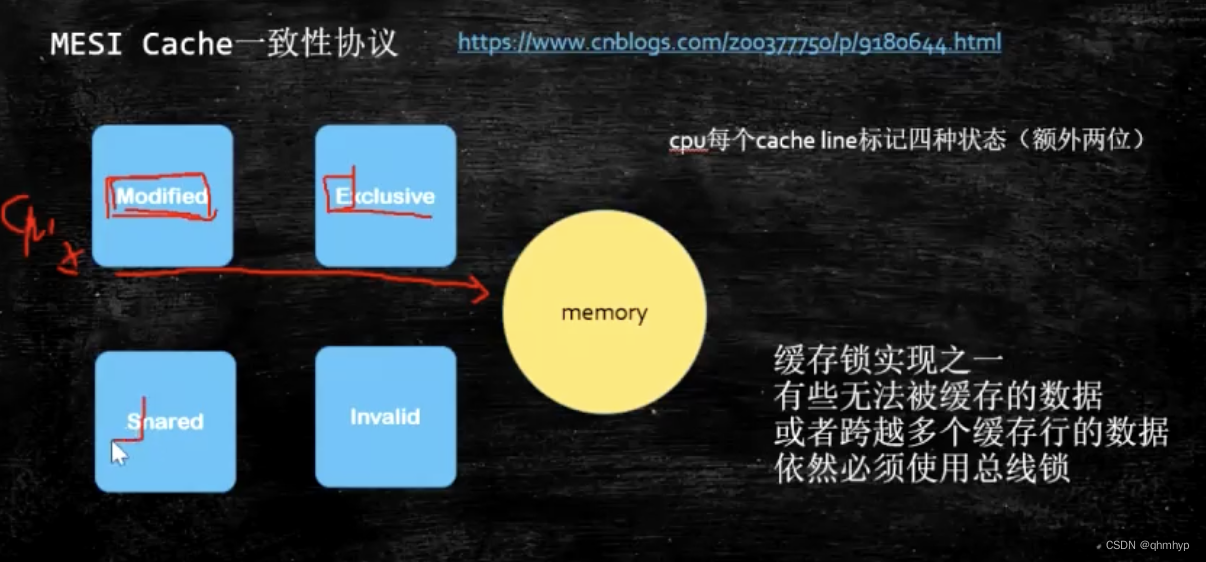
现代CPU的数据一致性实现 = 缓存锁MESI + 总线锁
读取缓存以cache line为基本单位,64字节
位于同一缓存的两个不同数据,被两个不同CPU锁定,产生互相影响的伪共享问题
使用缓存行的对齐能提高性能
乱序问题
CPU为提高指令执行效率,会在一条指令执行过程中,去同时执行另一条指令,前提是,两条指令没有依赖关系
WC BUffer 4 个字节,位于L1 和 CPU之间,提供合并写功能,增加写入操作性能。
解决乱序问题(保障有序性)
硬件内存屏障x86:
sfence:store fence,在sfence指令前的写操作必须在sfence指令后的写操作前完成
lfence:load fence,在lfence指令前的读操作必须在lfence指令后的读操作前完成
mfence:mix,在读写都保证
lock:一个Full Barrier
JVM级别规范:
LoadLoad屏障、StoreStore屏障、LoadStore屏障、StoreStore屏障
volatile实现细节:
字节码层面,加ACC_VOLATILE
JVM层面,写操作前后加StoreStore、StoreLoad屏障,读操作前后加LoadLoad、LoadStore屏障
OS和硬件层面,lock实现
synchronized实现细节:
字节码层面,加ACC_SYNCHRONIZED,monitorenter、monitorexit、monitorexit
JVM层面,C/C++调用了操作系统提供的同步机制
OS和硬件层面,x86,lock comxchg xxx
对象的内存布局
对象的创建过程
- class loading;
- class linking(verification,preparation,resolution)
- class initialzing
- 申请对象内存
- 成员变量赋默认值
- 调用构造方法:成员变量顺序赋初始值;执行构造方法语句。
对象在内存中的存储布局
观察虚拟机配置:java -XX:+PrintCommandLineFlags -version
普通对象
- 对象头:markword 8字节
- ClassPointer指针:-XX:-UseCompressedClassPointers为4字节,不开启为8字节
- 实例数据:成员变量
- Padding对齐,8的倍数
数组对象
- 对象头:markword 8字节
- ClassPointer指针:-XX:-UseCompressedClassPointers为4字节,不开启为8字节
- 数组长度:4字节
- 数组数据
- Padding对齐,8的倍数
Hotspot开启内存压缩的规则(64位机)
- 4G以下,直接砍掉高32位
- 4G - 32G,默认开启内存压缩 ClassPointers Oops
- 32G,压缩无效,使用64位 内存并不是越大越好
对象头包括什么
2位锁标志位,1位偏向锁标志,4位分代年龄(默认最多15岁),31位对象hashCode
对象定位
句柄池;
直接指针(HotSpot使用)
JVM运行时数据区域和JVM指令集
程序计数器
Java虚拟机栈
有多个栈帧frame:局部变量表、操作数栈、动态链接、方法出口
基于栈的指令集:JVM
基于寄存器的指令集:汇编,较快
store
load
pop
mul
sub
invoke
- InvokeStatic
- InvokeVirtual
- InvokeInterface
- InovkeSpecial 可以直接定位,不需要多态的方法 private 方法 , 构造方法
- InvokeDynamic JVM最难的指令 lambda表达式或者反射或者其他动态语言scala kotlin,或者CGLib ASM,动态产生的class,会用到的指令
本地方法栈
Java堆
方法区
Perm Space (<1.8) 字符串常量位于PermSpace FGC不会清理 大小启动的时候指定,不能变
Meta Space (>=1.8) 字符串常量位于堆 会触发FGC清理 不设定的话,最大就是物理内存
运行时常量池
直接内存
JVM可以直接访问的内核空间的内存(OS管理的内存)
NIO(New Input/Output)类,提高效率,实现zero copy
垃圾收集和垃圾回收
基本概念
寻找垃圾
引用计数Refence Count,无法解决循环引用(Python)
根可达算法Root Searching,根对象:线程栈变量、静态变量、常量池、Java Native InterfaceJNI指针
GC算法
Mark-Sweep标记清除:算法简单、存活对象比较多的情况效率高,两边扫描效率低、容易产生碎片
Copying拷贝:使用存活对象较少的情况、只扫描一次、效率高、没有碎片,浪费空间、移动复制对象需要调整对象引用。Eden
Mark-Compact标记压缩:不会产生碎片、方便对象分配、不会产生内存减半,扫描两次、需要移动对象效率偏低
对象分配
栈上分配:线程私有小对象、无逃逸、支持标量替换,无需调整
线程本地分配TLAB(Thread Local Allocation Buffer):占用eden默认1%、多线程时不用竞争eden就可以申请空间提高效率、小对象,无需调整
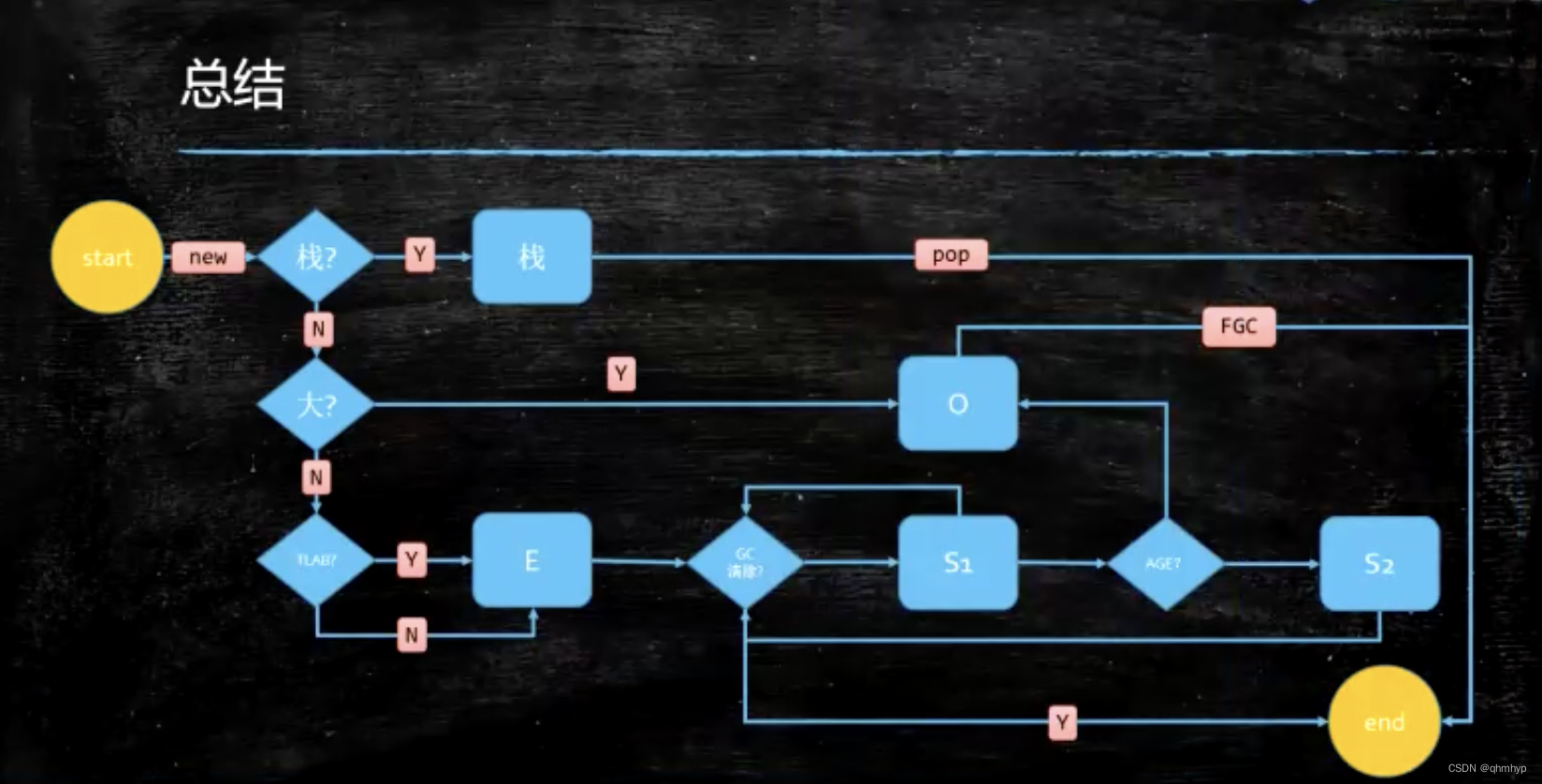
JVM内存分代模型
新生代 + 老年代 + 永久代(1.7)Perm Genaration/元数据区(1.8)Metaspace
- 永久代 元数据 - Class
- 永久代必须指定大小限制,元数据可以设置、默认无上限(受限于物理内存)
- 字符串常量 1.7 永久代,1.8 堆
- 方法区是逻辑概念 - 永久代、元数据、
常见垃圾回收器
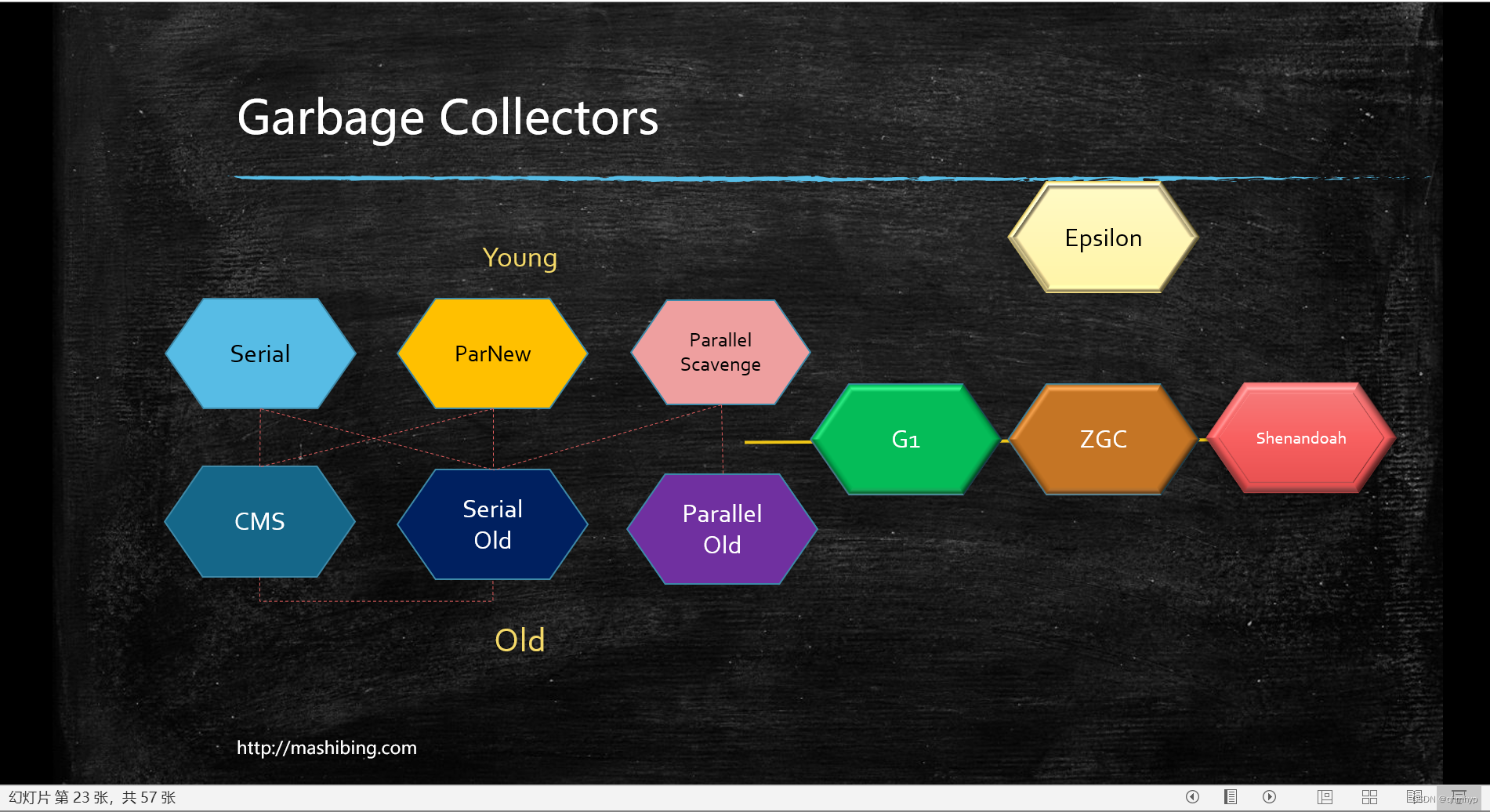
- JDK诞生 Serial追随 提高效率,诞生了PS,为了配合CMS,诞生了PN,CMS是1.4版本后期引入,CMS是里程碑式的GC,它开启了并发回收的过程,但是CMS毛病较多,因此目前任何一个JDK版本默认是CMS 并发垃圾回收是因为无法忍受STW
- Serial 年轻代 串行回收
- PS 年轻代 并行回收
- ParNew 年轻代 配合CMS的并行回收
- SerialOld
- ParallelOld
- ConcurrentMarkSweep 老年代 并发的, 垃圾回收和应用程序同时运行,降低STW的时间(200ms) CMS问题比较多,所以现在没有一个版本默认是CMS,只能手工指定 CMS既然是MarkSweep,就一定会有碎片化的问题,碎片到达一定程度,CMS的老年代分配对象分配不下的时候,使用SerialOld 进行老年代回收 想象一下: PS + PO -> 加内存 换垃圾回收器 -> PN + CMS + SerialOld(几个小时 - 几天的STW) 几十个G的内存,单线程回收 -> G1 + FGC 几十个G -> 上T内存的服务器 ZGC 算法:三色标记 + Incremental Update
- G1(10ms) 算法:三色标记 + SATB
- ZGC (1ms) PK C++ 算法:ColoredPointers + LoadBarrier
- Shenandoah 算法:ColoredPointers + WriteBarrier
- Eplison
JVM调优
常见垃圾回收器组合参数设定
JVM的位置
堆
打印GC回收信息
-Xms1024m -Xmx1024m -XX:PrintGCDetails
备份
-XX:+HeapDumpOnOutOfMemoryError
GC算法
标记复制算法(新生区):没有内存碎片,浪费内存空间,幸存区一半永远是空的。如果对象100%存活容易OOM,适合对象存活度低的场景
标记清除算法:不需要额外空间,两次扫描严删除线格式 重浪费时间,会产生内存碎片
标记整理算法:防止内存碎片产生,再次扫描,向一端移动存活的对象。多了一个移动成本。
内存效率:复制 > 整理 > 清除
内存整齐度:复制 = 整理 > 清楚
内存利用率:整理 = 清除 > 复制
JVM启动参数
-开头为标准参数,所有的 JVM 都要实现这些 参数,并且向后兼容。
-D 设置系统属性。
-X 开头为非标准参数, 基本都是传给 JVM 的, 默认 JVM 实现这些参数的功能,但是并不保证所 有 JVM 实现都满足,且不保证向后兼容。 可以使用 java -X 命令来查看当前 JVM 支持的非标准参数。
-XX:开头为非稳定参数, 专门用于控制 JVM的 行为,跟具体的 JVM 实现有关,随时可能会在下 个版本取消。
-XX:±Flags 形式, ± 是对布尔值进行开关。 -XX:key=value 形式, 指定某个选项的值。














 592
592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









