







背景
上周使用我的python web框架开发的第二个项目上线了,但是没运行几天机器内存就报警了,8G内存使用了7G,怀疑有内存泄漏,这个项目提供的功能就是一堆机器学习模型,对历史数据进行训练,挑选出最优的5个模型,用作未来数据的预测,所以整个项目有着数据量大,运行时间长的特点,就是把策略的离线工作搬到了线上。
定位内存泄漏
第一步:确定是否有内存泄漏
上pympler检查是否有内存泄漏,程序入口处初始化该工具
from pympler import tracker,summary,muppy
memory_tracker = tracker.SummaryTracker()
接口返回处打印内存差异,观察内存是否有泄漏
memory_tracker.print_diff() # 本次内存和上次内存块的差异
我们用的sanic,所以直接在main.py文件添加如下代码:
from pympler import tracker,summary,muppy
memory_tracker = tracker.SummaryTracker()
@app.middleware('request')
async def set_request_id(request):
log_id = request.headers.get('log-id')
threading.currentThread().logid = log_id
gc.collect()
memory_tracker.print_diff()
然后我们访问接口,多触发几次,不用看前两次,等输出稳定后,如果有内存泄漏是如下输出:

上图显示每次都有4类泄漏对象,一共泄漏约60K的内存
如果没有内存泄漏,没有数据输出

第二步:确定内心泄漏的代码块
我们确定程序有内存泄漏后,就想办法定位到代码块,就是我们自己写的代码,通过一步一步debug,注释,return,continue等方式定位到造成泄漏的代码块,下面的代码块就是遍历所有模型,然后挨个执行训练方法,因为有20多个模型,我不能挨个注释每次对象来定位,卡在这里了。
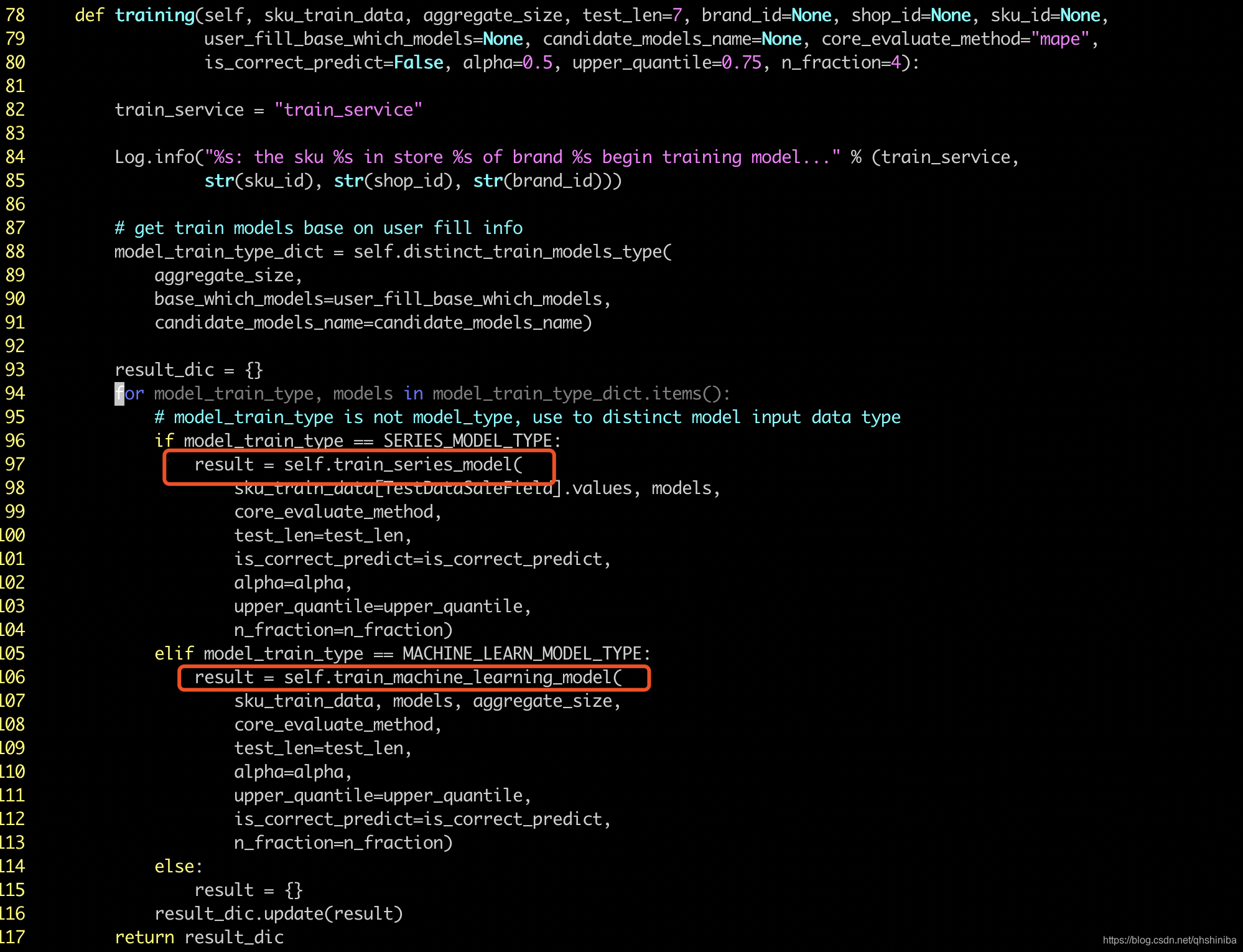
第三步:确定泄漏点
上tracemalloc定位泄漏点,python3.7.3自带,在main.py中添加如下代码:
tracemalloc.start(25)
snapshot = tracemalloc.take_snapshot()
@app.middleware('response')
async def print_on_response(request, response):
global snapshot
gc.collect()
snapshot1 = tracemalloc.take_snapshot()
top_stats = snapshot1.compare_to(snapshot, 'lineno')
print("[ Top 10 differences ]")
for stat in top_stats[:10]:
if stat.size_diff < 0:
continue
print(stat)
snapshot = tracemalloc.take_snapshot()
继续访问接口,多访问几次,输出如下,直接定位到具体泄漏的代码位置
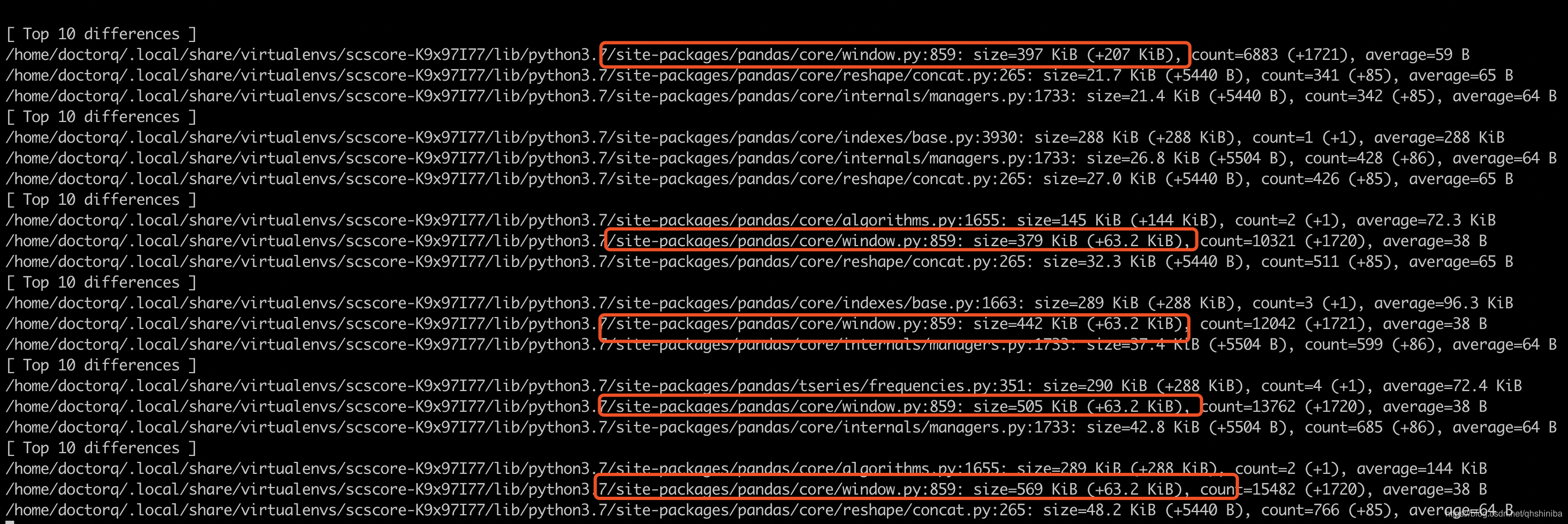
图中所有的泄漏点都定位到pandas库,但是我用这些文件搜索内存泄漏,都没有搜到相关内存泄漏的问题,所以得寻找谁调用这些地方,以/home/doctorq/.local/share/virtualenvs/scscore-K9x97I77/lib/python3.7/site-packages/pandas/core/window.py:859为例,我们要找到我们写的代码哪里调用触发泄漏点
第四步:打印调用链
看了tracemalloc文档也没找到打印调用链的方法,后来灵机一动直接在这个文件加了下面代码:
raise Exception("doctorq")
然后在接口里catch异常,添加logging.exception(e),然后触发接口,打印堆栈信息:
ERROR:root:doctorq
Traceback (most recent call last):
File "/home/doctorq/python-dev/scscore/src/forecasting/forecast.py", line 83, in update_method
n_fraction=n_fraction)
File "/home/doctorq/python-dev/scscore/src/forecasting/trainer.py", line 113, in training
n_fraction=n_fraction)
File "/home/doctorq/python-dev/scscore/src/forecasting/trainer.py", line 205, in train_machine_learning_model
is_train=True).dropna()
File "/home/doctorq/python-dev/scscore/src/feature_engineering/features.py", line 34, in get_feature
history_same_periods=history_same_periods, zero_replace=zero_replace)
File "/home/doctorq/python-dev/scscore/src/feature_engineering/sale_relate_feature.py", line 65, in get_feature
store_and_sku=store_and_sku)
File "/home/doctorq/python-dev/scscore/src/feature_engineering/sale_relate_feature.py", line 85, in get_rolling_feature
rolling_result = self.get_rolling_result(window, rolling_obj, rolling_types)
File "/home/doctorq/python-dev/scscore/src/feature_engineering/sale_relate_feature.py", line 169, in get_rolling_result
rolling_result = self.rolling__(rolling_obj, rolling_type)
File "/home/doctorq/python-dev/scscore/src/feature_engineering/sale_relate_feature.py", line 190, in rolling__
return rolling_obj.min()
File "/home/doctorq/.local/share/virtualenvs/scscore-K9x97I77/lib/python3.7/site-packages/pandas/core/window.py", line 1723, in min
return super(Rolling, self).min(*args, **kwargs)
File "/home/doctorq/.local/share/virtualenvs/scscore-K9x97I77/lib/python3.7/site-packages/pandas/core/window.py", line 1069, in min
return self._apply('roll_min', 'min', **kwargs)
File "/home/doctorq/.local/share/virtualenvs/scscore-K9x97I77/lib/python3.7/site-packages/pandas/core/window.py", line 879, in _apply
result = np.apply_along_axis(calc, self.axis, values)
File "/home/doctorq/.local/share/virtualenvs/scscore-K9x97I77/lib/python3.7/site-packages/numpy/lib/shape_base.py", line 380, in apply_along_axis
res = asanyarray(func1d(inarr_view[ind0], *args, **kwargs))
File "/home/doctorq/.local/share/virtualenvs/scscore-K9x97I77/lib/python3.7/site-packages/pandas/core/window.py", line 875, in calc
closed=self.closed)
File "/home/doctorq/.local/share/virtualenvs/scscore-K9x97I77/lib/python3.7/site-packages/pandas/core/window.py", line 858, in func
raise Exception("doctorq")
Exception: doctorq
定位到我们代码触发点如下:
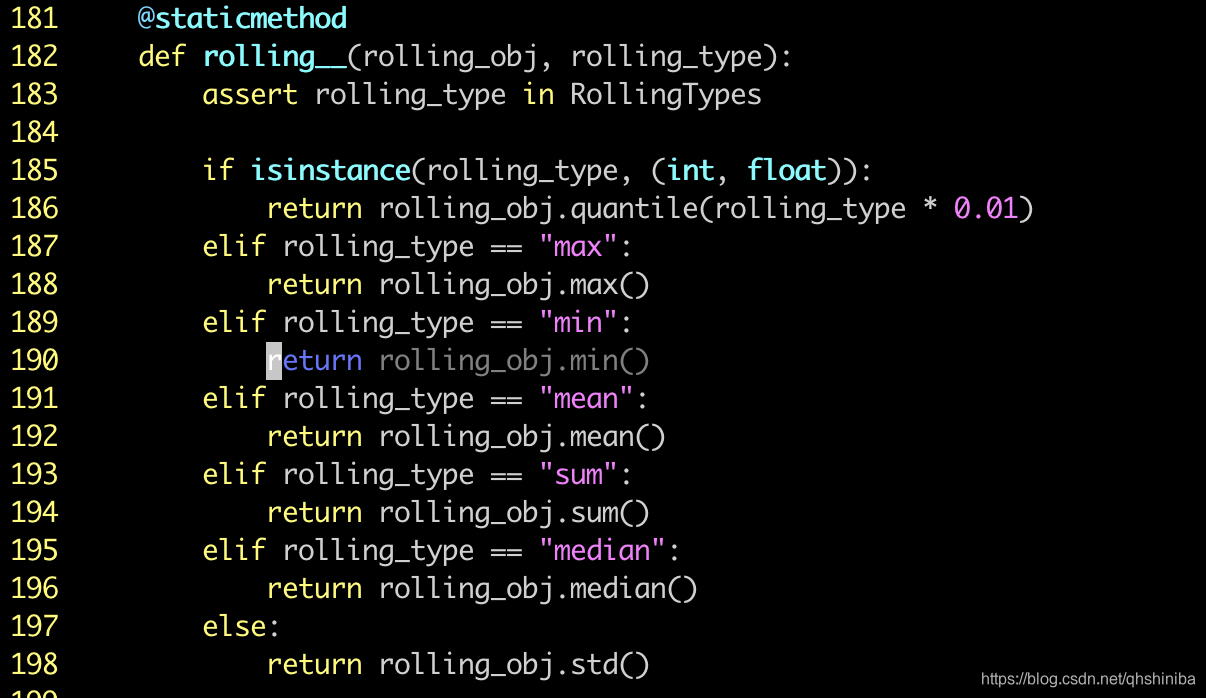
调用的就是pandas的Rolling的一系列方法,然后搜索该方法是否有泄漏问题
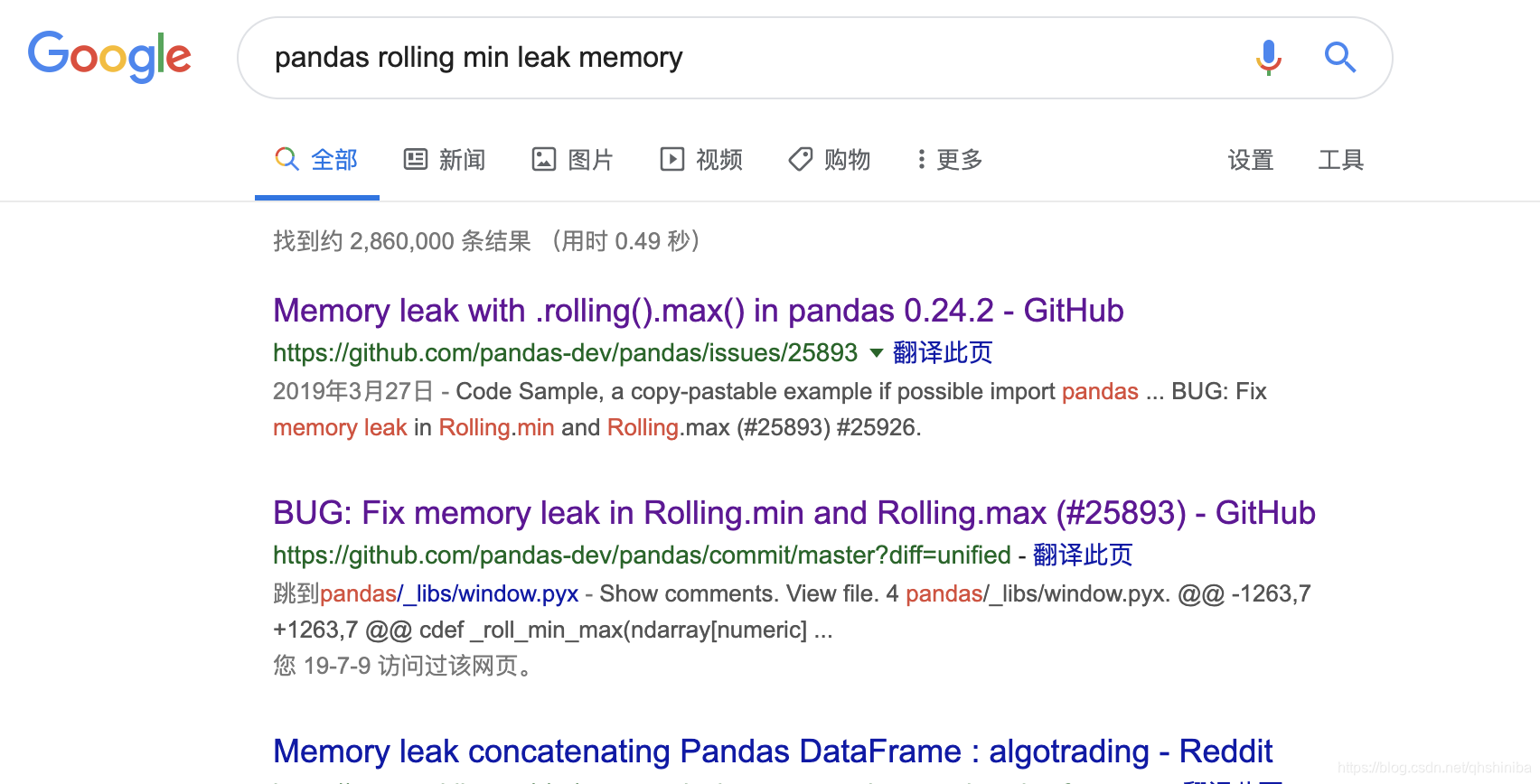
第一个链接链接就是说这些方法(rolling.min/max)有泄漏,pandas rolling max leak memory,具体因为啥泄漏的,也没时间细究,反正issue里说回退到0.23.4是没问题的,那么就回退试试:
pipenv install pandas==0.23.4
然后我们再用pympler定位有没有内存泄漏,pandas内存泄漏的问题是修复,剩下来就省memoryview的小泄漏了,明天继续

总结
定位的过程略耗时,不过经过这么一折腾,也算是有经验了,各种工具一阵堆,泄漏问题确定-定位代码块-定位泄漏点-搜索已知泄漏点-解决掉。














 2918
2918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









