




 本文介绍了Sqoop在Hadoop生态中的角色及其实现数据迁移的方法。涵盖了从关系型数据库到HDFS、Hive、HBase的数据导入过程及反向导出至关系型数据库的技术细节。
本文介绍了Sqoop在Hadoop生态中的角色及其实现数据迁移的方法。涵盖了从关系型数据库到HDFS、Hive、HBase的数据导入过程及反向导出至关系型数据库的技术细节。
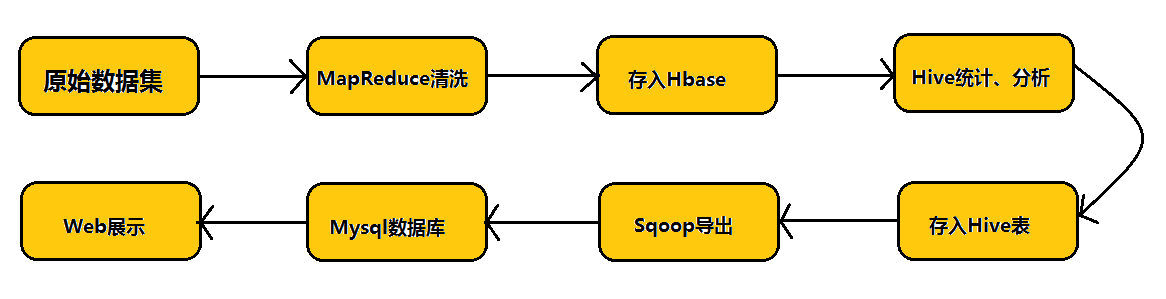
本篇文章在具体介绍Sqoop之前,先给大家用一个流程图介绍Hadoop业务的开发流程以及Sqoop在业务当中的实际地位。
如上图所示:在实际的业务当中,我们首先对原始数据集通过MapReduce进行数据清洗,然后将清洗后的数据存入到Hbase数据库中,而后通过数据仓库Hive对Hbase中的数据进行统计与分析,分析之后将分析结果存入到Hive表中,然后通过Sqoop这个工具将我们的数据挖掘结果导入到MySql数据库中,最后通过Web将结果展示给客户。
向大家展示完Hadoop业务开发流程之后,将进入到本篇文章的正题—-Sqoop架构以及应用的介绍。
(一)Sqoop架构介绍
1、Sqoop的概念
Sqoop:SQL–to–Hadoop
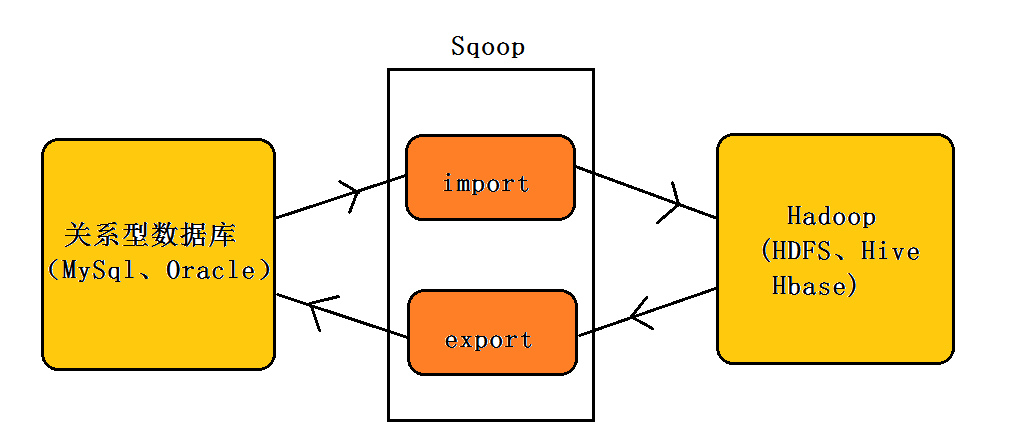
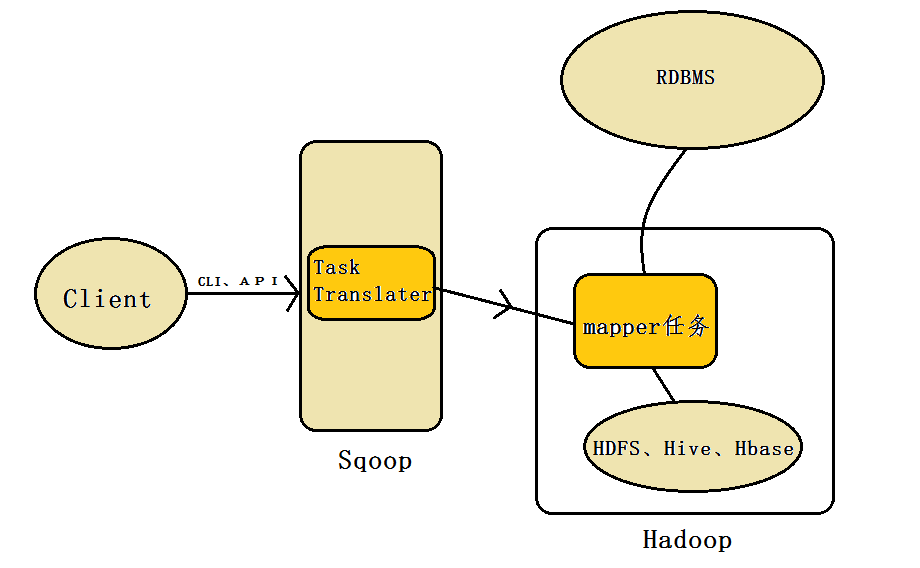
正如Sqoop的名字所示:Sqoop是一个用来将关系型数据库和Hadoop中的数据进行相互转移的工具,可以将一个关系型数据库(例如Mysql、Oracle)中的数据导入到Hadoop(例如HDFS、Hive、Hbase)中,也可以将Hadoop(例如HDFS、Hive、Hbase)中的数据导入到关系型数据库(例如Mysql、Oracle)中。如下图所示:
2、Sqoop架构
Sqoop架构:
正如上图所示:Sqoop工具接收到客户端的shell命令或者Java api命令后,通过Sqoop中的任务翻译器(Task Translator)将命令转换为对应的MapReduce任务,而后将关系型数据库和Hadoop中的数据进行相互转移,进而完成数据的拷贝。
(二)Sqoop应用介绍
Sqoop作为一个数据转移工具,必须要掌握其具体用法,下面将围绕Sqoop import to HDFS、增量导入、批脚本执行、Sqoop import to Hive、Sqoop import to Hbase、Sqoop export 几个方面进行介绍。
1、Sqoop import to HDFS
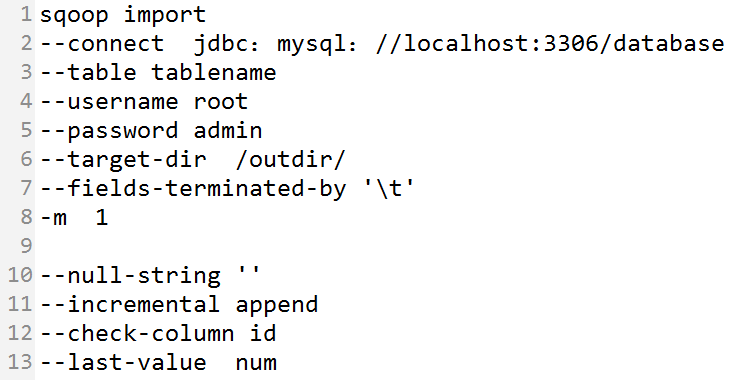
说明:
- -connect:指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
- -table:指的是要读取数据库database中的表名
- -username - -password:指的是Mysql数据库中的用户名和密码
- -target-dir:指的是HDFS中导入表的存放目录(注意:是目录)
- -fields-terminated-by :设定导入数据后每个字段的分隔符
-m:并发的map数量
- -null-string:导入的字段为空时,用指定的字符进行替换
- -incremental append:增量导入
- -check-column:指定增量导入时的参考列
- -last-value:上一次导入的最后一个值
下面给大家举一个例子进行相应说明:对于Mysql数据库,将hive数据库中的consumer表通过sqoop导入到HDFS中
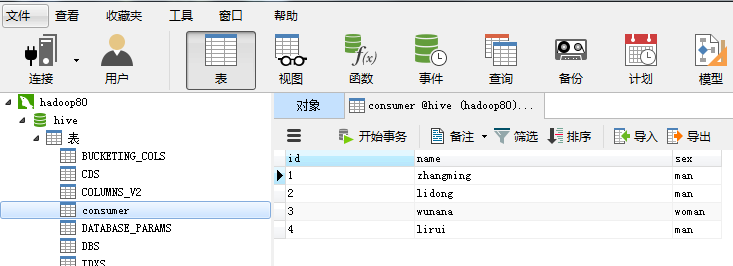
shell命令:
- 1
运行结果如下图所示:
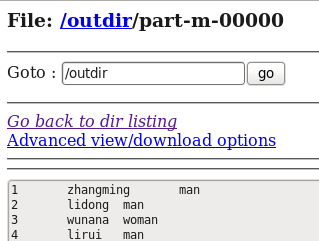
通过Sqoop这个工具就将我们Mysql数据库中的数据导入到了HDFS中,上面的shell命令类似我们下面的shell操作:
- 1
2、增量导入
在实际的工作当中都是数据库的表中数据不断增加的,比如刚才的consumer表,因此每次导入的时候只想导入增量的部分,不想将表中的数据在重新导入一次(费时费力),即如果表中的数据增加了内容,就向Hadoop中导入一下,如果表中的数据没有增加就不导入—–这就是增量导入。
- -incremental append:增量导入
- -check-column:(增量导入时需要指定增量的标准—哪一列作为增量的标准)
- -last-value:(增量导入时必须指定参考列—–上一次导入的最后一个值,否则表中的数据又会被重新导入一次)
以刚才的consumer表为例,我们向consumer表中增加两条记录,如下图所示:
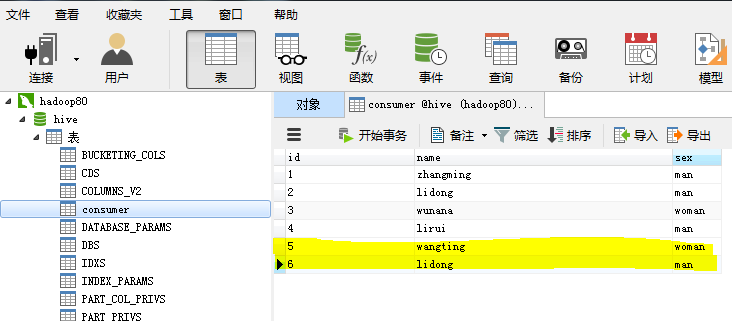
shell的增量操作:
- 1
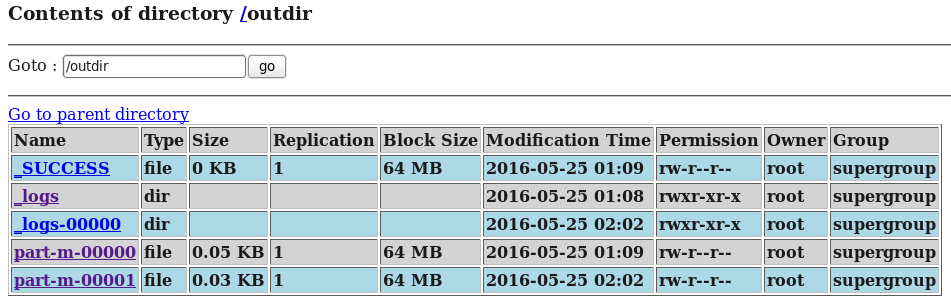
增量导入的结果如下图所示:
从运行结果可以看出,输出结果多了一个part-m-00001,而该文件中所包含的内容为:
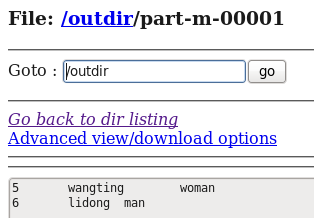
文件中的内容正是刚刚我们新增加的两条记录。
3、批量导入
从上面导入的命令可以看出,命令行包含的命令太多了,太麻烦了,因此如果类似的作业太多的话,我们应该将其设置为一个作业,做成一个脚本文件。
创建批脚本作业的shell命令:
- 1
通过sqoop job –list可以查看生成的批脚本文件:

通过sqoop job –exec 即可运行我们刚才生成的脚本文件,将我们Mysql数据库中的consumer表中的数据导入到HDFS中,而不需要每次都写很长的命令来运行。
4、Sqoop import to hive
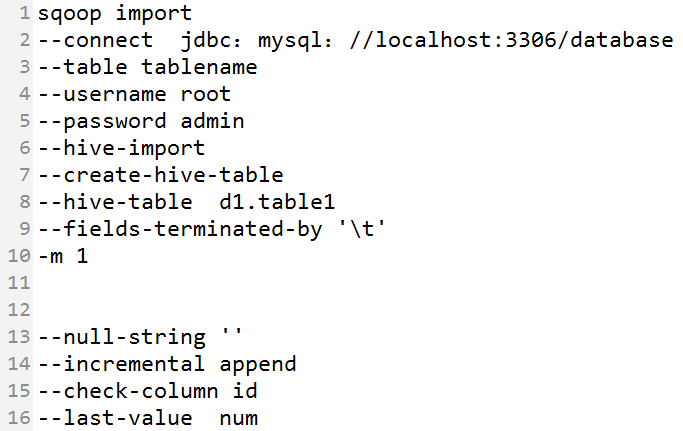
说明:
- -connect:指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
- -table:指的是要读取数据库database中的表名
- -username - -password:指的是Mysql数据库中的用户名和密码
- -hive-import 指的是将数据导入到hive数据仓库中
- -create-hive-table 创建表,注意:如果表已经存在就不用写这个命令了,否则会报错
- -hive-table 指定databasename.tablename (哪个数据库中的哪个表)
- -fields-terminated-by :设定导入数据后每个字段的分隔符
-m:并发的map数量
- -null-string:导入的字段为空时,用指定的字符进行替换
- -incremental append:增量导入
- -check-column:指定增量导入时的参考列
- -last-value:上一次导入的最后一个值
同样,下面给大家举一个例子进行相应的说明:对于Mysql数据库,将hive数据库中的consumer表通过sqoop导入到Hive数据仓库中
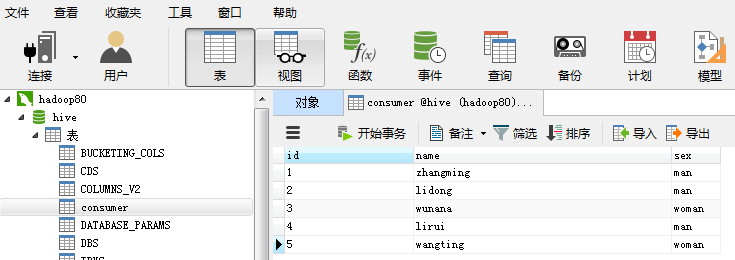
shell命令操作:
- 1
运行结果如下图所示:
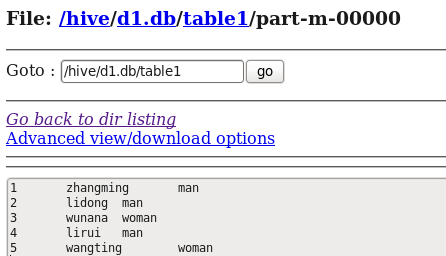
通过Sqoop这个工具就将我们Mysql数据库中的数据导入到了Hive数据仓库中,上面的shell命令类似我们下面的shell操作:
- 1
即本质上通过sqoop这个工具完成的就是一个数据的拷贝工作。
注:如果我们对sqoop import to hive不熟悉的话,我们可以先将数据库中的数据导入到HDFS的指定目录下,然后在Hive中创建一个外部表关联这个指定目录即可。
5、Sqoop import to hbase
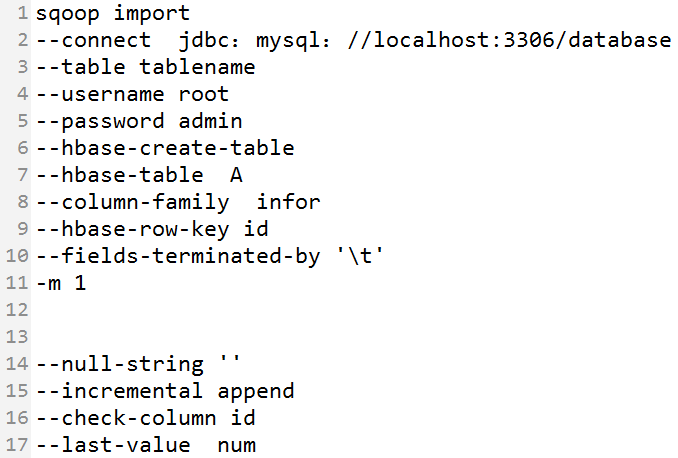
说明:
- -connect:指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
- -table:指的是要读取数据库database中的表名
- -username - -password:指的是Mysql数据库中的用户名和密码
- -hbase-create-table:表示在hbase中建立表
- -hbase-table A:指定在hbase中建立表A
- -column-family infor:表示在表A中建立列族infor。
- -hbase-row-key :表示表A的row-key是consumer表的id字段
-m:并发的map数量
- -null-string:导入的字段为空时,用指定的字符进行替换
- -incremental append:增量导入
- -check-column:指定增量导入时的参考列
- -last-value:上一次导入的最后一个值
下面给大家举一个例子进行相应的说明:对于Mysql数据库,将hive数据库中的consumer表通过sqoop导入到Hbase中:
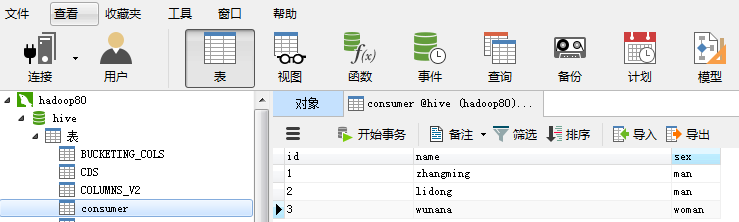
shell命令:
- 1
运行结果如下:
通过Sqoop这个工具就将我们Mysql数据库中的数据导入到了Hbase中,上面的shell命令类似我们下面的shell操作:

- 1
5、Sqoop export
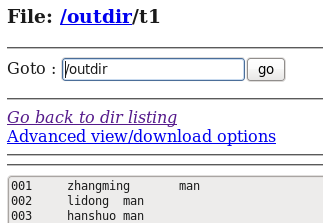
下面给大家举一个例子进行相应的说明:假设将HDFS中的t1表通过sqoop导入到Mysql中的consumer表(事先必须存在):
HDFS中t1表的内容:
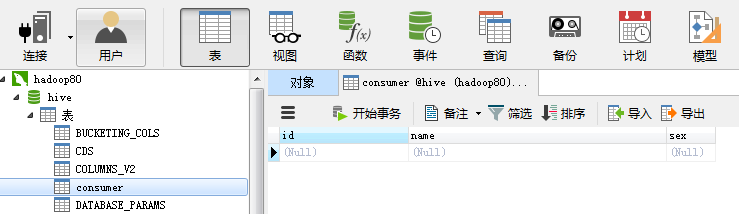
MySql中已经创建好的consumer表:
shell命令如下:
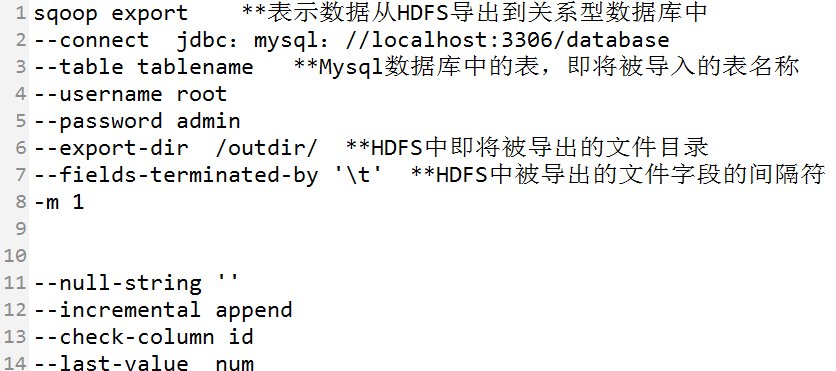
- 1
运行结果,数据从HDFS的t1文件中成功的导入到了Mysql中的consumer表中:
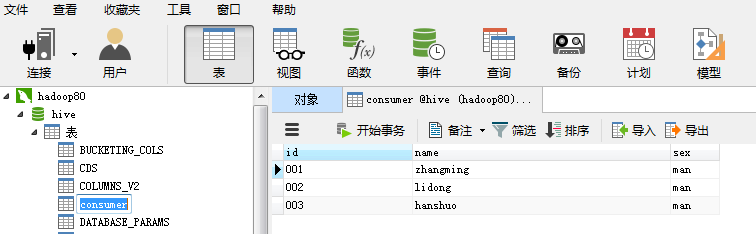
注:从Hadoop向数据库中导入数据时,数据库中相应的表事先必须创建好。
(三)总结
Sqoop作为一个用来将关系型数据库和Hadoop中的数据进行相互转移的工具,对于我们来说更重要的在于灵活的运用这个工具。

















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









