






1 sqoop原理
1.1 sqoop介绍
Sqoop是Apache旗下的一款“hadoop和关系型数据库服务器之间传送数据”的工具。 导入数据:MySQL、Oracle导入数据到hadoop的hdfs、hive、hbase等数据存储系统。 导出数据:从hadoop的文件系统中导出数据到关系型数据库中。

1.2 sqoop架构
-
导入流程
-
首先通过jdbc读取关系型数据库元数据信息,获取到表结构。
-
根据元数据信息生成Java类。
-
启动import程序,通过jdbc读取关系型数据库数据,并通过上一步的Java类进行序列化。
-
MapReduce并行写数据到Hadoop中,并使用Java类进行反序列化。
-
-
导出流程
-
sqoop通过jdbc读取关系型数据库元数据,获取到表结构信息,生成Java类,用于序列化。
-
MapReduce并行读取hdfs数据,并且通过Java类进行序列化。
-
export程序启动,通过Java类反序列化,同时启动多个map,通过jdbc将数据写入到关系型数据库中。
-
2 cdh部署sqoop
1)添加服务

2)添加gateway节点
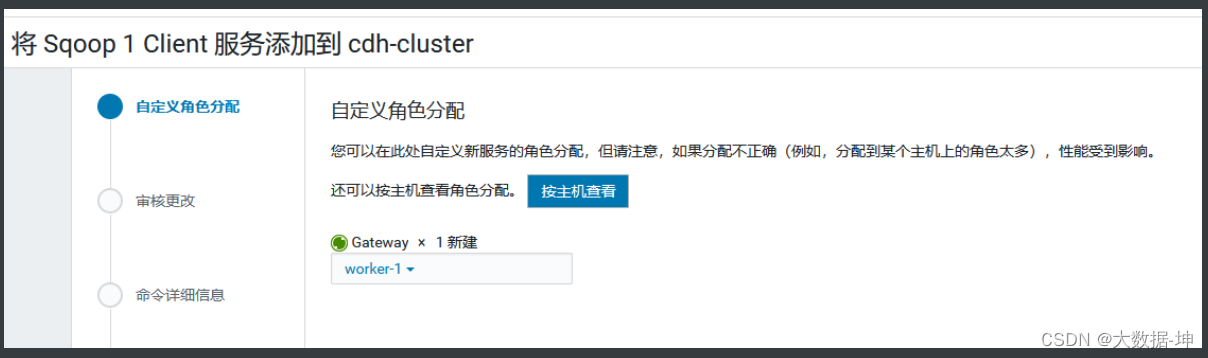
3)完成效果
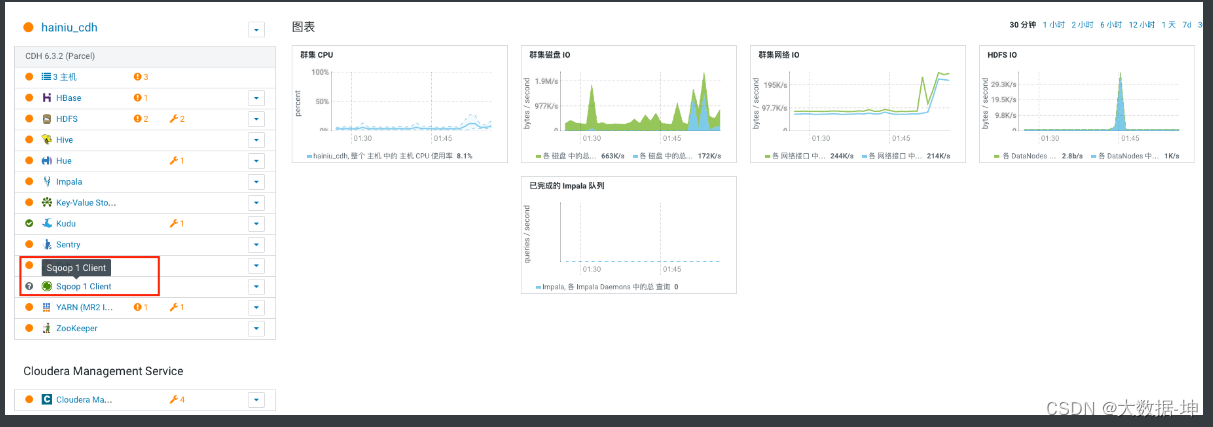
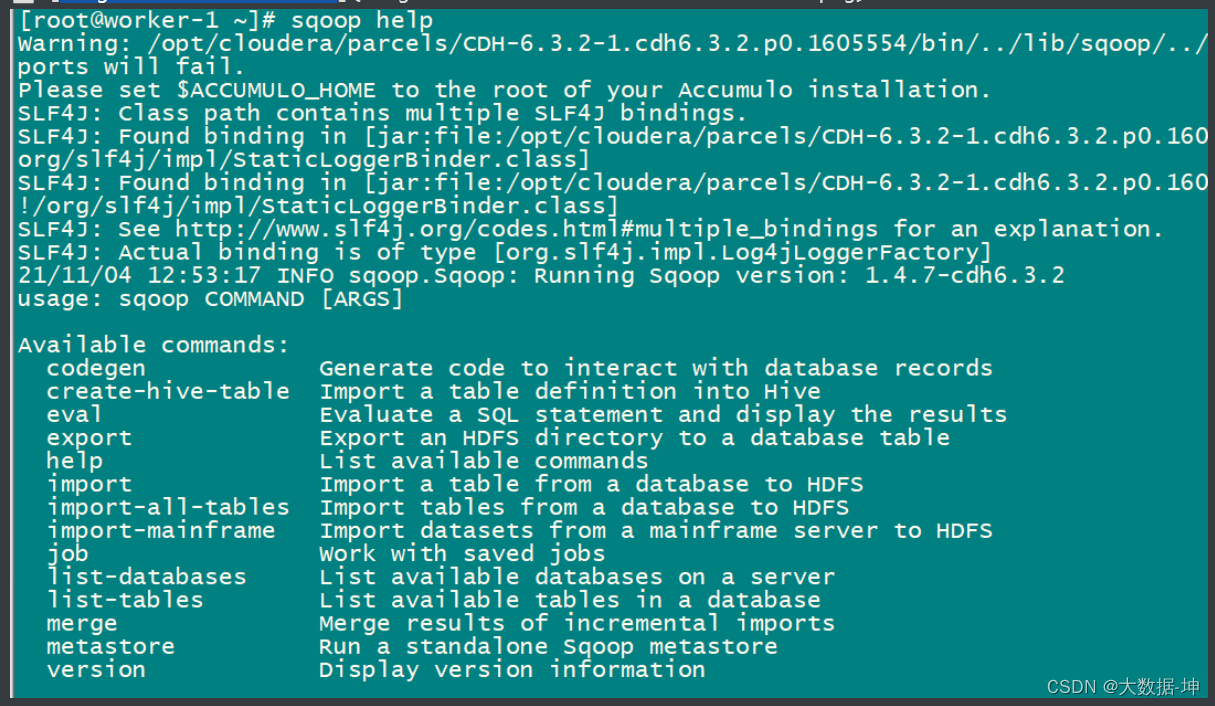
4)测试sqoop
<span style="background-color:#333333"><span style="color:#b8bfc6"><span style="color:#da924a"># hdfs认证</span>
kinit hdfs
<span style="color:#da924a"># shell 里执行 sqoop 命令</span>
sqoop help</span></span>查看,说明sqoop安装完成
3 sqoop常用参数
安全环境下操作需要做安全认证
-
常用命令
| 命令名称 | 对应类 | 命令说明 |
|---|---|---|
| import | ImportTool | 将关系型数据库数据导入到HDFS、HIVE、HBASE |
| export | ExportTool | 将HDFS上的数据导出到关系型数据库 |
| codegen | CodeGenTool | 获取数据库中某张表数据生成Java并打成Jar包 |
| create-hive-table | CreateHiveTableTool | 创建hive的表 |
| eval | EvalSqlTool | 查看SQL的执行结果 |
| list-databases | ListDatabasesTool | 列出所有数据库 |
| list-tables | ListTablesTool | 列出某个数据库下的所有表 |
| help | HelpTool | 打印sqoop帮助信息 |
| version | VersionTool | 打印sqoop版本信息 |
-
连接参数列表
| Argument | Description |
|---|---|
--connect <jdbc-uri> | Specify JDBC connect string 指定JDBC连接字符串 |
--connection-manager <class-name> | Specify connection manager class to use 指定要使用的连接管理器类 |
--driver <class-name> | Manually specify JDBC driver class to use 指定要使用的JDBC驱动类 |
--hadoop-mapred-home <dir> | Override $HADOOP_MAPRED_HOME 指定$HADOOP_MAPRED_HOME路径 |
--help | Print usage instructions 帮助信息 |
--password-file | Set path for a file containing the authentication password 设置用于存放认证的密码信息文件的路径 |
-P | Read password from console 从控制台读取输入的密码 |
--password <password> | Set authentication password 设置认证密码 |
--username <username> | Set authentication username 设置认证用户名 |
--verbose | Print more information while working 打印运行信息 |
--connection-param-file <filename> | Optional properties file that provides connection parameters 指定存储数据库连接参数的属性文件 |
-
连接MySQL示例
<span style="background-color:#333333"><span style="color:#b8bfc6"><span style="color:#da924a"># 查询数据库列表 对标show databases</span>
sqoop list-databases <span style="color:#7575e4">--connect</span> jdbc:mysql://worker-1/ <span style="color:#7575e4">--username</span> root <span style="color:#7575e4">--password</span> <span style="color:#64ab8f">12345678</span>
mysql <span style="color:#7575e4">-uroot</span> <span style="color:#7575e4">-p12345678</span>
<span style="color:#da924a"># 如果想连接 jdbc:mysql://worker-1:3306, 需要创建远程root访问权限</span>
<span style="color:#da924a"># 创建远程root用户</span>
CREATE USER <span style="color:#d26b6b">'root'</span>@<span style="color:#d26b6b">'%'</span> IDENTIFIED BY <span style="color:#d26b6b">'12345678'</span>;
<span style="color:#da924a"># 给远程root用户增加数据库权限</span>
grant all privileges on *.* to <span style="color:#d26b6b">'root'</span>@<span style="color:#d26b6b">'%'</span> identified by <span style="color:#d26b6b">'12345678'</span>;
<span style="color:#da924a"># 更新</span>
flush privileges;
sqoop list-databases <span style="color:#7575e4">--connect</span> jdbc:mysql://worker-1:3306/ <span style="color:#7575e4">--username</span> root <span style="color:#7575e4">--password</span> <span style="color:#64ab8f">12345678</span></span></span> 
<span style="background-color:#333333"><span style="color:#b8bfc6"><span style="color:#da924a"># 查询指定库下面所有表 对标show tables in cm</span>
sqoop list-tables <span style="color:#7575e4">--connect</span> jdbc:mysql://worker-1:3306/cm <span style="color:#7575e4">--username</span> root <span style="color:#7575e4">--password</span> <span style="color:#64ab8f">12345678</span></span></span>4 sqoop应用
4.1 准备测试数据
应用场景:
使用sqoop上传字典表数据到hive中与我们的数据进行关联查询。
以 商品表 为例:
<span style="background-color:#333333"><span style="color:#b8bfc6"><span style="color:#da924a">-- 创建sqoop_db 数据库</span>
<span style="color:#c88fd0">create</span> database wk_sqoop_db default charset utf8 collate utf8_general_ci;
<span style="color:#da924a">-- 导入SQL文件</span>
mysql -uroot -P3306 -p12345678 wksqoop_db < /tmp/wk/goods_table<span style="color:#9fbad5">.sql</span>
<span style="color:#da924a">-- (自己加的) 如果怕数据丢失,(删除库了)可以备份</span>
mysqldump -uroot -p12345678 goods_table > /data/wjk42/wjk<span style="color:#9fbad5">.sql</span></span></span> 
4.2 eval 查看 sql 查询结果
<span style="background-color:#333333"><span style="color:#b8bfc6"><span style="color:#da924a"># 没有where条件 --query 是要执行的sql语句</span>
sqoop eval \
<span style="color:#7575e4">--connect</span> jdbc:mysql://worker-1:3306/wk_sqoop_db \
<span style="color:#7575e4">--username</span> root \
<span style="color:#7575e4">--password</span> <span style="color:#64ab8f">12345678</span> \
<span style="color:#7575e4">--query</span> <span style="color:#d26b6b">"select * from goods_table limit 10"</span></span></span>
4.3 create-hive-table创建hive表
<span style="background-color:#333333"><span style="color:#b8bfc6"><span style="color:#da924a"># 基于MySQL表创建hive表</span>
<span style="color:#da924a"># 需要认证以及拥有hive建表权限</span>
kinit hive
sqoop create-hive-table \
<span style="color:#7575e4">--connect</span> jdbc:mysql://worker-1:3306/sqoop_db \
<span style="color:#7575e4">--username</span> root \
<span style="color:#7575e4">--password</span> <span style="color:#64ab8f">12345678</span> \
<span style="color:#7575e4">--table</span> goods_table \
<span style="color:#7575e4">--hive-table</span> panniu.goods_table</span></span>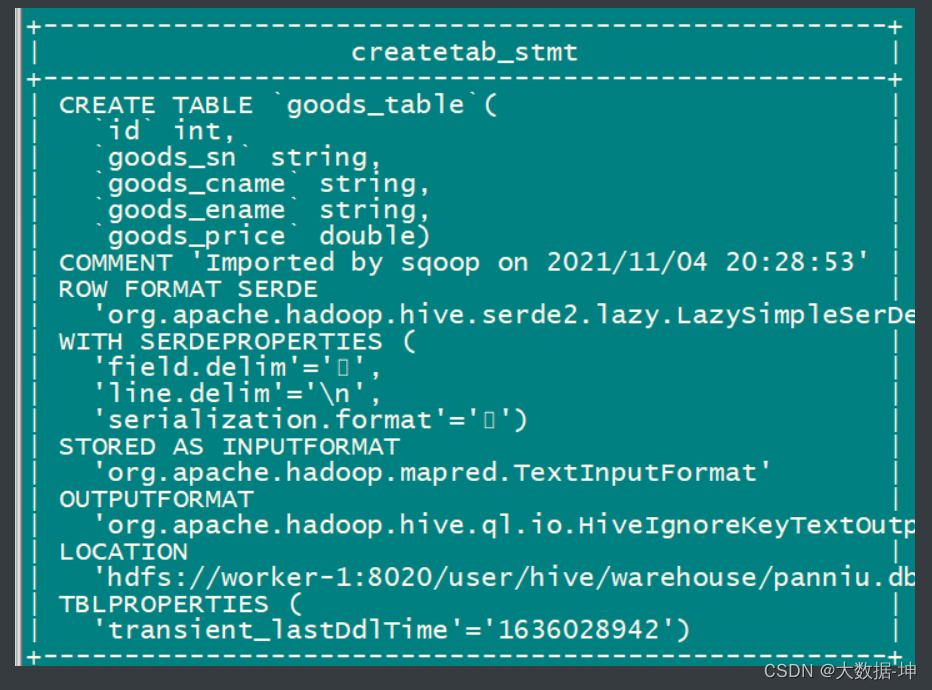
4.4 多map条件查询导入HDFS
语法 :
<span style="background-color:#333333"><span style="color:#b8bfc6">sqoop import \
<span style="color:#7575e4">--connect</span> 数据库连接字符串 \
<span style="color:#7575e4">--username</span> 数据库用户名 \
<span style="color:#7575e4">--password</span> 数据库密码 \
<span style="color:#7575e4">--target-dir</span> HDFS位置 \
<span style="color:#7575e4">--delete-target-dir</span> \
<span style="color:#7575e4">--fields-terminated-by</span> <span style="color:#d26b6b">"\t"</span> \
<span style="color:#7575e4">--num-mappers</span> <span style="color:#64ab8f">3</span> \ 底层是mapredure,所以要启动3个map,
<span style="color:#7575e4">--split-by</span> 切分数据依据 \ id分 sqoop会自己划分
<span style="color:#7575e4">--query</span> <span style="color:#d26b6b">'select SQL where 查询条件 and $CONDITIONS'</span>
<span style="color:#7575e4">--</span> (自己加的)--delete-target-dir \ : mysql导入数据,假如第一次导入数据到hdfs的/data/wk/这个目录上,下一次导入还是这个目录,如果还是这个目录则会报错,所以下一次导数据之前,要先把以前的目录删掉。
<span style="color:#7575e4">--</span> num-mappers <span style="color:#64ab8f">3</span> \ 底层是mapredure,所以要启动3个map,默认是4个</span></span>参数解释 :
--query或--e <statement> 将查询结果的数据导入,使用时必须伴随参--target-dir,--hive-table,如果查询中有where条件,则条件后必须加上$CONDITIONS关键字
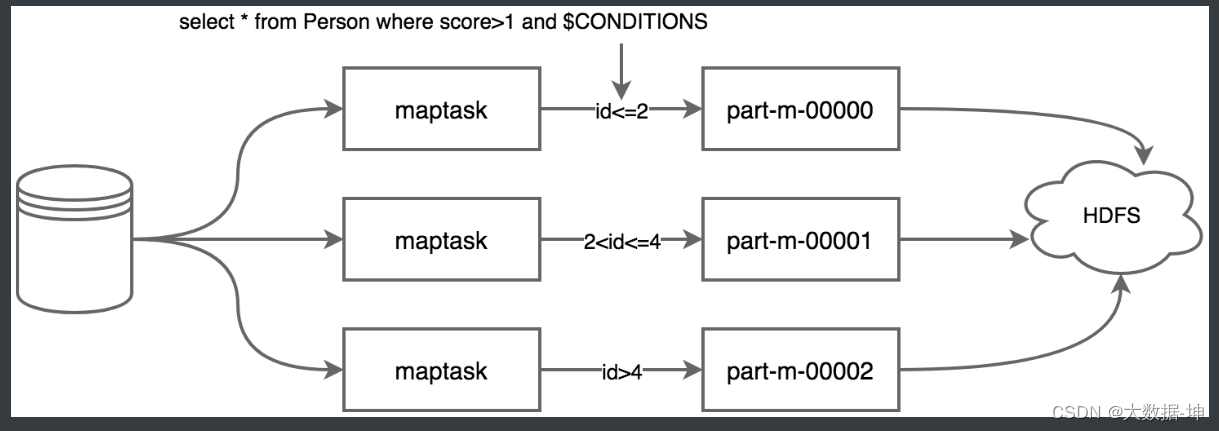
当sqoop使用--query+sql执行多个maptask并行运行导入数据时,每个maptask将执行一部分数据的导入,原始数据需要使用'--split-by 某个字段'来切分数据,不同的数据交给不同的maptask去处理。maptask执行sql副本时,需要在where条件中添加$CONDITIONS条件,这个是linux系统的变量,可以根据sqoop对边界条件的判断,来替换成不同的值,这就是说若split-by id,则sqoop会判断id的最小值和最大值判断id的整体区间,然后根据maptask的个数来进行区间拆分,每个maptask执行一定id区间范围的数值导入任务,如下为示意图。
 正在上传…重新上传取消
正在上传…重新上传取消
4.3.1 导入文本文件
<span style="background-color:#333333"><span style="color:#b8bfc6"><span style="color:#da924a">#用panniu认证</span>
sqoop import \
<span style="color:#7575e4">--connect</span> jdbc:mysql://worker-1:3306/sqoop_db<span style="color:#d26b6b">"?useUnicode=true&characterEncoding=UTF-8"</span> \
<span style="color:#7575e4">--username</span> root \
<span style="color:#7575e4">--password</span> <span style="color:#64ab8f">12345678</span> \
<span style="color:#7575e4">--target-dir</span> /user/pwk/sqoop/data/goods_1 \
<span style="color:#7575e4">--delete-target-dir</span> \
<span style="color:#7575e4">--fields-terminated-by</span> <span style="color:#d26b6b">"\001"</span> \
<span style="color:#7575e4">--num-mappers</span> <span style="color:#64ab8f">4</span> \
<span style="color:#7575e4">--split-by</span> id \
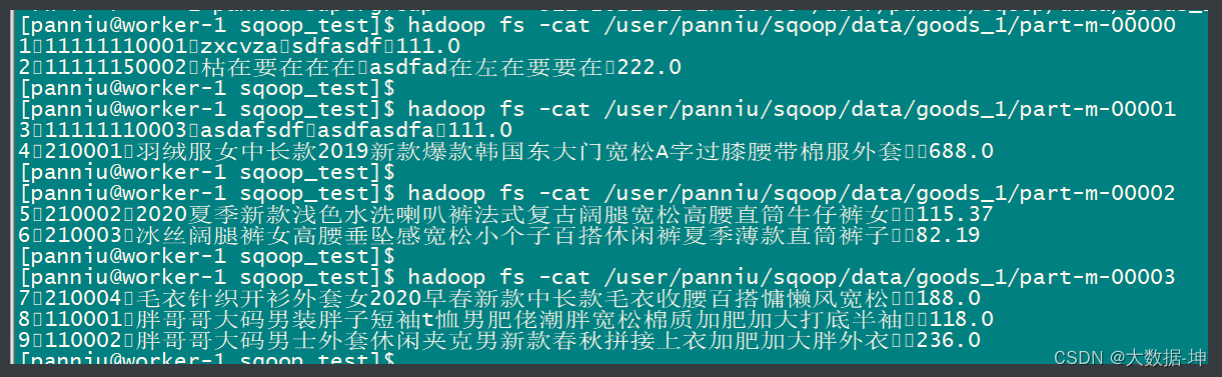
<span style="color:#7575e4">--query</span> <span style="color:#d26b6b">'select * from goods_table where id < 10 and $CONDITIONS'</span></span></span>查询结果 :
 正在上传…重新上传取消
正在上传…重新上传取消
4.3.2 导入其他格式文件
<span style="background-color:#333333"><span style="color:#b8bfc6"># 导入不同格式,支持格式as-avrodatafile、as-binaryfile、as-parquetfile、as-sequencefile、as-textfile(默认格式)
# 多次导入时会报jar包已存在错误,请忽略,原因为sqoop读取源数据的schema文件创建的jar在前几次任务中已经创建了。
sqoop import \
--connect jdbc:mysql://worker-1:3306/sqoop_db"?useUnicode=true&characterEncoding=UTF-8" \
--username root \
--password 12345678 \
--target-dir /user/pwk/sqoop/data/goods_2_parquet \
--delete-target-dir \
--as-parquetfile \
--num-mappers 4 \
--split-by id \
--query 'select * from goods_table where id < 10 and $CONDITIONS'
</span></span>结果:
正在上传…重新 上传取消
上传取消
4.5 导入hive表
4.5.1 导入文本表
<span style="background-color:#333333"><span style="color:#b8bfc6"># hive认证
kinit -kt /data/hive.keytab hive
# 导入命令
sqoop import \
--connect jdbc:mysql://worker-1:3306/sqoop_db"?useUnicode=true&characterEncoding=UTF-8" \
--username root \
--password 12345678 \
--table goods_table \
--num-mappers 1 \
--delete-target-dir \
--hive-import \
--fields-terminated-by "\001" \
--hive-overwrite \
--hive-table wk.goods_table1</span></span>上面过程分为两步:
1)第一步将数据导入到HDFS,默认的临时目录是/user/当前操作用户/mysql表名;
2)第二步将导入到HDFS的数据迁移到Hive表,如果hive表不存在,sqoop会自动创建内部表;(我们的是在/user/panniu/goods_table,通过查看job的configuration的outputdir属性得知)
 正在上传…重新上传取消
正在上传…重新上传取消
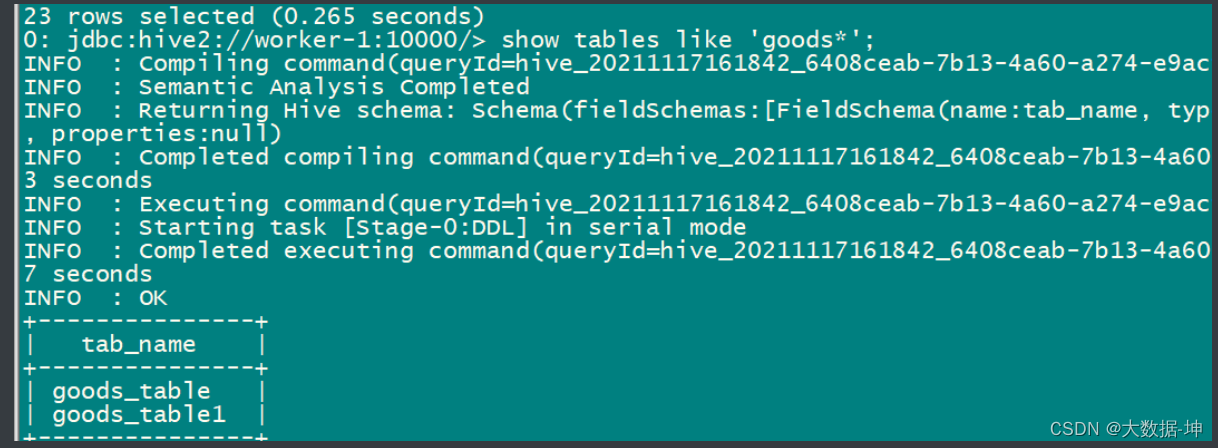
结果:
 正在上传…重新上传取消
正在上传…重新上传取消
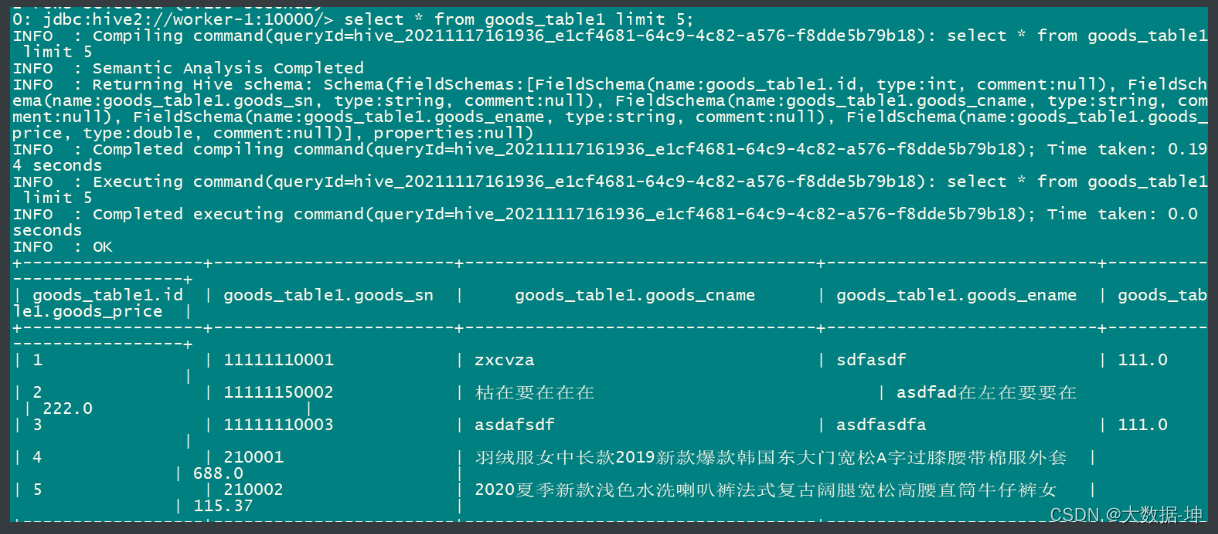
查询数据:
 正在上传…重新上传取消
正在上传…重新上传取消
4.5.2 导入其他格式表
<span style="background-color:#333333"><span style="color:#b8bfc6"># hive认证
kinit -kt /data/hive.keytab hive
# 导入命令
sqoop import \
--connect jdbc:mysql://worker-1:3306/sqoop_db"?useUnicode=true&characterEncoding=UTF-8" \
--username root \
--password 12345678 \
--table goods_table \
--num-mappers 1 \
--delete-target-dir \
--as-parquetfile \
--hive-import \
--hive-overwrite \
--hive-table pwk.goods_table_parquet</span></span>结果:
正在上传…重新上传取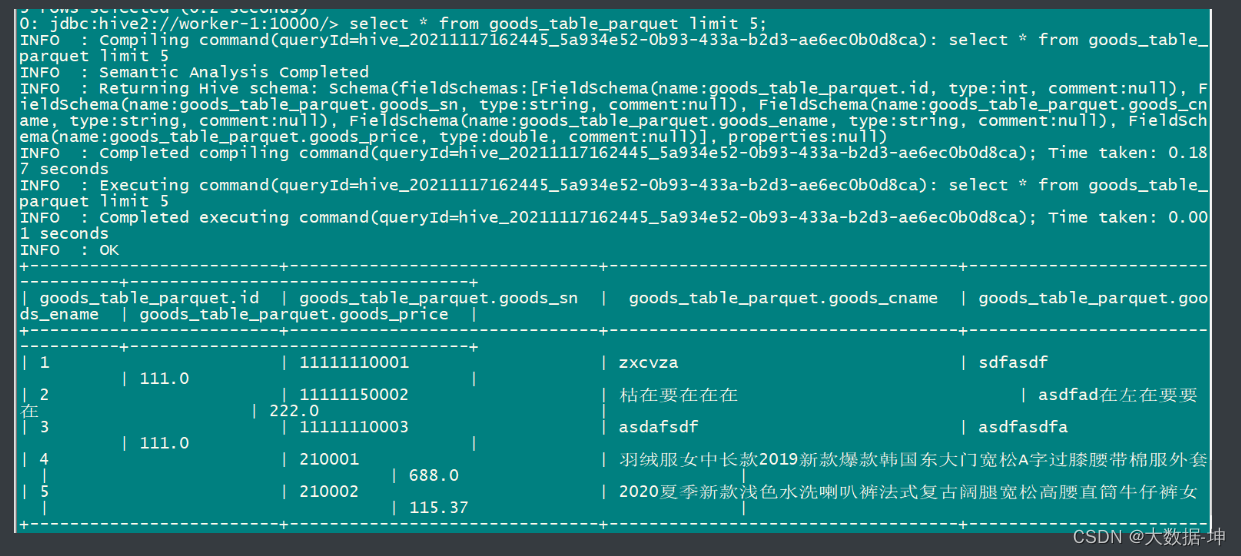 消
消
4.6 import to hbase
<span style="background-color:#333333"><span style="color:#b8bfc6"># 用hdfs认证
kinit -kt /data/hdfs.keytab hdfs
hadoop fs -mkdir /user/hbase
hadoop fs -chown hbase /user/hbase
# 用hbase认证
kinit -kt /data/hbase.keytab hbase
# sqoop导入hbase
sqoop import \
--connect jdbc:mysql://worker-1:3306/sqoop_db"?useUnicode=true&characterEncoding=UTF-8" \
--username root \
--password 12345678 \
--table goods_table \
--hbase-create-table \
--hbase-table pwk:goods_table \
--column-family cf \
--hbase-row-key id
# --hbase-row-key: 要求MySQL表必须有主键,将主键作为rowkey,标识一行 </span></span>导入后,查看:
 正在上传…重新上传取消
正在上传…重新上传取消
5 应用实例一
sqoop_db 库导入 comm_area 表和数据
导入后查看:
正在上传…重新上传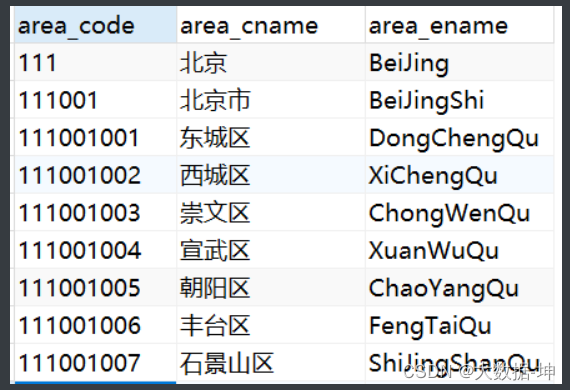 取消
取消
前提:
<span style="background-color:#333333"><span style="color:#b8bfc6"># 给 impala 赋予hive的所有权限
grant role admin_role to group impala;
# sqoop_db库导入comm_area表
# 创建linux导出目录
/data/pwk/extract</span></span>1) mysql --> hdfs目录 (sqoop)
2)创建hive外表指向 hdfs目录(临时表作用,先删除,后创建) (impala)
3)创建分区表(只创建一次),分区:batch_date (impala)
4) 先删除分区,再创建分区并查询导入(目的:可以使得脚本能重复执行) (impala)
正在上传…重新上 传取消
传取消
vim area_op.sh
<span style="background-color:#333333"><span style="color:#b8bfc6"># 获取batch_date,比如:今天20211010, 那batch_date是20211009
batch_date=`date -d 1' day ago' +%Y%m%d`
# pwk认证
kinit -kt /data/pwk.keytab panniu
# 用sqoop,查询表数据导入到hdfs上
# -Dorg.apache.sqoop.splitter.allow_text_splitter=true: --split-by的是字符串也可以
# --split切分的是整数类型 ,本次是string类型,split的话就会报错,需要加 allow_text_splitter=true
sqoop import -Dorg.apache.sqoop.splitter.allow_text_splitter=true \
--connect jdbc:mysql://worker-1:3306/sqoop_db \
--username root \
--password 12345678 \
--target-dir /user/pwk/comm_area/${batch_date}/ \
--delete-target-dir \
--fields-terminated-by "\t" \
--split-by area_code \
--query 'select comm_area.* from comm_area where $CONDITIONS'
# $?: 返回上个命令的结果, 0:成功, 非0:失败
res=$?
if [ ${res} != 0 ];then
echo 'extract comm_area error! '`date` >> /data/pwk/extract/comm_area.log
exit 1
else
echo 'extract comm_area successful '`date` >> /data/pwk/extract/comm_area.log
fi
# impala认证
kinit -kt /data/impala.keytab impala
# 用impala-shell, 创建hive表tmp.comm_area(临时表作用),并指向导入的hdfs目录
impala-shell -k -q "set sync_ddl = true;drop table if exists tmp.comm_area;create external table tmp.comm_area (
area_code string,
area_cname string,
area_ename string
)
row format delimited fields terminated by '\t'
location '/user/pwk/comm_area/${batch_date}';
set sync_ddl = false;"
res=$?
if [ ${res} != 0 ];then
echo 'create comm_area tmp table error! '`date` >> /data/pwk/extract/comm_area.log
exit 1
else
echo 'create comm_area tmp table successful '`date` >> /data/pwk/extract/comm_area.log
fi
# impala认证
kinit -kt /data/impala.keytab impala
# 用impala-shell,创建hive分区表 itl.comm_area
impala-shell -k -q"set sync_ddl = true;create table if not exists itl.comm_area (
area_code string,
area_cname string,
area_ename string
)
partitioned by (pt string)
stored as parquet
tblproperties ('parquet.compress'='SNAPPY')
;
set sync_ddl = false;"
res=$?
if [ ${res} != 0 ];then
echo 'create comm_area itl table error! '`date` >> /data/pwk/extract/comm_area.log
exit 1
else
echo 'create comm_area itl table successful '`date` >> /data/pwk/extract/comm_area.log
fi
# 将临时表中的数据导入到 itl.comm_area 表中
kinit -kt /data/impala.keytab impala
impala-shell -k -q "set sync_ddl = true;alter table itl.comm_area drop if exists partition (pt = '${batch_date}');set sync_ddl = false;"
impala-shell -k -q "set sync_ddl = true;insert into table itl.comm_area partition (pt) select a.*,'${batch_date}' from tmp.comm_area a;set sync_ddl = false;"
res=$?
if [ ${res} != 0 ];then
echo 'load comm_area data to itl table error! '`date` >> /data/pwk/extract/comm_area.log
exit 1
else
echo 'load comm_area data to itl table successful '`date` >> /data/pwk/extract/comm_area.log
fi</span></span>6 应用实例二
vim goods_op.sh
<span style="background-color:#333333"><span style="color:#b8bfc6">kinit -kt /data/pwk.keytab pwk
batch_date=$1
# ***sqoop导如数据到hdfs****
#sqoop底层走mr 一般默认4map,没有reducer
# --hive-drop-import-delims: 在导入数据到hive时,去掉数据中的\r\n\013\010这样的字符
sqoop import \
--connect jdbc:mysql://worker-1:3306/sqoop_db \
--username root \
--password 12345678 \
# 1.dorp :假如说没错,mysql中的元数据信息导入到了hdfs的/wjk42/20220614目录下,那么明天的数据就在20220615的目录下;假如说20220614的天的数据跑错了,那么sqoop会重新执行一边,重新执行的时候会把20220614的数据删掉。如果本次sqoop导入成功的话,下个阶段创建临时表的时候报错,这个路径的数据也会给你drop
--target-dir /user/pwk/goods_table/${batch_date}/ \
--hive-drop-import-delims \
--delete-target-dir \
--fields-terminated-by "\t" \
--split-by Id \
--query 'select * from goods_table where $CONDITIONS'
res=$?
if [ ${res} != 0 ];then
echo 'extract goods_table error! '`date` >> /data/pwk/extract/goods_table.log
exit 1
else
echo 'extract goods_table successful '`date` >> /data/pwk/extract/goods_table.log
fi
# ***临时表****创建hive外表关联hdfs
# 用impala认证快,基于内存,hive认证也行,hive慢,底层走mr
# --(自己写的)用impala来认证 -k认证impala -q执行sql语句
# --设置同步,写imapla的时候每次都需要设置同步,多个impalad之间是需要同步的
# --drop,因为他h是一个临时的goodstable,如果第一次运行的时候,这张表已经创建# --出来了,但是最后往你的分区表导入的时候导错了,下次再跑的时候hive外表已经有# --这张表了,会报错,所以要先删除
kinit -kt /data/impala.keytab impala
impala-shell -k -q "set sync_ddl = true;drop table if exists tmp.goods_table;create external table tmp.goods_table (
Id string,
goods_sn string,
goods_cname string,
goods_ename string,
goods_price string
)
row format delimited fields terminated by '\t'
location '/user/pwk/goods_table/${batch_date}';
set sync_ddl = false;"
# --做一个日志打印,正确错误,都打印一个日志
res=$?
if [ ${res} != 0 ];then
echo 'create goods_table tmp table error! '`date` >> /data/pwk/extract/goods_table.log
exit 1
else
echo 'create goods_table tmp table successful '`date` >> /data/pwk/extract/goods_table.log
fi
# --T层 创建一个parquet表 ***分区表****把临时表中的数据导入到分区表
# 这个分区表不需要每次都要创建,这个表没有drop,如果这个分区表已经有的话,就不创建了。 重点:drop的是是分区表中的某一个分区就行了
kinit -kt /data/impala.keytab impala
impala-shell -k -q"set sync_ddl = true;create table if not exists itl.goods_table (
Id string,
goods_sn string,
goods_cname string,
goods_ename string,
goods_price string
)
partitioned by (pt string)
stored as parquet
tblproperties ('parquet.compress'='SNAPPY')
;
set sync_ddl = false;
"
res=$?
if [ ${res} != 0 ];then
echo 'create goods_table itl table error! '`date` >> /data/pwk/extract/goods_table.log
exit 1
else
echo 'create goods_table itl table successful '`date` >> /data/pwk/extract/goods_table.log
fi
# 重点:drop的是是分区表中的某一个分区就行了
# 加载数据到itl层 跑批日期使用参数传递
# 1.drop 还是重跑问题,如果执行到hive分区表的时候,日期已经添加好了,再跑的时候# 发现分区已经有了,所以说重跑的时候,应该先把这个分区删掉(所有的流程都应该# # 支持重跑,因为你也不知道他会再哪里报错)
# 2.select临时表中的数据,插入语分区表中(以动态分区的方式)
kinit -kt /data/impala.keytab impala
impala-shell -k -q "set sync_ddl = true;alter table itl.goods_table drop if exists partition (pt = '${batch_date}');set sync_ddl = false;"
impala-shell -q "set sync_ddl = true;insert into table itl.goods_table partition (pt) select a.*,'${batch_date}' from tmp.goods_table a;set sync_ddl = false;"
res=$?
if [ ${res} != 0 ];then
echo 'load goods_table data to itl table error! '`date` >> /data/pwk/extract/goods_table.log
exit 1
else
echo 'load goods_table data to itl table successful '`date` >> /data/pwk/extract/goods_table.log
fi</span></span>执行时,需要从外界将日期传递过来
<span style="background-color:#333333"><span style="color:#b8bfc6"># 给脚本添加执行权
chmod a+x goods_op.sh
# 执行脚本
sh -x goods_op.sh 20211010</span></span><span style="background-color:#333333"><span style="color:#b8bfc6"># hdfs(hive)的数据导入mysql中
sqoop export \
-connect jdbc:mysql://worker-1:3306/wk_sqoop_db \
-username root \
-password 12345678 \
# 导入到mysql中的stu表
-table stu \
-fields-terminated-by '\t' \
# hive表中数据的位置
-export-dir /user/hive/warehouse/wk_sqoop_tmp.db/stu/fd4196f756856244-f342f60b00000000_1400379289_data.0.</span></span>













 337
337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









