






 该博客介绍了在Python Web框架上实现CMS(内容管理系统)识别的方法,主要依赖于特定文件路径的MD5特征匹配。通过读取配置文件中的CMS特征,对目标网站发起请求并获取响应的MD5,与预定义的CMS特征库对比,从而识别CMS类型。文章提供了一个简单的代码片段用于初始化和匹配CMS特征。
该博客介绍了在Python Web框架上实现CMS(内容管理系统)识别的方法,主要依赖于特定文件路径的MD5特征匹配。通过读取配置文件中的CMS特征,对目标网站发起请求并获取响应的MD5,与预定义的CMS特征库对比,从而识别CMS类型。文章提供了一个简单的代码片段用于初始化和匹配CMS特征。
文本是在上一篇 Python Web框架上的在线高精度IP定位 的基础上在新增一个CMS识别的功能
最终实现的效果图
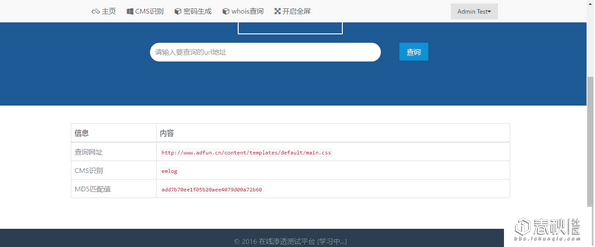
0x01 CMS识别原理
CMS识别原理就是得到一些CMS的一些固有特征,通过得到这个特征来判断CMS的类别。
这里我们使用MD5识别的方式,就是用特定的文件路径访问网站,获得这个文件的MD5,如果和已知MD5相同的话就可以判断这个CMS了
所以,这个识别的成功率是根据我们的字典来的
简单截取几个CMS特征:
/favicon.ico ecshop 724c06bcaf1a3005ba1da8207d2f43d0
/favicon.ico ecshop 428b23df874b41d904bbae29057bdba5
/favicon.ico Discuz c028c4822428e83a358c60a93ef65381
以空格来分割文本,第一个是访问的路径,第二个是CMS名称,第三个就是MD5值
然后编写代码匹配出就行了
0x02 CMS识别核心代码
def init():
file = open(r”config/dna.txt”)
try:
for line in file:
str = line.strip().split(” “)
ls_data={}
if len(str)==3:
ls_data[“url”] = str[0]
ls_data[“name”] = str[1]
ls_data[“md5”] = str[2]
data.append(ls_data)
finally:
file.close( )
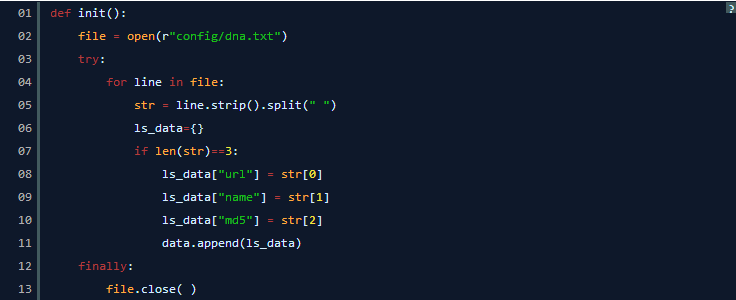
首先初始化一下字典,将目录下的字典文件加载进来,返回python的字典数组
然后循环这个字典,对里面每个url进行遍历,先看状态码是否是200,如果有就获取MD5,具体代码如下
…………………………………………………………………………………………………略,
查看全文请看这里》》》》》》》原文地址:http://bbs.ichunqiu.com/thread-13555-1-1.html?from=jike















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









