






在当今大模型时代,高性能计算(HPC)和 人工智能(AI),特别是目前 DeepSeek 大火后,这些领域对计算能力的需求如同滚雪球般不断增大,多 GPU 计算已然成为满足这种需求的关键趋势。然而,若要充分发挥多 GPU 的强大性能,深入了解现代 GPU 互连技术及其对应用性能的影响则至关重要。本文将对现代 GPU 互连技术进行深入剖析,比如 对 PCIe、NVLink、NV-SLI、NVSwitch 和 GPUDirect 等,进行探讨它们的性能特点以及在实际应用中的表现。
一、引言
随着深度学习、大数据处理和大模型等领域的发展,对计算能力的需求呈爆发式增长。多 GPU 计算通过将多个 GPU 协同工作,能够显著提升计算性能,满足这些领域的需求。然而,GPU 之间的互连技术却成为了制约多 GPU 性能发挥的关键因素。不同的互连技术在带宽、延迟和通信效率等方面存在差异,直接影响着多 GPU 应用的整体性能。因此,对现代 GPU 互连技术进行深入研究和评估,对于优化多 GPU 应用性能、提高计算资源利用率具有重要意义。
比如 DeepSeek 刚发布的 DeepEP 提供了两种主要类型的内核,以满足不同的操作需求,详见:《DeepSeek 最新发布 DeepEP:一款用于 MoE 模型训练和推理的开源EP通讯库》。其中的普通内核(Normal Kernels)就是针对需要高吞吐量的场景进行了优化,例如推理的预填充阶段或训练。它们通过利用 NVLink 和 RDMA 网络技术,高效地在 GPU 之间转发数据。例如,在带有 NVLink 的 Hopper GPU 上进行的测试显示,节点内通信的吞吐量约为 153 GB/s,而使用 CX7 InfiniBand(大约 50 GB/s 带宽)的节点间测试实现了约 43–47 GB/s 的稳定性能。通过最大化可用带宽,这些内核减少了在 token 分发和结果合并期间的通信开销,显示提升性能,其底层背后是要依赖于 GPU 现代互联技术的。
二、现代 GPU 互连技术概述
(一)PCIe
PCIe(Peripheral Component Interconnect Express)是一种传统的高速串行计算机扩展总线标准,广泛应用于 GPU 与 CPU 之间的连接。
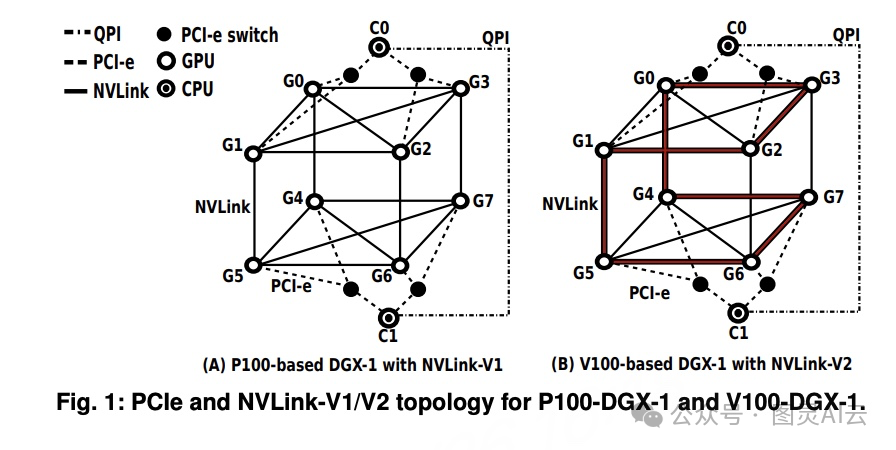
然而,与 CPU 和 DRAM 之间的互连相比,PCIe 的速度较慢,往往成为 GPU 加速的性能瓶颈。特别是在采用 PCIe 基础的 GPU P2P(Peer-to-Peer)通信时,这一问题更加突出。在多 GPU 系统中,PCIe 通常形成树状拓扑结构,例如在 DGX-1 中,GPU 之间通过 PCIe 交换机连接,形成平衡的树状结构。这种结构虽然简单,但在 GPU 数量较多时,容易出现带宽竞争和延迟增加的问题。
(二)NVLink
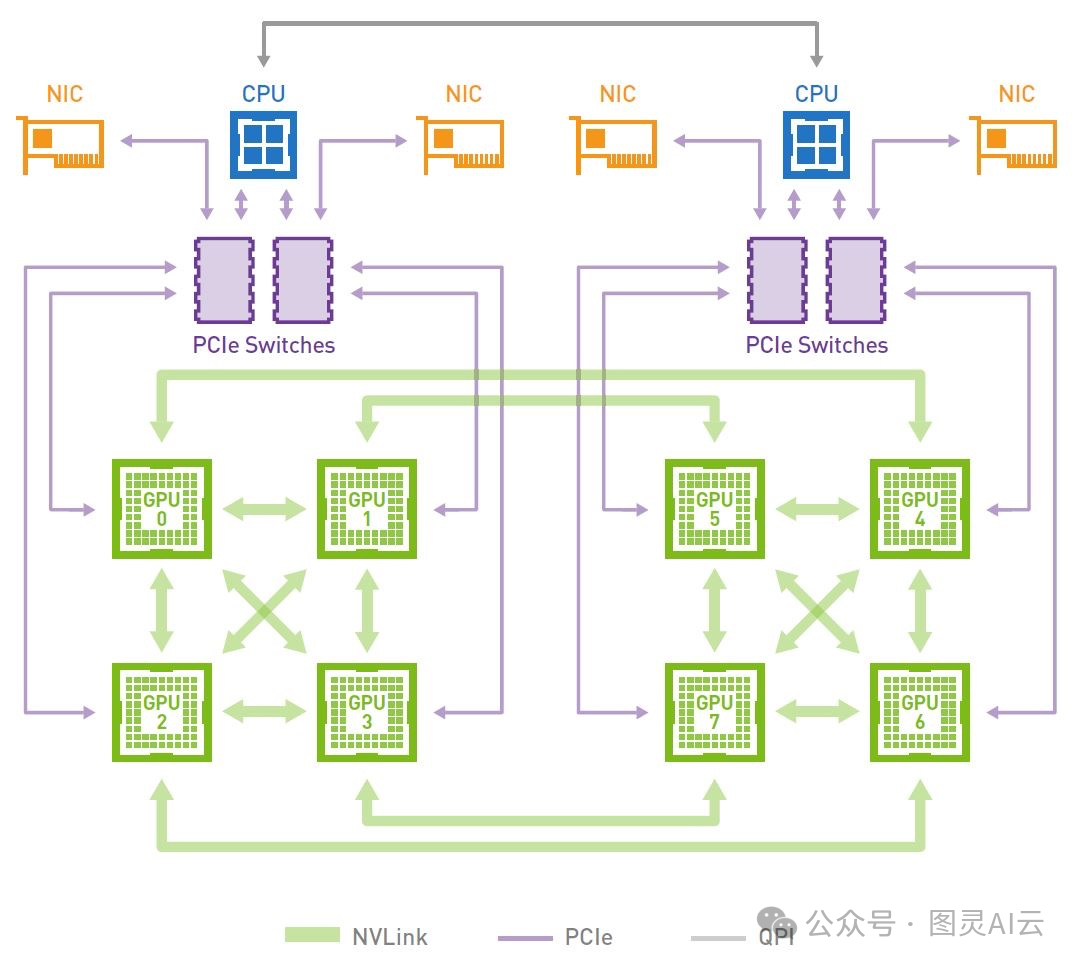
NVLink 是英伟达推出的一种高速 GPU 互连技术,旨在解决传统 PCIe 互连的性能瓶颈问题。NVLink 通过提供更高的带宽和更低的延迟,实现了 GPU 之间的高效通信。NVLink 采用基于高速信号互连(NVHS)的有线接口,支持 P2P 通信,允许直接读写远程 CPU 的主机内存和/或对等 GPU 的设备内存。NVLink 的每个链路包含两个子链路,每个子链路又包含八个差分 NVHS 通道,通信效率与数据包大小密切相关。与 PCIe 相比,NVLink 的通信效率可提升约两倍。

NVLink 有两种主要版本:NVLink-V1 和 NVLink-V2。NVLink-V1 是第一代 NVLink 技术,每个 Pascal-P100 GPU 配备四个 NVLink 插槽,可实现 4 倍的单链路带宽。NVLink-V2 是第二代 NVLink 技术,每个 Volta-V100 GPU 配备六个 NVLink 插槽,链路带宽提升了 25%,并引入了低功耗运行模式。NVLink-V2 还通过增加链路插槽数量,改变了原始网络拓扑结构,例如在 V100-DGX-1 中形成了快速的骨干环,以提高集体通信的效率。
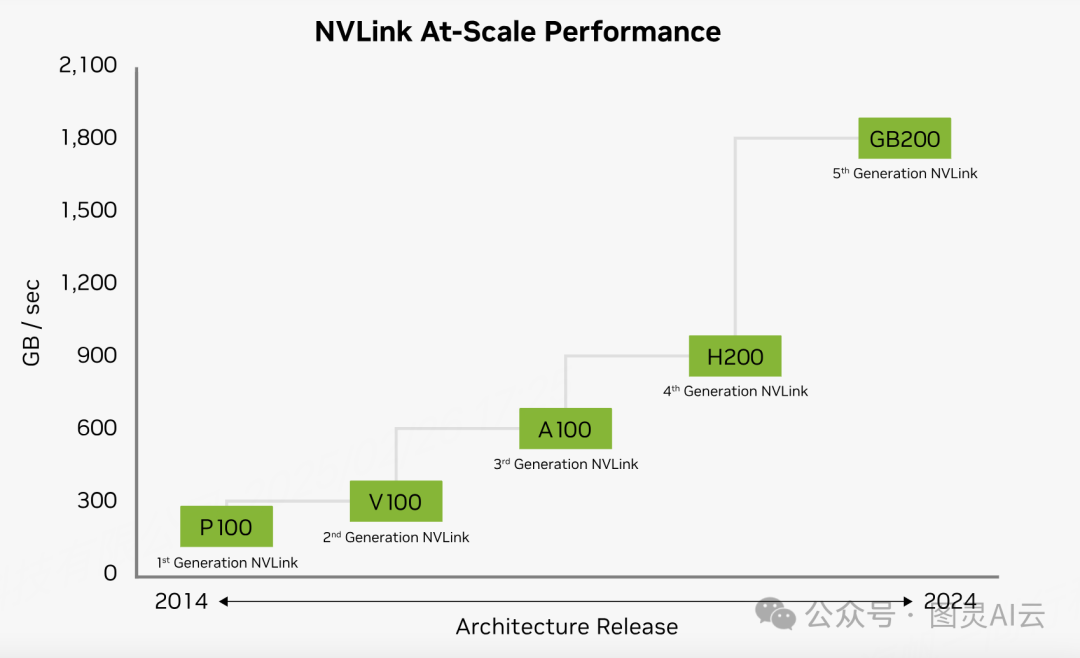
第五代 NVLink 极大地提升了大型多 GPU 系统的可扩展性。单个 NVIDIA Blackwell Tensor Core GPU 可支持多达 18 条 NVLink 100GB/s 的连接,总带宽可达 1.8TB/s——与上一代相比带宽翻倍,且超过 PCIe Gen5 带宽的 14 倍以上。像 GB200 NVL72 这样的服务器平台利用这项技术,为当今最复杂的大型模型提供了更强的可扩展性。
(三)NV-SLI

NV-SLI(Scalable Link Interface)是一种传统的用于图形目的的多 GPU 桥接技术。然而,随着英伟达 Turing 架构 GPU 的推出,NV-SLI 基于 NVLink-V2 互连技术,成为了一种新的高速多 GPU 桥接技术。NV-SLI 将两个 GPU 配对,使它们能够相互通信、共同渲染游戏、共同运行 GPGPU 任务或共享 GPU 内存空间。在 SLI 平台中,基于 TU104 的 RTX 2080 GPU 提供了一个 x8 NVLink-V2 链路,每个方向的带宽高达 25 GB/s,实现了 50 GB/s 的双向聚合带宽。需要注意的是,Turing 架构 GPU 仅支持双向 NVLink-SLI。
(四)NVSwitch
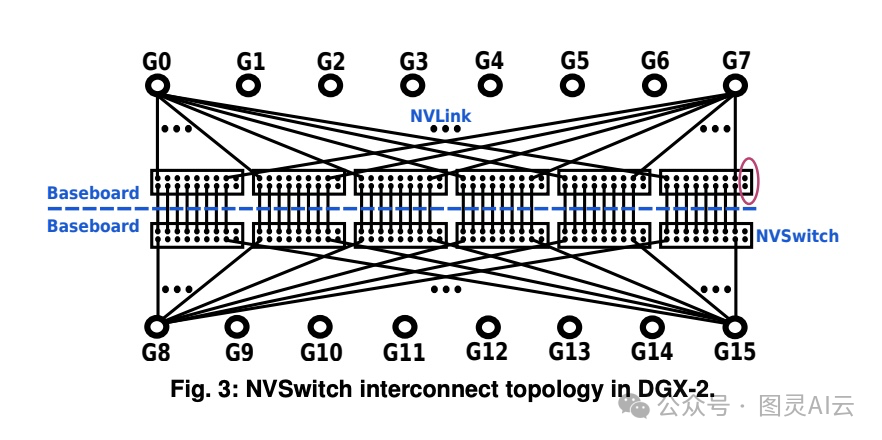
NVSwitch 是英伟达为了解决新兴应用中的全对全通信问题而推出的一种基于 NVLink-V2 的交换芯片技术。NVSwitch 仅出现在 DGX-2 中,每个 NVSwitch 拥有 18 个 NVLink 端口,能够实现高达 2.4 TB/s 的原始双向带宽。
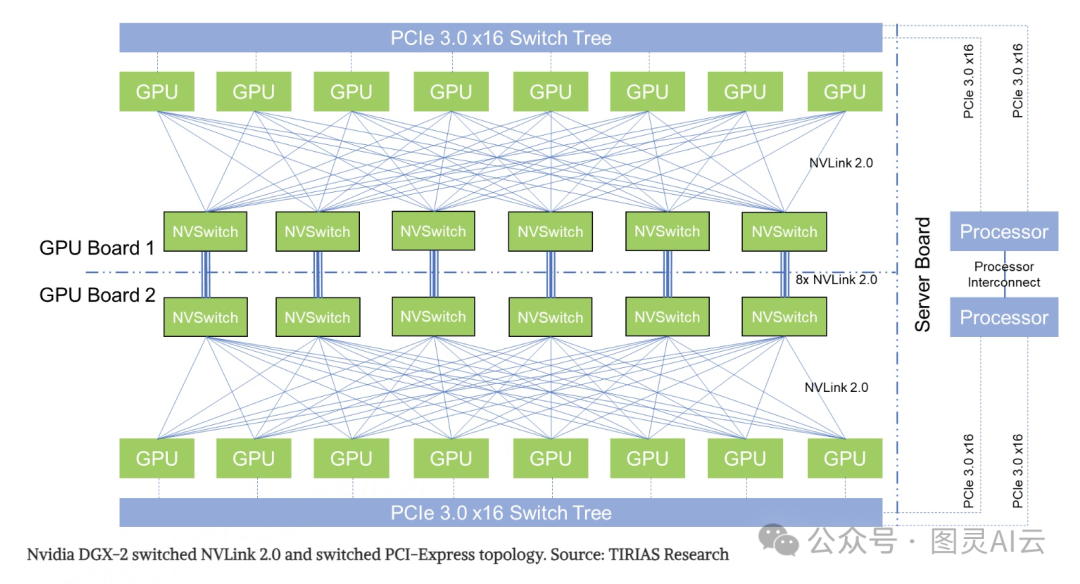
NVSwitch 通过两个基板实现,每个基板包含 6 个 NVSwitch,托管 8 个 GPU。每个 GPU 可以同时连接到 6 个 NVSwitch,每个链路的双向带宽为 50 GB/s。NVSwitch 的网络拓扑结构使得任何 GPU 都可以与其他 GPU 进行全互联通信,无论是单个基板内的通信还是两个基板之间的通信,都具有高带宽和低延迟的特点。
(五)GPUDirect
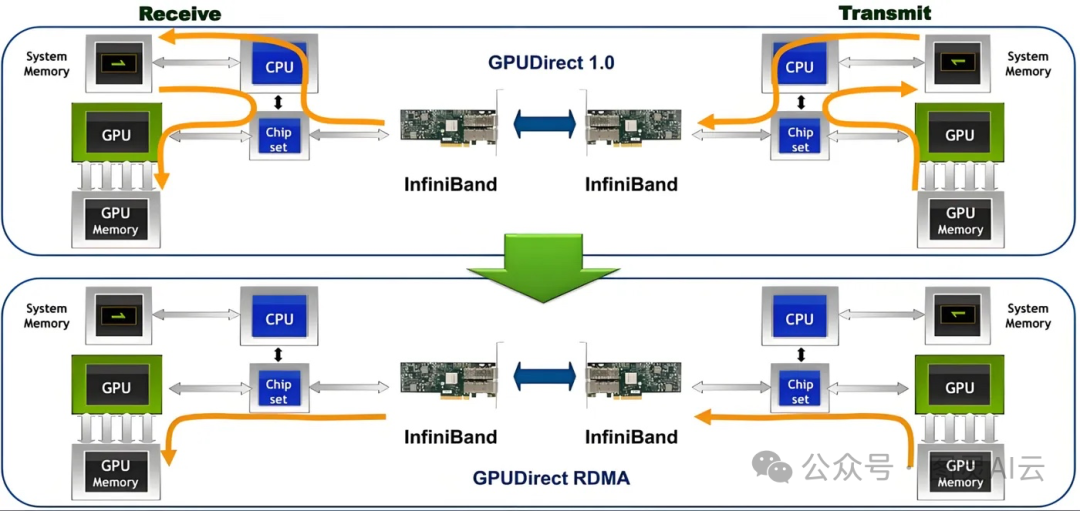
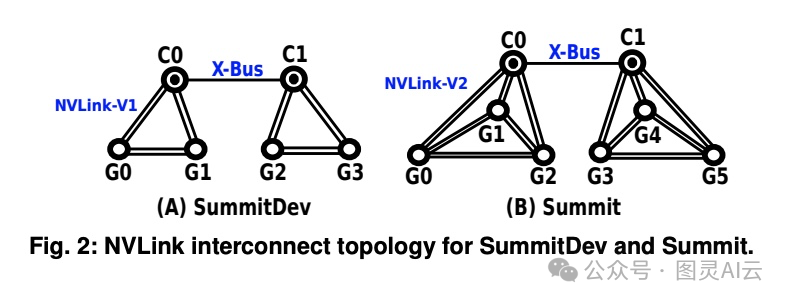
GPUDirect 是英伟达推出的一种技术,允许第三方 PCIe 设备(尤其是 IB 主机通道适配器 HCA)直接访问 GPU 设备内存,而无需 CPU 协助或通过主内存进行数据传输,从而显著提高了节点间 GPU 通信的效率。GPUDirect 通过 GPU 供应商提供的操作系统内核扩展,返回 GPU 设备内存的 DMA 总线映射。当用户创建 IB 区域时,IB 驱动程序会调用例程获取 DMA 映射,最终将正常的 IB 虚拟内存结构返回给用户程序,就像它针对正常的 CPU 内存一样。GPUDirect 在 SummitDev 和 Summit 超级计算机上得到了广泛应用,显著提升了 GPU 之间的通信性能。
三、GPU 互连技术的性能评估
(一)评估平台与方法
本文(https://arxiv.org/pdf/1903.04611)使用 Tartan Benchmark Suite 对六种现代 GPU 互连技术进行了评估,包括 PCIe、NVLink-V1、NVLink-V2、NV-SLI、NVSwitch 和 GPUDirect 启用的 InfiniBand。评估平台涵盖了六种高端服务器和 HPC 平台:NVIDIA P100-DGX-1、V100-DGX-1、DGX-2、OLCF 的 SummitDev 和 Summit 超级计算机,以及一个使用两个 NVIDIA Turing RTX 2080 GPU 的 SLI 链接系统。评估重点关注了 P2P(点对点)和 CL(集体)通信模式下的原始启动延迟、可持续的单向/双向带宽、网络拓扑、通信效率和 NUMA 效应。
(二)性能评估结果
-
P2P 通信性能
-
启动延迟 :在 P100-DGX-1 和 V100-DGX-1 平台上,通过 PCIe 进行不同 GPU 对之间的通信延迟相似,表明 PCIe 在延迟方面没有 NUMA 效应。然而,NVLink 的延迟表现出显著的 NUMA 效应,直接连接的节点延迟约为 9 微秒,需要手动路由的节点延迟增加了约 2 倍(P100-DGX-1)和 3 倍(V100-DGX-1)。此外,NVLink-V2 的延迟高于 NVLink-V1,可能是因为更深的流水线或更低的工作频率。
-
可持续带宽 :在 PCIe 互连中,共享同一 PCIe 交换机的 GPU 在测量中表现出较低的带宽,这是 PCIe 的 NUMA 效应之一。对于 NVLink,带宽受拓扑结构和路由选择的影响,存在三种 NUMA 效应:邻居节点和远程节点之间的 NUMA 效应、邻居节点之间的 NUMA 效应(由于连接邻居节点的链路数量不同)以及远程节点之间的 NUMA 效应(由于路由选择不同)。NV-SLI 仅涉及两个 GPU,通信对称,没有表现出 NUMA 效应。NVSwitch 的远程访问带宽一致或呈现 UMA(Uniform Memory Access,统一内存访问)特性,表明额外的 NVSwitch 跳转不会降低带宽。
-
-
CL 通信性能
-
CL 通信延迟 :对于 NCCL-V1(PCIe/QPI)和 NCCL-V2(NVLink),随着参与 GPU 数量的增加,延迟几乎呈线性增长。NVLink 的延迟增长速度比 PCIe 快(除了 all-reduce 操作),NVLink-V2 的延迟增长速度比 NVLink-V1 快。
-
CL 通信带宽 :对于 PCIe,CL 带宽随着 GPU 数量的增加而降低,这是由于树状网络中的总线竞争。而对于 NVLink,CL 带宽随着 GPU 数量的增加而增加,这是由于超立方体网格网络中连接的链路更多。NVLink-V2 在 4 个 GPU(约 1.6 倍)和 8 个 GPU(约 2 倍)时表现出显著更好的带宽,显示出双链路和骨干环的优势。
-
(三)性能评估结论
-
NVSwitch :在大规模 GPU 集群中,NVSwitch 的性能表现最为突出,具有极高的带宽和低延迟,能够满足大规模 GPU 间通信的需求。
-
NVLink :在小规模 GPU 系统中,NVLink 的性能表现较好,具有较高的带宽和低延迟,能够满足 GPU 间通信的需求。
-
GPUDirect :在多节点集群中,GPUDirect 的性能表现优异,特别是在大消息尺寸下,能够显著提高通信效率。
-
NV-SLI :在双 GPU 系统中,NV-SLI 的性能表现稳定,能够满足图形渲染和游戏的需求。
-
PCIe :在一般的 GPU 与 CPU 之间的通信场景中,PCIe 的性能表现尚可,但在多 GPU 系统中,其性能可能受到限制。
四、GPU 互连技术对应用性能的影响
(一)对内节点规模扩展应用的影响
在内节点规模扩展场景中,评估了七个规模扩展应用在 P100-DGX-1 和 V100-DGX-1 上的表现,分别使用和未使用 NVLink。结果表明,尽管 NVLink 在微基准测试中表现出显著的 GPU 间通信效率提升,但在整体应用性能上并未直接转化为通信延迟的降低或整体应用的加速。这主要是因为大多数规模扩展应用基于主从编程模型,CPU 作为主处理器,处理顺序代码部分,GPU 作为从处理器,处理并行部分。在这种模型下,通信主要发生在 CPU 和 GPU 之间,GPU 之间的通信较少,且 CPU-GPU 通信已经高度优化。此外,使用 NVLink(无论是 P2P 还是 CL)会引入额外的开销,如启用/禁用对等访问、路由、NCCL 初始化等。
(二)对外节点规模扩展应用的影响
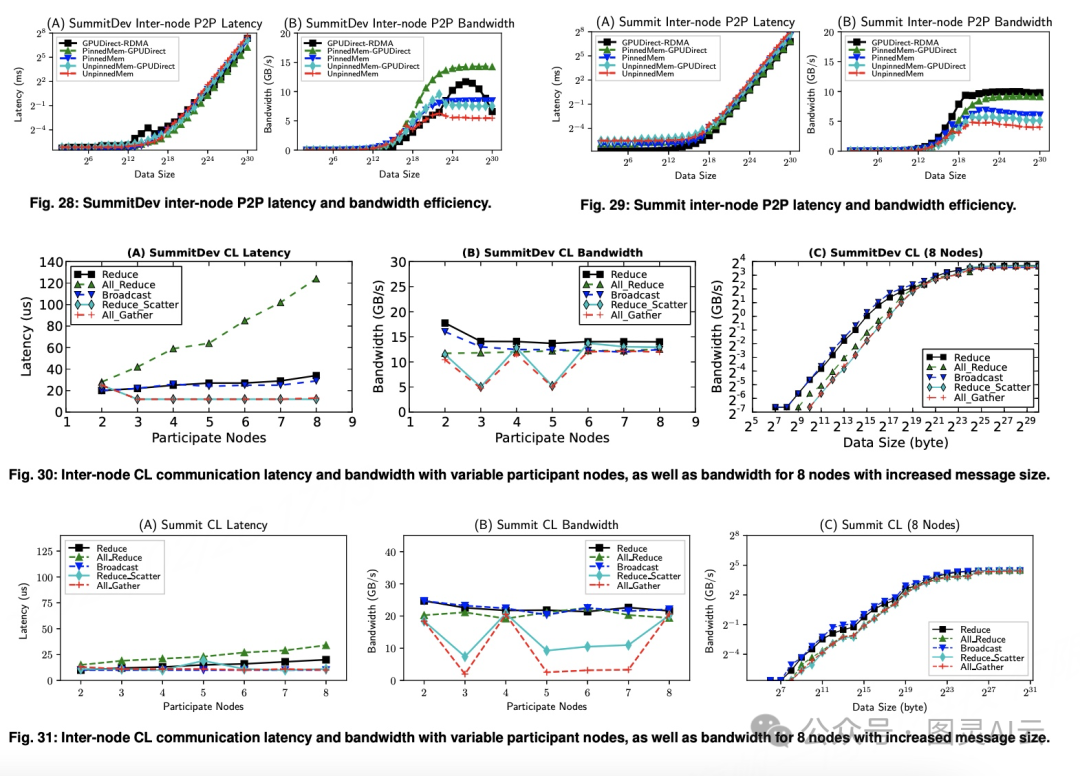
对外节点规模扩展场景中,在 SummitDev 和 Summit 上运行了七个规模扩展应用,分别使用了五种配置:GPUDirect-RDMA、PinnedMem-GPUDirect、PinnedMem、UnpinnedMem-GPUDirect 和 UnpinnedMem。结果表明,与内节点快速互连相比,MPI 基的外节点规模扩展应用在强规模扩展和弱规模扩展测试中都表现出更好的扩展性,这表明外节点网络更容易成为系统瓶颈。提高外节点网络速度可以为多 GPU 应用带来显著的性能提升。对于 SummitDev,GPUDirect-RDMA 在某些应用中表现出最差的性能,但在 Summit 上,GPUDirect-RDMA 在所有配置中表现出最佳性能,特别是在小消息尺寸下的延迟最低,在大消息尺寸下的带宽最高。
五、结论与展望
本文通过对六种现代 GPU 互连技术的深入评估,揭示了它们在性能和应用中的特点。NVSwitch 在大规模 GPU 集群中表现出卓越的性能,NVLink 在小规模 GPU 系统中具有较好的性能,而 GPUDirect 在多节点集群中能够显著提高通信效率。然而,要充分发挥这些互连技术的性能优势,还需要在编程模型、通信模式和性能优化等方面进行进一步的研究和探索。
未来的研究方向包括开发新的多 GPU 编程模型,以更好地适应现代 GPU 互连技术的特点;构建实用的多 GPU 性能模型,为应用开发和性能调优提供指导;以及开发新的通信模式和库,以更好地匹配底层互连技术,实现高性能通信。通过这些研究,有望为多 GPU 应用的性能提升提供更有力的支持,推动高性能计算和人工智能等领域的发展。
参考文献:
-
https://arxiv.org/pdf/1903.04611
-
https://developer.aliyun.com/article/1606345
-
https://www.nvidia.com/en-us/data-center/nvlink/
-
https://www.electronicshub.org/nvlink-vs-sli/
-
https://www.nextplatform.com/2018/04/13/building-bigger-faster-gpu-clusters-using-nvswitches/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









