







本文主要讲解Prometheus 配置过程,Grafana安装请转移此文档。
平台
架构图
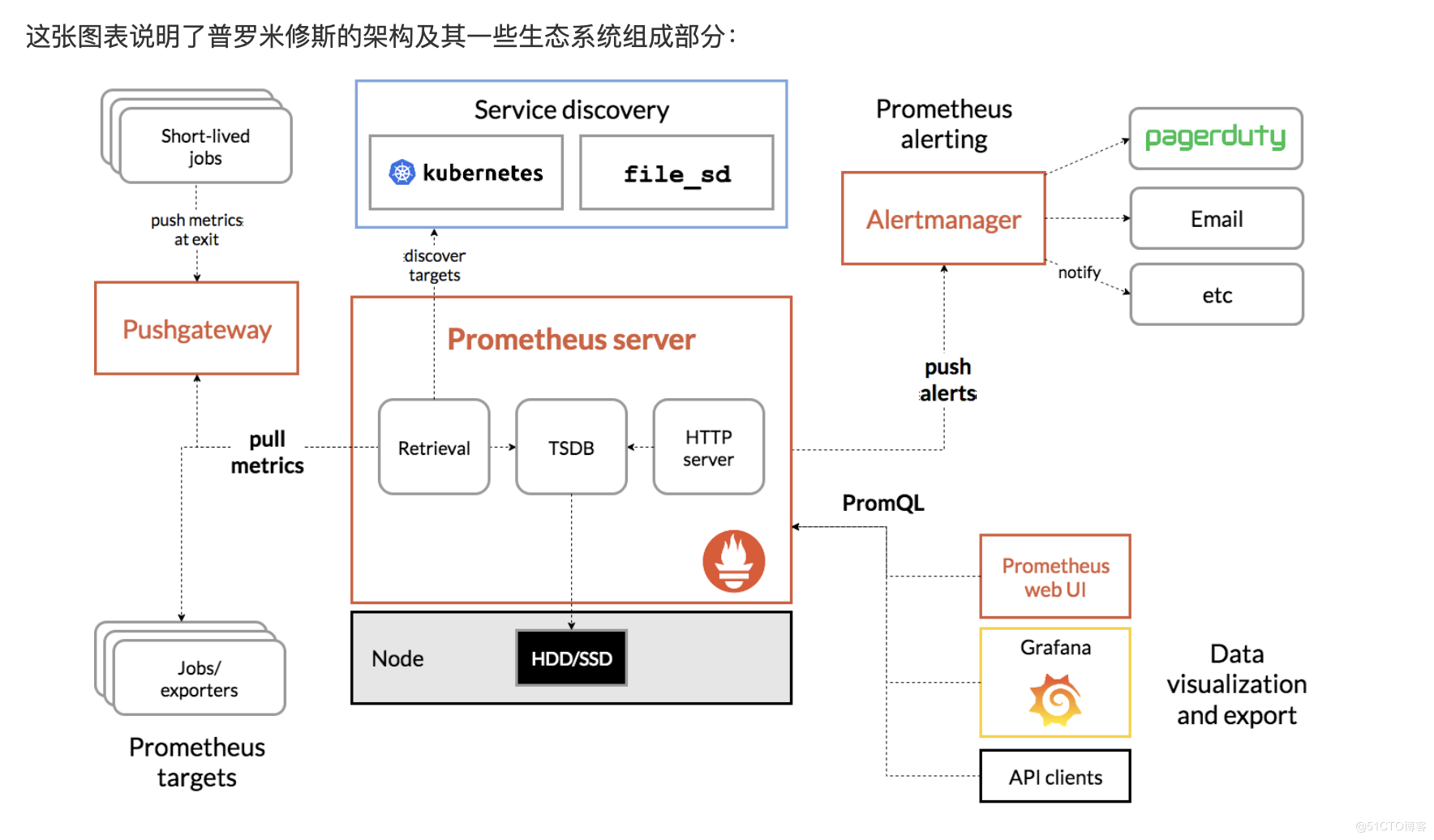
Prometheus服务大致过程:
- Prometheus 定时去目标上抓取metrics(指标)数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。Prometheus支持通过配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目标。Prometheus采用PULL的方式进行监控,即服务器可以直接通过目标PULL数据或者间接地通过中间网关来Push数据。
- Prometheus在本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中。
- Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。
- PushGateway支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
- Alertmanager是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。
- Prometheus 支持通过SNMP协议获取mertics数据.通过配置job,利用snmp_export读取设备监控信息.
指标(Metric)类型
- Counter 计数器,从数据0开始累计计算. 理想状态会永远增长. 累计计算请求次数等
- Gauges 瞬时状态的值. 可以任意变化的数值,适用 CPU 使用率 温度等
- Histogram 对一段时间范围内数据进行采样,并对所有数值求和与统计数量、柱状图. 某个时间对某个度量值,分组,一段时间http相应大小,请求耗时的时间。
- Summary 同样产生多个指标,分别带有后缀_bucket(仅histogram)、_sum、_count
Histogram和Summary都可以获取分位数。
通过Histogram获得分位数,要将直方图指标数据收集prometheus中, 然后用prometheus的查询函数 histogram_quantile()计算出来。 Summary则是在应用程序中直接计算出了分位数。 Histograms and summaries中阐述了两者的区别,特别是Summary的的分位数不能被聚合。
注意,这个不能聚合不是说功能上不支持,而是说对分位数做聚合操作通常是没有意义的。 LatencyTipOfTheDay: You can’t average percentiles. Period中对“分位数”不能被相加平均的做了很详细的说明:分位数本身是用来切分数据的,它们的平均数没有同样的分位效果。
主要我们监控用到最上面两种,下面两种类型目前我没有接触,上面这段文字与介绍引用自lijiaocn
安装Prometheus
本次搭建利用docker方式.整体搭建完成需要两个容器.暂不配置告警相关,只做监控数据
- Centos7上安装docker:https://blog.51cto.com/qiangsh/2167309
# 安装需要的软件包
[root@opserver ~]# sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# 设置yum源
[root@opserver ~]# sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 更新 yum 缓存:
[root@opserver ~]# sudo yum makecache fast
# 指定版本安装
[root@opserver ~]# sudo yum install docker-ce-19.03.9-3* docker-ce-cli-19.03.9-3*
# 查看版本信息
[ root@opserver:~ ]# docker version
Client: Docker Engine - Community
Version: 19.03.9
... ...
# 启动docker服务
[ root@opserver:~ ]# sudo systemctl start docker
[ root@opserver:~ ]# sudo systemctl enable docker
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.- 准备工作
我们来编写Docker Compose脚本,需要映射9090端口,另外建议把配置文件”prometheus.yml”挂载出来
[ root@opserver:/ ]# cd /data/app
[ root@opserver:/ ]# touch docker-compose-monitor.yml编写 docker-compose-monitor.yml:
version: '2'
networks:
monitor:
driver: bridge
services:
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
restart: always
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus/node_down.yml:/etc/prometheus/node_down.yml
ports:
- "9090:9090"
networks:
- monitor
alertmanager:
image: prom/alertmanager
container_name: alertmanager
hostname: alertmanager
restart: always
volumes:
- ./prometheus/alertmanager.yml:/etc/alertmanager/alertmanager.yml
ports:
- "9093:9093"
networks:
- monitor
#grafana:
# image: grafana/grafana
# container_name: grafana
# hostname: grafana
# restart: always
# ports:
# - "3000:3000"
# networks:
# - monitor
node-exporter:
image: quay.io/prometheus/node-exporter
container_name: node-exporter
hostname: node-exporter
restart: always
ports:
- "9100:9100"
networks:
- monitor
cadvisor:
image: google/cadvisor:latest
container_name: cadvisor
hostname: cadvisor
restart: always
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- "8080:8080"
networks:
- monitor- 创建一个标准的配置文件Prometheus.yml,内容如下:
建立在搭建位置的根下: touch prometheus.yml
[ root@opserver:/ ]# mkdir /data/app/prometheus
[ root@opserver:/ ]# cd /data/app/
[ root@opserver:/ ]# touch prometheus/prometheus.yml
在配置文件中加入测试演示配置
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_timeout: 10s # scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "node_down.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
honor_timestamps: true
scrape_interval: 5s
scrape_timeout: 3s
# metrics_path defaults to '/metrics'
metrics_path: /metrics
# scheme defaults to 'http'.
scheme: http
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
- job_name: 'cadvisor'
static_configs:
- targets: ['10.10.10.10:8080'] # 填写外部服务器ip,或者填写容器内部ip
- job_name: 'node'
scrape_interval: 8s
static_configs:
- targets: ['10.10.10.10:9100'] # 填写外部服务器ip,或者填写容器内部ip
labels:
instance: pms-server注意配置文件的格式为yaml,语法问题请参考这里
- 添加邮件告警配置文件
[ root@opserver:/ ]# touch /data/app/prometheus/alertmanager.ymlvim alertmanager.yml
global:
smtp_smarthost: 'smtp.163.com:25' #163服务器
smtp_from: 'tsiyuetian@163.com' #发邮件的邮箱
smtp_auth_username: 'tsiyuetian@163.com' #发邮件的邮箱用户名,也就是你的邮箱
smtp_auth_password: 'TPP***' #发邮件的邮箱密码
smtp_require_tls: false #不进行tls验证
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: monitoring
receivers:
- name: 'monitoring'
email_configs:
- to: 'qsh_1992@163.com' #收邮件的邮箱- 添加报警规则
[ root@opserver:/ ]# touch /data/app/prometheus/node_down.ymlvim node_down.yml
groups:
- name: node_down
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
user: test
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."- 启动服务
# 安装docker-compose
[ root@opserver:~ ]# yum install -y epel-release
[ root@opserver:~ ]# yum install -y docker-compose# 启动容器:
docker-compose -f /data/app/docker-compose-monitor.yml up -d
# 删除容器:
docker-compose -f /data/app/docker-compose-monitor.yml down
# 重启容器:
docker restart <id>














 2073
2073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









