







一、分类概述
在大数据挖掘中,分类是一种关键的分析任务,它通过将数据集中的样本分配到预定义的类别中,帮助我们从大规模数据中提取有价值的信息。
更具体的说明: ① 分类是根据以往的数据和结果对另一部分数据进行结果的预测。 ② 模型的学习在被告知每个训练样本属于哪个类的“指导” 下进行新数据使用训练数据 集中得到的规则进行分类。
分类也是大数据挖掘技术中的一种重要方法。
可以将其分成两个阶段。
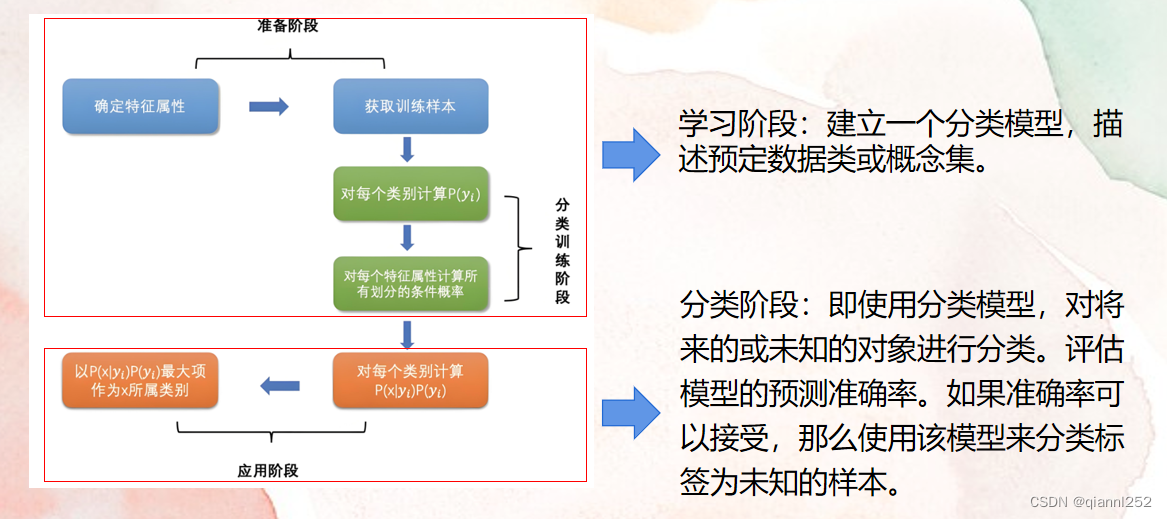
二、朴素贝叶斯分类
朴素贝叶斯具有以下的特性,因此是贝叶斯分类中的一种重要任务。
简单高效:朴素贝叶斯算法基于贝叶斯定理,并假设特征之间是条件独立的。尽管这种假设在现实中可能不完全成立,但它使得算法计算简单、速度快,适合处理大规模数据集。 处理高维数据:朴素贝叶斯能够有效处理高维数据,即数据集中的特征数量很大时,它依然可以表现良好。这在文本分类和垃圾邮件检测等领域尤为重要。 稳健性强:尽管其假设较为简单,但在许多实际应用中,朴素贝叶斯分类器往往能取得令人惊讶的好结果。其稳健性使得它成为一个强大且可靠的分类工具。 易于解释:朴素贝叶斯分类器的输出是概率分布,这样有助于理解模型的决策过程,便于解释和分析。 适用范围广:朴素贝叶斯算法广泛应用于文本分类(如垃圾邮件过滤、情感分析)、医疗诊断、推荐系统等多个领域。
那么什么是贝叶斯分类呢?举个例子
设X是一个类标号未知的数据样本,H表示一个假设:数据样本X属于某个特定的类C。要求确定P(H|X),即给定观测数据样本X的情况下假设H成立的概率。
例如, X是一位35岁的顾客,其收入为4万美元。令H为某种假设,如顾客将购买计算机。 P(H|X)是后验概率 例如, 顾客X将购买计算机的概率。 P(H) (prior probability)是先验概率 例如, 顾客将购买电脑的概率, 无论年龄和收入等等。 P(X)是X的先验概率 例如,顾客集合中年龄为35岁且收入为4万美元的概率 P(X|H)是后验概率 例如,已知顾客X将计算机,该顾客是年龄为35岁,收入为4万美元的概率。
可以清晰直观的看出两者关系。
具体公式:如下

 朴素贝叶斯过程分类算法的具体步骤:
朴素贝叶斯过程分类算法的具体步骤:
输入: 数据集S是训练元组和对应类标号的集合; 待分类的数据X 输出:数据X所属的类别 方法: 根据数据集S计算每个类别Ci的先验概率P(Ci)。 根据数据集S计算各个独立特征X(j)在分类中的条件概率p(X(j)|Ci)。 对于特定的输入数据X,计算其相应属于特定分类的条件概率p(Ci|X)。 选择条件概率最大的类别作为该输入数据X的类别返回。
三、朴素贝叶斯分类过程具体案例
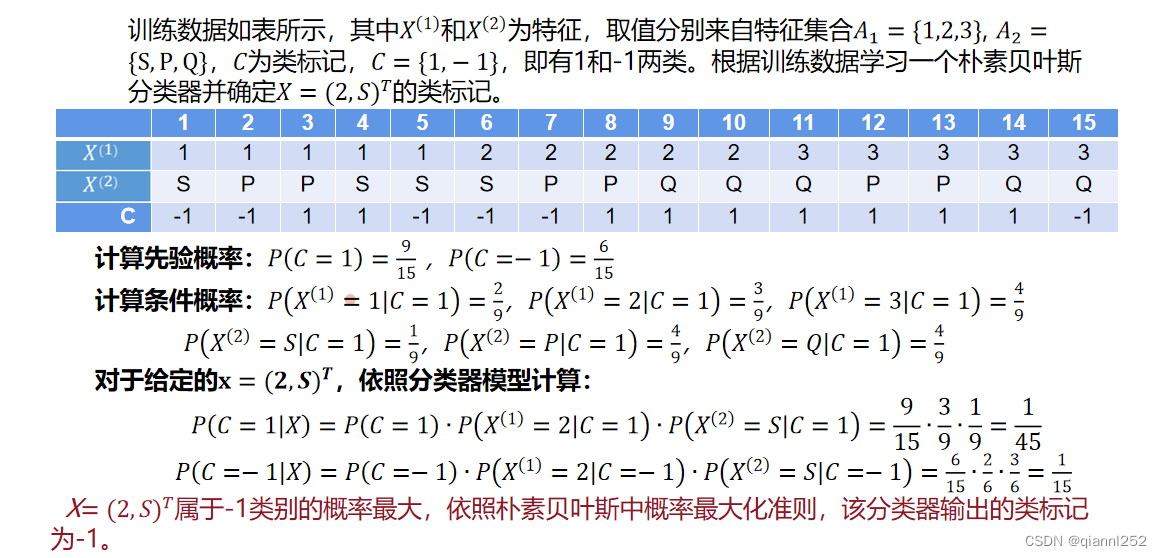
具体分析这道题目呢,题目要求根据训练数据学习一个朴素贝叶斯分类器并确定X=(2,S)^T的类标记。
如何使用朴素贝叶斯分类器来预测给定实例𝑥=(2,𝑆)𝑇的类标记。朴素贝叶斯分类器是基于概率的分类器,它通过计算后验概率𝑃(𝐶∣𝑋)来决定一个实例𝑥应该被分配到哪个类别𝐶。在这个问题中,有两个类别:𝐶=1和𝐶=−1。
为了计算后验概率𝑃(𝐶∣𝑋),我们需要使用贝叶斯定理,它表达了后验概率与先验概率和条件概率之间的关系:
𝑃(𝐶∣𝑋)=𝑃(𝑋∣𝐶)⋅𝑃(𝐶)𝑃(𝑋)
在这个特定的问题中,我们不需要计算分母𝑃(𝑋),因为我们只关心比较不同类别的后验概率的大小,而不是它们的绝对值。因此,我们可以简化为:
𝑃(𝐶∣𝑋)∝𝑃(𝑋∣𝐶)⋅𝑃(𝐶)
这里的∝∝表示成比例。
接下来,我们需要计算条件概率𝑃(𝑋∣𝐶)P(X∣C。由于特征是独立的(朴素贝叶斯的假设),我们可以将𝑃(𝑋∣𝐶)分解为每个特征的条件概率的乘积:
𝑃(𝑋∣𝐶)=𝑃(𝑋(1)∣𝐶)⋅𝑃(𝑋(2)∣𝐶)
对于给定的实例𝑥=(2,𝑆)𝑇,我们需要计算两个后验概率𝑃(𝐶=1∣𝑋)和𝑃(𝐶=−1∣𝑋)。这些概率是通过将先验概率𝑃(𝐶)与条件概率𝑃(𝑋(1)∣𝐶)和𝑃(𝑋(2)∣𝐶)相乘得到的。
具体计算如下:
-
对于类别𝐶=1:
- 先验概率:𝑃(𝐶=1)=9/15
- 条件概率:𝑃(𝑋(1)=2∣𝐶=1)=3/9,𝑃(𝑋(2)=𝑆∣𝐶=1)=1/9
- 后验概率:𝑃(𝐶=1∣𝑋)∝9/15⋅3/9⋅1/9=1/45
-
对于类别𝐶=−1C=−1:
- 先验概率:𝑃(𝐶=−1)=6/15
- 条件概率:这里需要知道当𝐶=−1时,特征𝑋(1)=2和𝑋(2)=𝑆的概率,这些值在题目中没有直接给出,但我们可以假设它们分别为2/6和3/6(根据训练数据得出)。
- 后验概率:𝑃(𝐶=−1∣𝑋)∝6/15⋅2/6⋅3/6=1/15
最后,我们比较两个后验概率𝑃(𝐶=1∣𝑋)P和𝑃(𝐶=−1∣𝑋),并选择具有最大后验概率的类别。在这个例子中,𝑃(𝐶=−1∣𝑋)大于𝑃(𝐶=1∣𝑋),所以分类器将实例𝑥=(2,𝑆)𝑇分类为类别−1。















 2398
2398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









