






原文:One Model At A Time: Integrating And Running Deep Learning Models In Production At EyeEm
作者:Michele Palmia
译者:夜风轻扬
译者注:如果你对如何在公司产品中引入和运用深度学习模型有浓厚的兴趣,下文也许会给你带来一些帮助。
三年来,我们一直在EyeEm公司开发计算机视觉产品-这些产品处理数十亿的图片。作为一个从零起步在幕后从事底层开发的工程师,这项工作带来的技术挑战让我痛并快乐着。这段经历让我收获很多:学会如何管理开发过程、处理与不同团队的关系尤其是完成初创公司中充满挑战性的工作。
下文对EyeEm计算机视觉产品的发展历史做一个梳理,其中既有不得不面临的挑战、开发中获得的经验也有对未来的展望。
为的照片做索引
当我三年前加入EyeEm时,目标是为了开发一个搜索引擎,帮助用户搜索公司完整的目录图片。方法就是对图像做标记并打分-当时图像库中有6千万张图片,并且还在快速增长中,做索引能够帮助用户方便查找图片。这就是AI疯狂的开始:初出茅庐,非常兴奋又忐忑不安。
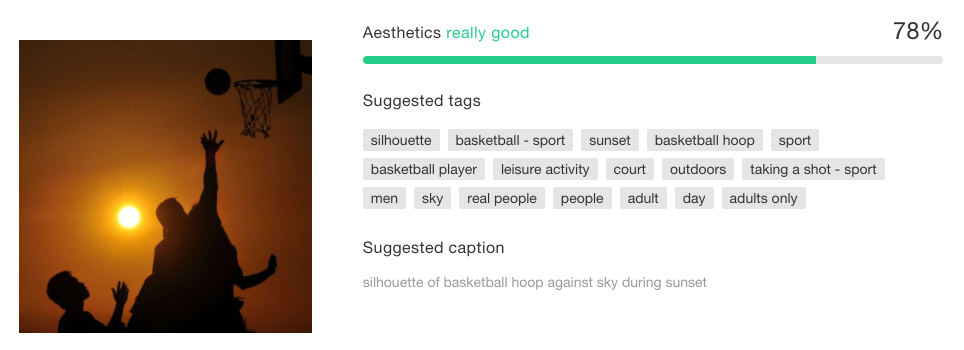
任务的目标是为每一张图片颜值打分并进行分类。后来又增加了给图片加标题功能。
团队结构
搜索项目由一个多功能团队负责。管理员选择图片,研究人员开发打分和标记算法。工程师则将这些集成到搜索引擎中,并要求其底层架构具有扩展性。
对于初创的公司来说,大量的新项目都是同时开始。在这个阶段,一个团结的工程师团队会让每人获益。各司其职的方法有助于更有效分享知识、更轻松复用组件、并且创建以有效的工程文化。
这两个各自独立团队的作用和责任始终如一:
- 研发团队开发自包含的机器学习模型,模型接收简单的输入,一般是张图片,返回一个简单输出,例如打分的分值或者是一列标记。这些模型包装在Python API中,模型还定义了必要的预处理步骤和最终的后处理过程。每一个算法都做了严格版本控制。主版本号标识模型的更新,次版本号标识包装的Python代码更新。
- 核心工程师团队接收研发团队的工作成果,通过知识交流和交付品评估,设计开发代码以及大规模运行模型的底层设施。通常只有在主版本更新时,才需要进行复杂的知识交流,一般都是团队成员直接交流。
知识交流一般通过非常轻量级的检查清单形式,其中包含输入和输出的格式,尤其是对以前版本的更改、应用和硬件需求、以及测试的覆盖。这一般都是研发人员和工程师直接交流,只有在输出发生大规模更改,影响内部或者用户界面特性时才会提高交流的等级。
横向交流合作值得信任:
“交流是为了用最快的方式解决问题以使公司获益。”
开始工作
设计的第一个系统是给EyeEm库中及新流入的图片进行分类打分。
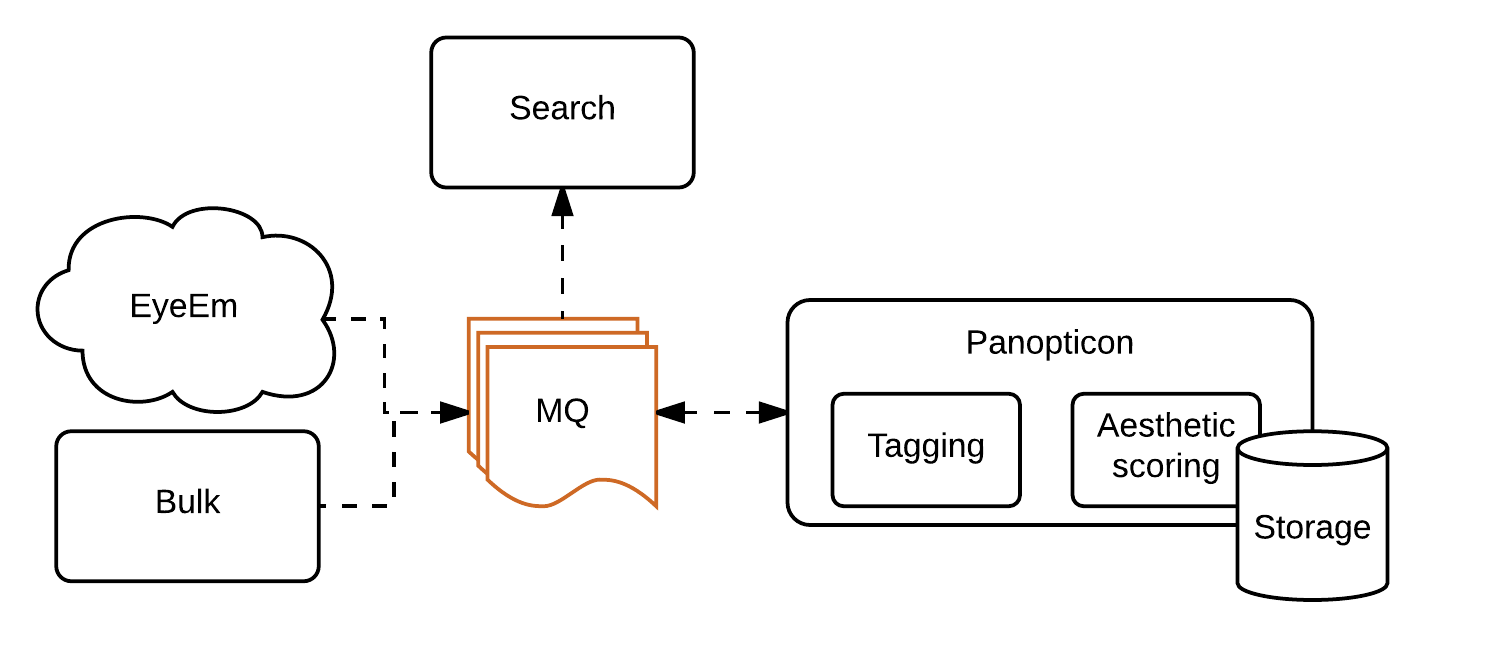
像很多初创公司一样,在从开发单一应用起步后,公司开始转向分布式架构。新的服务称为Panopticon,该名字来源于18世纪的一种单看守监狱。

Panopticon的作用是从一队列中读入包含上载图片ID的信息,对原始图片进行归纳,存储结果并发送给搜索系统,这样逐一在所有的队列上进行标记和打分。
研发团队决定使用的框架是Caffe。团队具备Python经验,知道如何编写服务。Python支持该项目中所需要的快速迭代。RabbitMQ 已经作为消息系统在使用, Cassandra似乎非常适合于需要永久存储的数据-既不要删除,只通过ID不要扫描就可以进行访问。运行研发部门开发的深度学习算法,需要亚马逊的GPU平台,这由一个简单的自动扩展功能组来管理。至于公司其他的基础设施,使用Chef进行管理。
因为Panopticon是基于队列的,最简单的方法是根据id逐次处理大批量图片集。为了保存来自于互相隔离不同模型的结果,机器需要配置输入不同的模型、接入不同的队列。
一时涌现了大量的问题。虽然从中学到了不少经验,但是依然有一些基础问题难以解决:
- GPU 平台非常昂贵。 承载API的平台每小时花费低于 0.4,亚马逊最便宜的GPU平台每小时的花费是 0.7。
- 幸运的是,有更多的资源可以在GPU平台上部署容器并因此降低成本,但是这在公司初创的时候是不具备的-并且即使现在使用起来也不容易。
- 输入及其预处理和后处理过程都是长CPU操作;
- 一个GPU一次只能处理一个输入(或者批量输入)。应用只能等一个处理结束才能处理下一个。在执行长CPU操作时,GPU这种昂贵的资源在大量的空闲等待中浪费了;
- 使用有限的资源来批量处理数以亿计的图片是很困难的;
- 在发布/订阅模式下,消息输入节奏要和使用节奏严格匹配。在客户机/服务器模式下,服务器池要超过单个客户的能力。一般来说,扩展能力会突破各种潜在的瓶颈。
按照不同的需求来变换不同模型也是困难的。
后文会讨论到,品质评分模型的输出格式至少更改了四次,需要对输出多做研究。
走进 The Roll
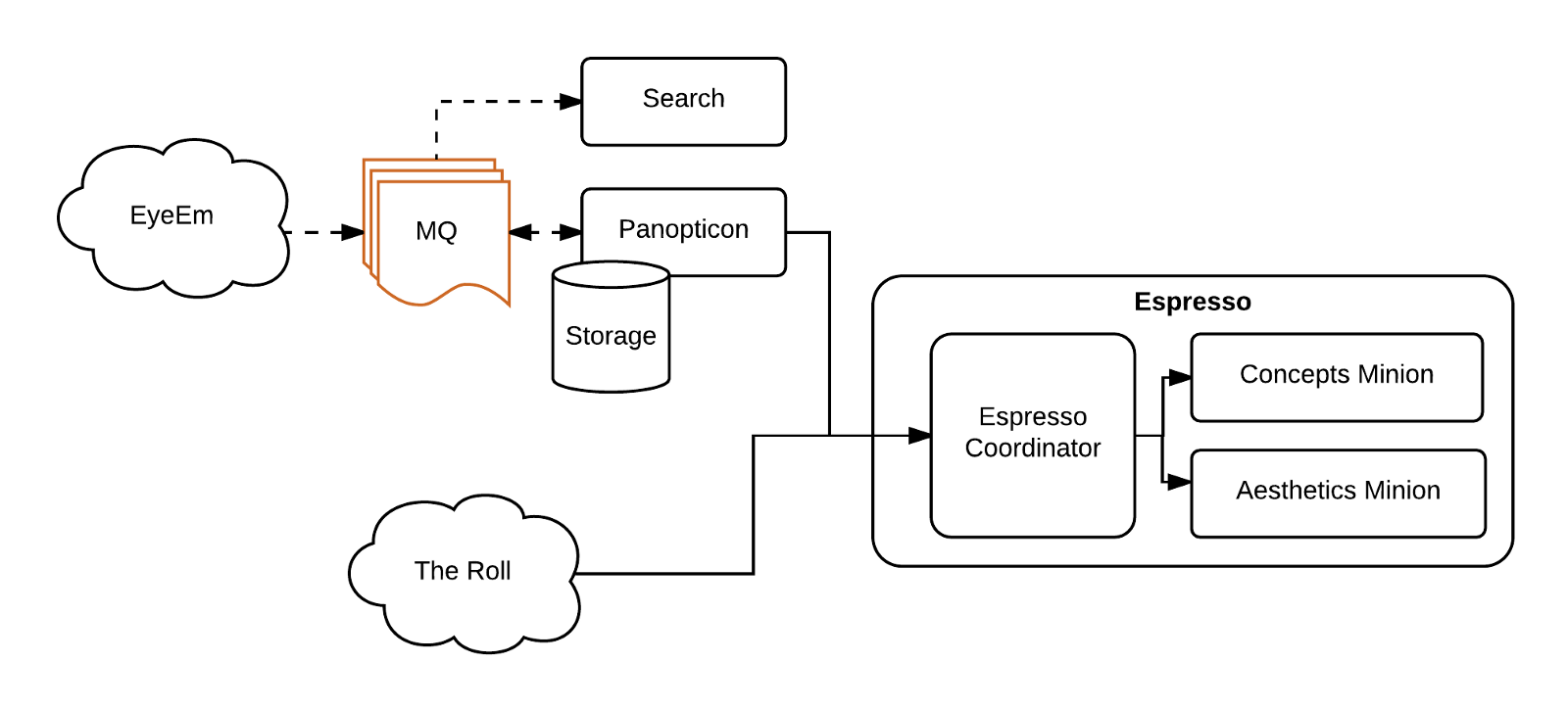
Panopticon运行良好,但只用来处理 EyeEm的图片。 接下来是开发The Roll,一个帮助用户组织和查找照片的iOS应用。这款应用对整个相册进行打分和分类,与EyeEm库没有任何关系。这个新项目需要开发一个平台无关的系统,可以利用现有模型里处理任何输入的图片。在短暂的头脑风暴会后,给系统取了一个非常有创意和合适的名字:Espresso!,该系统包含了基于Caffe的模型。
Espresso是EyeEm产品中单独的也是唯一的推理系统,对Panopticon快速进行重构,不是运行模型,而是使用模型。在Espresso上进行快速迭代,以修复在Panopticon中发现的问题,并注意调整新出现的问题。
- 从一开始就在Espresso中实现了看守机制,至少为客户赢得了微弱的响应时间。
- 允许每一个深度学习模型都可以定义独立需求,并且可以运行在独立的虚拟环境中,这样可以确保研发团队可以为不同的模型使用不同的框架。Keras和Tensorflow即将到来。
- 可以使用以前没有的批处理
会在随后的段落中详细讨论上述每一项。
看守机制
Panopticon(EyeEm特有的)与 Espresso 的一个显著差别是中间件。前者API是基于队列,后者则完全依赖HTTP。 panopticon不必急于处理传入的图片,而Espresso需要迅速进行回复-这就是队列的好处。模型也成长很快。
一个GPU可以一次处理一张或者一批图片,时间大约为几百毫秒。除非有多个GPU否则需要顺序处理每一个请求。当收到大规模请求时,不能让这些请求无限制堆积起来,这就需要确保给用户合理的响应时间。
Espresso有一个非常简单的看守机制。需要设置在特定时间内能够接受的最大请求数。超过这一门限值后的请求会返回HTTP 429错误(过多请求)。如果门限值设为10,当应用在短时间内收到了11条请求时,前10条请求会进入到队列中,第11条请求会被丢弃。
如果进行标记的时间是大约500毫秒,看守门限值设为10,那么可以保证响应时间为5秒。尽管这是一个弱保证,但是对于客户这已经足够了

The Roll的推出是成功的。可以监控到请求的数量是平稳增长的,只要429错误增加就会启动新的机器来均衡负载。在应用发布后的几天里,每秒平均能处理上千张图片。
在The Roll发布的几个月里,这一切都工作正常。
隔离研发代码
最初,研发团队开发的所有模型都封装在一个单独的Python库中,先后用在Panopticon和Espresso中。在推出The Roll的时候,我们意识到模型的需求开始改变,需要底层设施提供支持。
舍弃Caffe转而使用 Theano (和Keras,以及Tensorflow),这样就需要每个模型在其虚拟环境中运行,并按照正确的需求进行初始化。这也意味着不能在每台GPU机器上运行单一的Python应用:每个模型运行单一的Python进程,但是仍然需要为客户提供与以前API一致的接口。单独包装每个模型是很繁琐的,但是必须重新设计架构以支持这种转变。
Espresso 协调者
保持各种可操作性意味着需要更高的兼容性,舍弃在每台GPU机器的单一进程运行中多个模型的方案,而是采用一个Python进程运行一个模型,这称为minion。Minion与以前的Espresso运行一样的代码,但是不提供多个输出,只服务单一输出。这就需要开发新的协调者应用,来查询minion,合并它们的响应,为客户提供一致的API。该协调者应用有一个名字叫 Espresso杯(为了明确,还称其为协调者)。
批处理与扩展
在GPU上执行推理的最快方式,是把多个输入合并为单个批处理传入到模型中,而不是多次单独进行运算。例如,如果单个推理花费的时间是500ms,两张图片合并批处理的时间是800ms,那么同时批处理的照片越多,效率越高。在处理管道中,来自于不同请求的图片合在一起进行批处理,处理的结果又进行分离,各自进行响应。
在The Roll的第一次迭代时,批处理交给负责The Roll API的机器,“first line”作为 Espresso的客户,接收来自用户的请求。系统收到用户的第一条新请求时,就会生成一个新的批处理。在设定的超时前,请求会添加到新的批处理中,如果超时,就直接发送出去:API越繁忙,批处理的规模越大越有效率。
The Roll API作为Espresso的客户,以批处理方式进行工作,对于固定数量的Espresso机器,批处理的规模只取决于公共API机器的数量。如果来自用户的两张照片同时到达,而只有一台API机,就会创建一个单一批处理,而不管Espresso服务多少机器。另一方面,如果让服务器承担批处理任务,那么批处理取决于处理能力。如果两张照片同时到达,而只有一台Espresso机,就进行批处理,如果有两台Espresso机,则同时分别进行处理。
批处理一般只出现在处理过程的最后阶段。
成长的家族
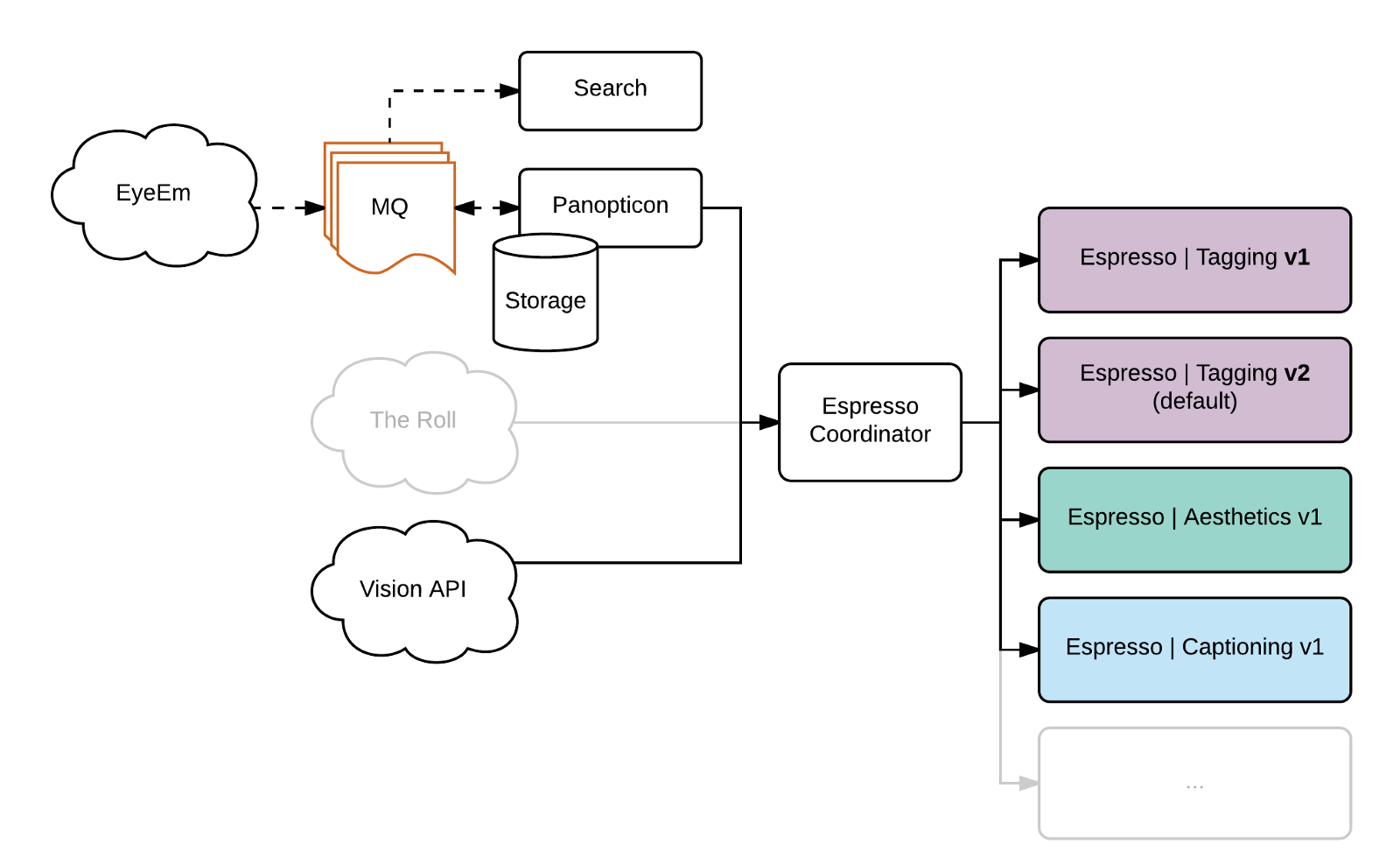
The Roll只是昙花一现,其很多特点随后都集成到EyeEm应用中。但是,新版本的分类和评分模型还是不断出现,更为重要的是,新的业务目标需要完全崭新的模型。
2017年初,在成熟的分类和评分模型之上,又产生了标题模型,内部相片品质模型和个人化评分系统,该系统中引入了人物提取器、个人化训练模型和打分模型。在单台机器上运行多个模型,这不得不需要在GPU上进行顺序处理,这会增加总的响应时间。并且,GPU内存也太繁忙,需要减少批处理的规模。
在需要数月的迁移过程中,我们决定:
- 允许相同模型的不同版本运行在相同的堆栈上-客户端必须为模型指定一个版本,或者只是请求一个默认值;
- 使用一个模型一台机器,极大简化底层设施的管理,并且允许单个minion的独立扩展;
- 把预处理转移到独立的服务器上,避免CPU任务占据GPU机器;
- 在minion上,尽可能少的执行批处理,以保证最好的资源使用率。
前进的道路
当每天都要处理如此多的系统问题时,难以把注意力集中在高级架构上。努力寻求统一的有机方法来处理新的和已有的模型,在上游研发部门和下游用户间游刃有余,与紧迫的时间表和如影随形的bug做斗争。然而,我相信每一个参与构建产品的人都会为我们取得的成就感到自豪。我希望所有负责巩固和发展这一系统的团队成员也会享受这一挑战。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









