






更多内容关注微信公众号:fullstack888
背景
为了封禁某些爬虫或者恶意用户对服务器的请求,我们需要建立一个动态的 IP 黑名单。对于黑名单之内的 IP ,拒绝提供服务。
架构
实现 IP 黑名单的功能有很多途径:
1、在操作系统层面,配置 iptables,拒绝指定 IP 的网络请求;
2、在 Web Server 层面,通过 Nginx 自身的 deny 选项 或者 lua 插件 配置 IP 黑名单;
3、在应用层面,在请求服务之前检查一遍客户端 IP 是否在黑名单。
为了方便管理和共享,我们选择通过 Nginx+Lua+Redis 的架构实现 IP 黑名单的功能,架构图如下:

实现
1、安装 Nginx+Lua模块,推荐使用 OpenResty,这是一个集成了各种 Lua 模块的 Nginx 服务器:

2、安装并启动 Redis 服务器;
3、配置 Nginx 示例:
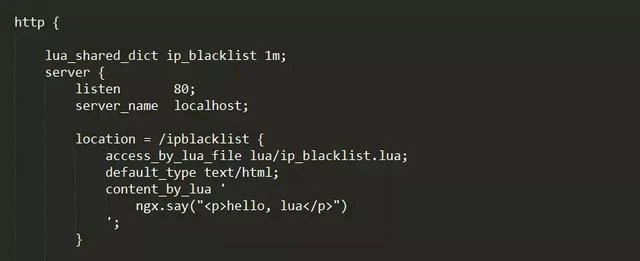
Nginx 配置
其中
lua_shared_dict ip_blacklist 1m;由 Nginx 进程分配一块 1M 大小的共享内存空间,用来缓存 IP 黑名单。
access_by_lua_file lua/ip_blacklist.lua;指定 lua 脚本位置。
4、配置 lua 脚本,定期从 Redis 获取最新的 IP 黑名单。

5、在 Redis 服务器上新建 Set 类型的数据 ip_blacklist,并加入最新的 IP 黑名单。
完成以上步骤后,重新加载 nginx,配置便开始生效了。这时访问服务器,如果你的 IP 地址在黑名单内的话,将出现拒绝访问,如下图:

总结
以上,便是 Nginx+Lua+Redis 实现的 IP 黑名单功能,具有如下优点:
配置简单、轻量,几乎对服务器性能不产生影响;
多台服务器可以通过Redis实例共享黑名单;
动态配置,可以手工或者通过某种自动化的方式设置 Redis 中的黑名单。
- END -
往期回顾

技术交流,请加微信: jiagou6688 ,备注:Java,拉你进架构群

















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









